












开篇
一般在练完机器学习的模型之后,需要将模型host成服务才能供使用者调用。TensorFlow的机器学习模型的部署也遵循这个方式,它会通过TensorFlow Serving的方式将模型做成服务,让使用者通过某种方式来调用模型,而不是直接运行模型推测的代码,也不需要使用者进行模型的部署和安装工作。整个过程需要通过TensorFlow Serving 把模型部署到服务器上。通常来说会使用Web框架(例如:flask、Django、tornado)创建服务器应用,这个应用会承载TensorFlow 生成的机器学习模型,应用启动后就会一直在后台运行,并等待客户端请求,当应用检测到有请求,就会执行模型进行推测,将推测结果返回给用户。本文主要介绍TensorFlow Serving 的工作原理、安装以及应用。
TensorFlow Serving 架构介绍
如果要了解TensorFlow Serving 的架构就需要了解它所包含的组件,以及组件之间是如何配合工作的。
TensorFlow Serving 组件
首先介绍一下TensorFlow Serving的主要组件,TensorFlow Serving的功能可抽象为一些组件,每个组件实现了不同的API任务,其中最重要的是Servable, Loader, Source, 和 Manager,我们先看看这些组件是如何定义的。
Servable
Servable 是 TensorFlow Serving 中最核心的抽象,是客户端用于执行计算 (例如:预测或推断) 的底层对象。Servables 的大小和力度是灵活的,单个 Servable 可能包含从一个查找表的单个分片,到一个单独的模型,或是推理模型的元组。Servables 可以是任何类型或接口,这使得其具有灵活性并易于将来的改进,例如:流式结果、实验性 APIs、异步操作模式。但是,Servables 并不管理自身的生命周期。
由于每个模型都就可能进行改,特别是算法配置、权重等参数会随着对模型的深入了解而进行调整。TensorFlow Serving 能够为服务实例的生命周期内处理一个或多个 版本 (versions) 的 Servable,这使得新的算法配置,权重和其他数据可以随时被加载。这就是 Servables Versions,它可以使多个版本的 Servable 可以并发加载。在提供服务时,客户端可以请求最新版本的模型或是制定版本 ID 的模型。
正如上面说到的一个Servable 会有多个Version,那么多个版本的 Servable 的序列就成为Servable Stream,它会按照版本号的递增排序。
Model
TensorFlow Serving 将一个 模型 (model) 表示为一个或多个 Servables。一个机器学习模型可能包括一个或多个算法 (包括学习到的权重) 和查找表。
你可以将一个复合模型 (composite model) 表示成:多个独立的 Servables或者一个组合的 Servables。一个 Servable 也可能是一个模型的一部分,例如,一个大的查找表可能被分割到多个不同的 TensorFlow Serving 实例中。
Loader
Loader 管理Servable 的生命周期。Loader API 提供了一个独立于特定机器学习算法,数据和用户产品用例的通用基础平台。具体说,Loader 主要处理Servable 的加载和卸载,并为其提供标准的API。
Source
Source 是用于查找和提供 Servable 的插件模块,每个 Source 提供零个或多个 Servable Stream。对于每个 Servable Stream,一个 Source 为一个 Loader 实例对不同版本的载入提供支持。(一个 Source 通常是由零个或多个 SourceAdapter 链接在一起,其中最后一项将触发 Loader。)
TensorFlow Serving 中 Source 的接口可以从任意的存储系统中发现 Servable,TesorFlow Serving 包含了 Source 实现的通用引用。例如:Source 可以利用 RPC 等机制,并可以轮训文件系统。Source 可以维护多个 Servable 或 不同版本分片中的状态,这将有助于 Servable 在不同版本之间进行更新。
Manager
前面说到了Servable,它自己是不会维护自己的生命周期的,需要通过Managers 来维护 Servable 的整个生命周期,包括:加载 Servable,
为 Servable 提供服务,卸载 Servable。
Managers 从 Source 获取信息并跟踪所有的 Version。Manager 尽可能的满足 Source 的请求,但当所需的资源不存在时,会拒绝载入一个 Aspired Versions。Manager 也可能延迟触发一个卸载 (unload),例如:基于要确保任意时点都要至少有一个 Version 被加载的策略,Manager 需要等待一个新的 Version 完成加载后再卸载之前的 Version。
Tensorflow Serving Manager 提供一个简单窄接口 (narrow interface),GetServableHandler(),用于客户端访问以加载的 Servable 实例。
TensorFlow Serving 工作流程
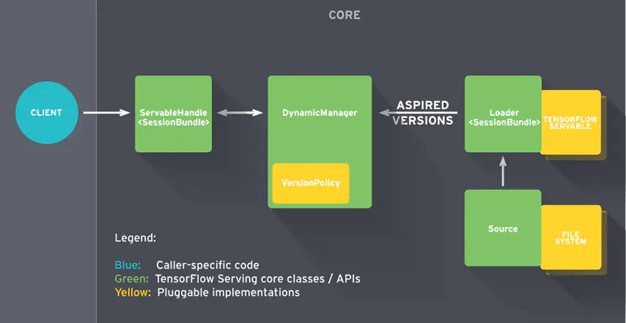
上面介绍了TensorFlow Serving的几个组件,包括:Servable、Model、Loader、Source、Manager。接下来看看它们是如何合作工作的--TensorFlow Serving 工作流。如图1 所示,TensorFlow Serving的工作流程主要分为以下几个步骤:
● 先看图1 中右下方的Source组件,顺着Source 向上的箭头它会为要加载的模型创建一个Loader,Loader中会包含要加载模型的全部信息;
● 接着,Source通知Manager有新的模型需要进行加载;
● Manager(DynamicManager)通过版本管理策略(Version Policy)来确定哪些模型需要被下架,哪些模型需要被加载;
● Manager在确认需要加载的模型符合加载策略,便通知Loader来加载最新的模型;
● Client(客户端)向服务端请求模型结果时,可以通过ServableHandle指定模型的版本(Servable Version),这部分的信息由Manager进行管理(Manager管理Servable的生命周期),然后通过Manager返回给客户端;
图片来源:https://www.tensorflow.org/static/tfx/serving/images/serving_architecture.svg?hl=zh-cn
图1 TensorFlow Serving 工作流程
TensorFlow Serving 安装和部署
上面我们介绍了TensorFlow Serving 的组成和工作流程,这里我们接着来说说如何安装TensorFlow Serving,这里推荐使用docker 和 apt-get两种安装方式。
TensorFlow Serving 的Docker 安装方式
首先保证已经安装了Docker ,然后通过运行以下命令拉取最新的 TensorFlow Serving docker 镜像。
这将拉取安装TensorFlow Serving 的最小 Docker 镜像。
接着需要对如下属性进行设置,gRPC 公开的端口 8500,REST API 公开的端口 8501,可选环境变量MODEL_NAME(默认为model),可选环境变量MODEL_BASE_PATH(默认为/models)。这些属性的设置参考如下命令:
然后,就是就是设置主机开放端口,设置所服务的SavedModel,设置客户将引用的模型名称。
以上的命令,启动了一个 Docker 容器,将 REST API 端口 8501 发布到主机的端口 8501,并采用名为my_model的模型并将其绑定到默认模型基本路径 ( ${MODEL_BASE_PATH}/${MODEL_NAME}= /models/my_model)。最后,填充了环境变量 MODEL_NAME,并保留MODEL_BASE_PATH其默认值。
TensorFlow Serving apt-get安装
设置安装源如下命令
更新源后,即可使用 apt-get 安装
TensorFlow模型导出
既然已经安装好了TensorFlow Serving,那么就需要加载对应的模型进行机器学习的推演。TensorFlow 提供了Keras 模型可以方便地导出为 SavedModel 格式。假设我们有一个名为 model 的 Keras 模型,使用下面的代码即可将模型导出为 SavedModel:
TensorFlow模型部署
安装好TensorFlow Serving 并且将模型导出,接下来就是将模型部署到TensorFlow Serving上了。 我们利用如下命令,设置模型所暴露的端口号,模型名以及模型所存储的路径。
想详细了解如何快速应用 TensorFlow 实现多端部署的同学,可以报名学习中国大学 MOOC 上的官方课程:https://www.icourse163.org/course/youdao-1467217161#/info ,或者看看谷歌开发者专家对TensorFlow部署的介绍和讲解:
https://zhibo.51cto.com/liveDetail/373
TensorFlow Serving 客户端调用
好了到这里,我们完成了TensorFlow Serving 的安装和部署工作,此时我们训练好的机器学习模型已经静静地躺在服务器上了,就等着客户端调用了。TensorFlow Serving 支持gRPC 和 RESTful API的 调用。本文主要介绍较为通用的 RESTful API 方法的调用。
RESTful API 以标准的 HTTP POST 方法进行交互,请求和回复均为 JSON 对象。为了调用服务器端的模型,我们在客户端向服务器发送以下格式的请求:
请求内容如下:
Python 客户端例子
以下示例使用 Python 的 Requests 库 向本机的 TensorFlow Serving 服务器发送 MNIST 测试集的前 10 幅图像并返回预测结果,同时与测试集的真实标签进行比较。从代码中可以看出,使用了MNISTLoader 方法获取要加载的数据,通过json.dumps 方法输入要请求的数据。接着设置headers,通过requests的post方法请求本地端口为8501 的TensorFlow Serving 服务,并将返回的结果赋值给json_response,最后把预测结果中的predictions返回进行响应的处理。
总结
本文分三个部分分别介绍了TensorFlow Serving 的组成和工作方式,TensorFlow Serving由Servable、Model、Loader、Source和Manager等组件组成,它们各司其职完成搜索Servable,加载Servable以及管理Servable生命周期的工作。接着,我们使用Docket 和apt-get的方式安装TensorFlow Serving ,并导出机器学习模型将其部署到TensorFlow Serving上。最后,使用客户端(Python为例)对机器学习模型进行调用并返回结果。
本文介绍的TensorFlow Serving 知识仅仅只是冰山一角,如果想进一步探索机器学习更多领域,大家可以学习《 TensorFlow 入门实操课程 》。想提升机器学习能力,挑战自己,也欢迎报名参与 TensorFlow 开发者认证计划https://tensorflow.google.cn/certificate,掌握更多机器学习技能,强化你的核心竞争力。
作者介绍
崔皓,51CTO社区编辑,资深架构师,拥有20年架构经验。曾任惠普技术专家,参与多个机器学习项目,撰写、翻译20多篇机器学习、NLP等热门技术文章。《分布式架构原理与实践》作者。
















{kind=link}