












1.项目背景
公司集群上千物理节点,存储容量100PB+,当前使用50PB左右,YARN的计算内存150Tb+,CPU 30000 Cores+。当前使用的CDH集群,因为性能瓶颈,需要迁移到自建的apache Hadoop3集群。CDH集群默认的是Fair Scheduler,Ambari(Hortonwork)默认使用Capacity Scheduler。CDH和HDP合并后,新的CDP会默认使用Capacity Scheduler调度器。所以如果需要将CDH群集迁移到CDP时,必须从Fair Scheduler迁移到Capacity Scheduler。迁移过程包括在迁移之前自动将某些Fair Scheduler配置转换为Capacity Scheduler配置,并在迁移之后进行手动微微调。
目前Hadoop3.x默认使用的是Capacity Scheduler,并且Capacity Scheduler支持了Node Labels机制,即通过给节点打标签的形式,让不同队列使用不同的标签节点进而更好地做计算资源隔离和资源保障。目前大公司来说使用Capacity Scheduler和Fair Scheduler的公司都有很多。至于FIFO调度器在生产上的使用几乎可以忽略不计。对于一家公司,中型集群规模的话,到底是选择Capacity Scheduler还是Fair Scheduler呢?从配置使用友好度,日常管理,生产上资源分配,拓展,实际使用经验等多个维度去考核对比一下两者的联系
2.Fair Scheduler和Capacity Scheduler的调研
现在随着hadoop3的更新,Fair Scheduler和Capacity Scheduler的功能性越来越同质化,相近。但是两者的之所以没有合并或者湮没一家,是因为本质上还是不同,都有一些自己的特质与特定的功能,在不同方向发挥着自己的余热。下面基于其重要的特性做了一些对比。
编号 | 比较类别 | Fair Scheduler | Capacity Scheduler |
1 | 是否支持多租户的使用 | 支持 | 支持 |
2 | 是否支持多队列的资源管理,支持队列的树状结构以及子队列 | 支持 都可以配置多个父队列,每个父队列下多个子队列 同一个父队列下的子队列资源分配值加起来可以不等于父队列,这样有利于提高父队列的资源利用率。但是实际使用最大小值会受父类的限制。 | 支持 都可以配置多个父队列,每个父队列下多个子队列 同一个父队列下的同一级别的子队列Capacity之和必须为100,比较麻烦。 |
3 | 支持队列的最小资源保障 | 支持 可以配置队列的最小资源,旧的格式支持固定值,新的配置格式支持百分比;vcores = X,memory-mb = Y”或“ vcores = X%,memory-mb = Y%。 同一级别的容量之和加起来可以超过100% 分配文件必须为XML格式 | 支持, 默认配置百分比值或者小数 同一级别队列的容量总和必须100或者100% 比如30,表示占父队列的资源总和的30%。 尖叫提示: 不管是Fair Scheduler和Capacity Scheduler,如果当前队列没有任务提交时,是不会分配最小资源的,这个时候不保障最小资源,都是0。 如果该队列有任务提交时,需要等待当前集群释放资源时,才会分配满足最小资源的保证。也就说只有有任务跑时才会满足最小资源。 注意:当一个队列多个用户提交使用时,只保证整个队列的最小资源使用,不保证每个用户是否能有最小资源保证 默认资源分配都是以内存为调度单位的,但都支持CPU+内存 |
4 | 支持队列的最大资源限制 | 支持 配置格式同上,最小资源保障的配置。 尖叫提示:不管是Fair Scheduler和Capacity Scheduler队列的最大资源限制是队列可以使用的资源最大值,无论如何都不会超过这个值。 同样,如果父队列有最大值的限制,则子队列使用的资源总和不会超过父队列的最大值。也说明了每个用户的最大资源使用是有限制的。 | 支持, 默认配置百分比值或者小数 同一级别队列的容量总和必须100或者100% 比如30,表示占父队列的资源总和的30%。 |
5 | 队列之间资源共享与抢占 | 支持 当集群中有队列资源空闲时,其他供其他队列抢占使用,这是FS的重要特质 | 支持 当集群中有队列资源空闲时,其他供其他队列抢占使用,CP的抢占管理更加精细化,相比配置也更加麻烦。 |
6 | 支持队列内为不同队列配置不同的调度策略 | 支持 默认是基于内存的Fair share,也支持FIFO,以及多资源调度策略 | 不支持 |
7 | 支持限制队列内某个用户的最大资源使用量 | 不支持 尖叫提示: Capacity Scheduler支持限制队列中每个用户可以使用多少资源。这样可以避免一个用户接管集群中的所有资源。 | 支持 可以通过配置参数,限制单个用户使用队列最大资源的百分比,防止单个用户独占整个队列资源 |
8 | 支持负载均衡机制 | 支持 Fair Schedule的负载均衡机制会将集群中的任务尽可能的分配到各个节点上 | 不支持 |
9 | 资源分配策略 | FAIR,FIFO或者DRF | FIFO或者DRF,默认FIFO |
10 | 支持任务抢占调度 | 支持 FS的抢占比较简单,直接计算权重比,所以可以任意配置整数权重值。 | 支持 |
11 | 队列的ACL权限控制 | 支持 | 支持 |
12 | 限制队列或集群的最大并发Appplication的个数 | 支持 | 支持 yarn.scheduler.capacity.root.yarn_mobdi_prd.maximum-applications 尖叫提示:区别是Fair Scheduler调度,超出最大并发数比如40后,其他任务处理等待状态;而Capacity Scheduler超出后任务直,拒绝申请,抛出异常超出最大application的限制 |
13 | 限制基于用户的最大并发Appplication的个数 | 支持 | 不支持 |
14 | 限制AppMaster在队列/集群中最大资源使用 | 支持 | 支持 尖叫提示:这个限制的好处是防止集群中运行了很多APPMaster,也就是初始化了很多任务,因为本质上APPMaster就是一个container。进而没有资源给真正的计算任务运行,造成大量任务处于饥饿状态。 |
15 | 是否支持动态刷新配置文件 | 支持 | 支持 尖叫提示:刷新资源配置文件后,如增加队列,调整资源分配,比重,无需重启,一般10s后自动加载生效 |
16 | 是否支持Node Label | 不支持 | 支持 尖叫提示:Node Label节点分区是一种基于硬件/用途将大型群集划分为几个较小的群集的方法。容量和ACL可以添加到分区。 |
17 | 是否支持动态调整container的大小 | 不支持 | 支持 yarn.resourcemanager.auto-update.containers默认值是false,应用程序可以根据工作负载的变化来更新其正在运行的容器的大小。不会杀死任务。 尖叫提示:敲黑板!单个container使用的最大资源不会超过机器分配NM的最大值 |
18 | 规整化因子,很重要 | 支持,FS内置了资源规整化算法,它规定了最小可申请资源量、最大可申请资源量和资源规整化因子,如果应用程序申请的资源量小于最小可申请资源量,则YARN会将其大小改为最小可申请量;如果应用程序申请的资源量大于最大可申请资源量,则会抛出异常,无法申请成功;yarn.scheduler.increment-allocation-mb和yarn.scheduler.increment-allocation-vcores 比如:YARN的container最小资源内存量为3G,规整因子是512Mb,如果一个应用程序申请3.2G内存,则会得到3.5内存。 | 不支持, 动态规划因子。比如:YARN的container最小资源内存量为3G,规整因子是512Mb,如果一个应用程序申请3.5G内存,则会得到6G内存。Fair Scheduler的资源增加是最小资源的整数倍。相比FS更加可以提高资源的利用率。 |
19 | 配置方式 | Fair Scheduler使用嵌套的xml配置来模仿队列的层次结构,比传统的Hadoop风格的配置更加直观 | 通过.的形式配置a.b.c 尖叫提示:相比后者,Fair Scheduler使用的配置更加方便,直观,好吧就是简单。 |
20 | 数据局部特性 | 支持 数据本地计算策略的百分比 yarn.scheduler.fair.locality.threshold.node yarn.scheduler.fair.locality.threshold.rack 默认值是-1,0表示不放弃任何调度机会。正常值配置在0-1之间。 | 支持 Capacity Scheduler利用“延迟调度”来遵守任务局部性约束。有3个级别的位置限制:节点本地,机架本地和关闭交换机。当无法满足地点要求时,调度程序会计算错过的机会的数量,并等待此计数达到阈值,然后再将地点约束放宽到下一个级别 尖叫提示:这个对于任务本地化的控制有用,尤其对于带宽紧张的集群。 |
3.最后的最后
3.1 Fair Scheduler
- Fair Scheduler是资源池概念,大家共享这个池子里面的资源。
- 多队列多租户使用时,可以根据业务线,部门,队列的实际使用情况,根据每个队列的日均最小使用资源给队列配置一个min resource,保证这个队列的任务可以满足最低运行需求。同时为了防止单个队列过多占用集群的资源,可以通过设置max resource限制队列使用资源上线。但是max resource谨慎使用,设置不合理可能降低集群的资源使用率。
- 在满足了不同队列最小使用资源的保障后,再根据实际应用场景,给不同的队列配置不同的权重,最后FS会根据权重来为各个对列的资源池(各个对列还有子队列)分配资源(这种抢占的按照权重分配的方式本质和capacity 分配一样)。权重的设置相对capacitye很灵活,想增加权重直接修改权重整数值即可,FS会将各个对列的权重值求和。用当前队列权重值/总和的形式分配资源,其实也就是按所占的百分比分配资源。这种方式有利于动态调整资源池的使用。同一级别的队列可以设置权重进行资源分配抢占。同一个父队列的子队列之间的资源也可以通过配置权重来进行资源分配抢占,注意子队列只抢占父队列的资源。
- 如下,队列的生产配置情况。可以通过权重,限制并发,最小资源,最大资源,调度策略等方式保证队列任务的稳定调度。
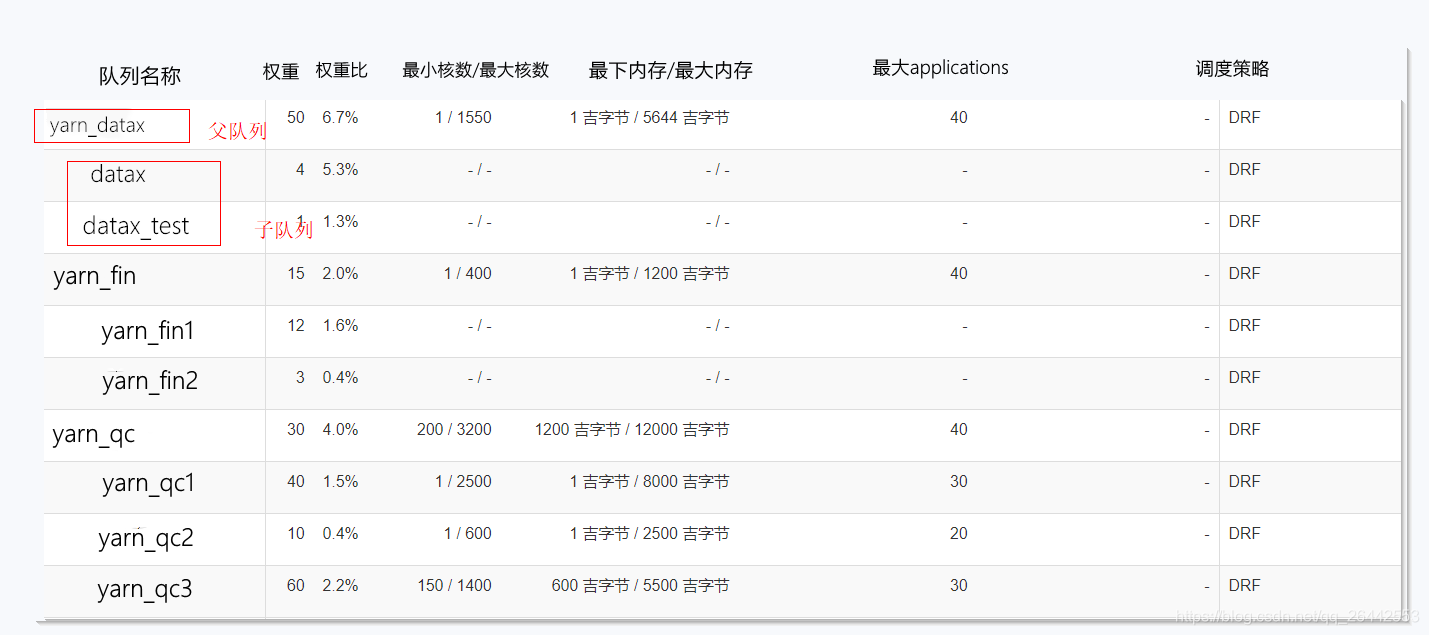
- 可以结合公司实际不同部门的资源使用情况,比如A部门主要晚上用,B部门主要夜里用,配置早晚两套或者N套资源队列分配配置文件,通过调度自动更新配置文件,yarn会每隔10s去更新读取一次配置文件,这样在无感知的情况下更加有利于调高集群的吞吐率。
3.2 Capacity Scheduler
- 相比Capacity Scheduler 是一个队列概念,新增一个任务,如果发现资源不够了,则根据FIFO规则排队;什么时候资源够了,再用。
- Fair Scheduler可以配置自动创建pool,但是Capacity则无法创建队列;其实本质差别就是在于一个是pool共享资源的概念。对于FS而言,可以使用资源池中未被使用的资源,但是Capacity则不允许;所以前者比较灵活,后者相对呆滞。
3.3 建议
如果是中小型集群,上千节点以内,资源比较紧张,建议使用Fair Scheduler,配置简单,对资源的使用效率也高。相比Fair Scheduler更加灵活,允许作业使用群集中未使用的资源。它通过基于定义的权重来给任务的公平抢占和稳定提供保证。对于中小型集群,这是一个很好的默认设置。
容量调度程序对于资源的管理更加细化,配置起来也是调度器中最麻烦的。其使用资源配额定义队列。作业不能消耗额外的资源。这需要更多的配置和不断的试错,调整容量规划。所以它更加适合不同工作负载且具有不同需求的大型集群。比如大几千,上万,类似阿里巴巴那样的集群。
参考资料:
https://docs.cloudera.com/cdp/latest/data-migration/topics/cdp-data-migration-yarn-scheduler-migration.html
Apache Hadoop 3.3.4 – YARN Node Labels
本文转载自微信公众号「涤生大数据」,作者「涤生大数据」,可以通过以下二维码关注。

转载本文请联系「涤生大数据」公众号。

















