俗话说“缺啥补啥”。想起写这么一篇文章,不是因为自己和团队稳定性建设做得有多好,相反,最近经常被吐槽线上不“稳定”......
回想当年,作者在某度第一个项目中,从0到1撸了一个多月的码(检索模块c/c++)。后面QA测试N轮,硬是没能提出几(yi)个有效bug,线上似乎也没啥动静。现在却被人指责稳定性做得不好,这事儿看起来不能忍。
“稳定”这个词,从用户到ZF机关,一线研发到大老板,大家似乎都会经常提及。不过作者发现,他们所谓的稳定性,也不见得就是一回事。网上搜了搜,没看到有什么公认的定义,系统论述这个话题的文档也不多,讲实战的倒是不少。本文中,作者试图做个相对“系统”的论述,重点讨论“服务稳定性”是什么,应该如何建设。作者之前经历绝大部分时间都在做后端开发,能力和视野所限,难免会偏服务端。
相比于“系统性”,很多优秀的程序员都只喜欢听所谓的“干货”。在“系统性”和“干货”之间不断地纠结中,作者艰难地完成了本文。
全文基本没什么新鲜玩意,很多都是老生常谈,也借鉴了非常多的来源。作者只是努力整理并重新组织在了一起。因为来源太庞杂,我就没法一一例举相关出处,如有侵权,请联系作者删除。这里一并谢过执导过我,帮助过我和分享自己的知识到互联网的所有大佬们!
我们都在聊什么
“稳定性”其实还挺难定义的。让我们先看几个英文单词:Availability, Reliability, Stability。
- Availability
经常被翻译成可用性。看到这个单词,相信大部分人脑子里应该都会呈现很多个9。看图1,4个9的稳定性意味着一年宕机时间不能超过53min,其实是非常难的。可用性这个概念关注的是系统故障时长。实际上,我们平常会更关注这个宕机时间如何定义的。很多人说自己服务可用性是99.99%,不要轻易相信。你去帮他review下,会惊喜地发现,他可以通过宕机时间本身的定义任意调整这个值。所以如果是上下游关系,还是先把这个指标定义清楚再聊别的会比较好。常见的定义举例:影响核心功能(e.g.下单)成功率20%以上所持续时间等等。这里的X%还挺重要的。后面的讨论中,我们可以依据这个百分比,设计我们的灰度方案等。以免发布个小流量,还搞出P0,不合适。

图1 N个9的稳定性
- Reliability
经常被翻译成可靠性。相对于可用性,可靠性关注的可能会更泛一些。在服务化的场景下,大家会经常提到SLA。SLA是对一个服务可靠程度的相对量化的约定。其中就可以包括服务可用时长、接口响应时间(如99分位)、错误率、集群吞吐率等等。SLA建议尽量用书面形式提供,并且服务提供方和调用方一同签字画押。一般还有配套的奖惩措施才能工作的更好。签字画押,是为了后面少扯皮。很多时候,处理线上事故总是没有事故定责时候来的令人紧张刺激。
如果下游没有提供明确的SLA,我们就得自己根据历史数据猜测下游各项指标,以便写出还算合理的代码,比如超时时间、重试次数、限流大小等等都跟下游服务能力密切相关。当然下游也是动态的,如果对方都无法提供明确的SLA,那其实大家都挺难的。咱们自己提供的服务,最好都有明确的量化指标,随时提供给上游。如果给不出来,说明我们对自己服务还不够了解,没有足够的掌控能力。
如果是内部系统,老板还会经常关注线上问题数量和等级分布等。处理P0事故紧不紧张?这些都是在努力量化一个系统的可靠程度。
- Stability
一般翻译成稳定性。通常是指一个系统如果输入保持不变,输出也不会随着时间发生变化。但是这个稳定性,大概不是我们经常在讨论的稳定性。你会发现歪果大佬们一般讨论“稳定性”的时候喜欢用Reliability,而国内大佬们却喜欢用“稳定性”。yy一下,这很可能又是个中国特色的表述了。大概来自于前辈们对我dang“维稳工作”的深刻印象。你会发现我们所谓的“稳定性建设”跟传统意义上的“维稳工作”基本思路是惊人一致的。监控,隔离,应急处置,特殊事件保障,演练,宣传培训等等,请各位客官自行发挥想象力...只是互联网环境下,我们不太可能期待“输入不变”。而是,在输入经常不确定,且系统在不停地迭代的情况下,确保新老输入都能在预期的时间内得到令用户满意的结果。
作者认为,其实概念可能也没那么重要。“稳定性”这个词儿似乎也很贴切,有点中国特色挺好。稳定性建设的关键是,我们得找到一套大家都认可的指标来衡量他。对于相对独立的服务,作者推荐用SLA去约定一个服务的稳定性,并尽最大努力达成这个承诺。对于服务提供方,SLA不仅是一个承诺,更是对自身量化的要求。当我们都不敢做出承诺的时候,又何谈稳定性建设,何谈责任与成长?至于怎么定义一个“服务”,一是看业务边界,二是看组织架构。很多时候组织架构决定系统架构,而SLA制定过程也跟组织架构密不可分。对于终端团队,我们可以在SLA基础上做一些扩展,比如增加一些体验相关指标。有时候个别后端服务挂了,可以做到对用户无感,反而APP经常crash那可能是个灾难。所以,稳定性也得分层去看。
1)Dickerson的可靠性层次模型
其实作者之前也没听过该大佬。为了准备这边文章无意中搜到的。他据说是前谷哥SRE团队成员。然后后人在谷哥SRE电子书中引述了相关模型。大佬也是借鉴了马斯洛需求层次模型。马老师的这个模型中表示,想得到上一层的满足,你得先保证其下一层已经得到了很好的满足,否则容易“出事儿”。比如,当我们都没饭吃了,哪儿还会去关心哪个行业更卷呢?当然当我们很好地实现了某一层,那下一层需求就会是我们最大的动力来源。

图2 马斯洛需求层次
参考M老师的模型,D大佬提出了他的稳定性层次模型,以便帮助SRE团队更好的保障系统稳定性。

图3 Dickerson可靠新层次模型
在D的模型中,他从SRE的视角出发,将稳定性建设也分了7层。
- 他认为稳定性建设最基础是监控(Monitoring)。没有监控,一个服务是否稳定无从谈起。我们首先得知道服务运行情况,当系统哪里出了故障,我们需要及时发现(告警)。
- 当获知系统出故障后,SRE们需要作出一些应急响应(Incident Response),包括24小时on-call机制,系统降级预案,协同相关方进行进一步分析,定位最终原因并修复上线。
- 事后,还需要组织进行深度复盘和根因分析(Postmortem/Root Cause Analysis)。我们需要做到从失败中学习,并尽量保证未来不会掉进同样的坑。
- 前三步都是在做一些防御工事,我们应该尽量在测试阶段就发现问题,并通过科学的发布过程来保证不会轻易引入新的线上问题(Testing+Release procedures)。
- SRE们还需要关注容量需求的变化情况(Capacity Planning)。系统是动态的,我们需要尽力做到让资源在适当的时机,能够灵活的调配到真正需要他的地方。
- 以上做好之后,还需要关注一些研发的工作(Development)。这部分包括原先的系统实现是否合理,从问题反推,是否可以有更合理的设计,并推动优化。当然还有一些必要的工具也需要开发。
- 稳定性最终极要关注的是产品本身(Product)。从用户角度,稳定性意味着什么?哪些是他们核心关注的?我们应该努力通过产品和流程设计等减少用户对系统故障的感知,甚至做到无感。
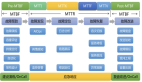
2)本文讨论框架
可能大部分国内互联网公司没有真正的SRE团队。即使有这样的团队,据我所知他们可能更关注一些更宏观的稳定性建设。日常的服务级别的线上稳定性保障,一般都是由研发团队主要负责的(一般是事故主要责任方)。因此本文中从一个一线研发团队视角出发,去讨论稳定性建设该如何做。
事实上不管是R&D还是SRE团队,要关注的问题是相同的,只是视角略有不同。既然上面铺垫了这么多,作者也参考D大佬的层次模型,引出下面的稳定性框架图(向大佬们致敬)。当然所谓框架,也没什么新意,更多是方便我后续组织文章。

图4 本文讨论的稳定性建设框架
在上图的框架下,虽然也有分层,但跟D不同,作者认为没有谁比谁重要或者上层强依赖下层关系。只是为了讨论方便可以分层去看。传说中的“既要也要还要”,总是那么的“正确”。我们很难在这些层次上进行取舍,只能说都很重要。作为一个R&D工程师,我们需要时刻关注所有这些方面的问题,最多可以根据自己团队当前状况和急迫程度判断优先级。下面会逐个去讨论。
稳定性建设该如何做
因为篇幅和视野限制,本文无法求全,也不太可能非常深入。如果能抛砖引玉,作者就很开心了。
1、梳理
梳理其实可以没有,理想情况是我们对自己的系统一直都非常熟悉,知道他是怎么工作的,目前他还存在什么问题。但现实可能是:
- 我们一直在非常“着急地”上着线,周而复始。因为“着急”,我们当时做了很多折中,做了很多临时的事情。说好的后面优化,一直都还在后面。甚至因为人员轮换,可能都已经不记得当时埋了哪些雷;
- 可能你刚接手了一个新的系统(和团队)。当然,你也可以理解梳理为一种复盘。只是他可能没办法那么频繁。
那我们需要梳理什么呢?这个其实没有标准答案,得看系统和团队当前情况而定。下图针对一般情况罗列了一些常见的梳理项。可以根据实际情况进行增减。这也适用于我们快速去熟悉一个新接手的系统。

图5 梳理
梳理的过程很多时候都不是一个人可以完成的。我们需要协调很多人参与进来,并进行集中串讲,共同分析等。不要一梳理就梳理几个月。类似迭代开发,我们也可以逐步去梳理,甚至还需要跌带着去做。当一个团队人员流动比较大时,新人串讲也是挺好的一个时机。
当一个相对理想的梳理工作完成之后,我们大概能知道当前系统现状是什么,有哪些稳定性隐患。很多时候知道隐患在哪里,比排除和优化更重要。剩下的就是按优先级排期逐一解决了。梳理本身也会帮助我们重新审视自己的系统,加深对他的理解。这对于后续迭代开发,线上问题跟进等都有莫大的好处。所以,当觉得自己团队没事儿干的时候(往往都是错觉),可以让大家多去梳理(串讲)一遍自己的系统。
这一步,还有个重要产出是:哪些业务指标是需要重点关注的,核心接口有哪些。这部分在下一节中会重点讨论。
2、监控&Trace
1)监控
监控大家应该都不陌生。在上文中我们也梳理出来了当前服务核心指标和核心接口都有哪些(新项目应该是在设计阶段就应该定义好)。我们需要重点围绕这些指标和接口进行监控建设。监控主要目标是当服务异常时,我们能第一时间感知,以便尽早介入,尽快止损。另外,通过合理的监控设计,我们还可能尽量的缩小问题范围,帮助我们定位问题根因。缺失有效监控,我们就是个瞎子,每天都掉坑也是正常的。
监控大致可以分成三层去看,本文只讨论业务层。

- 核心业务指标监控
这个经常不被重视,但他却是最重要的。我们应该首先站在业务视角去看到底应该关注哪些指标,然后再去想办法监控这些指标。既然说是业务指标,肯定就跟业务本身有关了,所以各个系统可能都不一样。举例,对于一个订单系统,那么我们关注的核心指标可能有:下单量、成单量、取消量、超时未支付量等等。然后我们想办法对这些指标进行准实时监控。当这些指标有明显异常,可以即刻发出告警。
当业务数据较为稀疏时,秒级监控可能经常会误告警,我们可以适当把时间窗口拉长一点看,比如降级为分钟级监控。甚至我们可以根据业务高峰期等自动调整监控周期。
这里核心是如何定义好一个指标。当指标定义明确,以咱们的聪明才智相信总能有办法监控他,并且总能找到一些报警策略(不行上AI),使其足够灵敏,误报警概率也还能接受。常见的监控手段包括基于log和数据库binlog的监控。极端一点的情况,我们可能需要在业务代码里单独为这些指标打log(记文本或写库)。所以说,监控设计也是系统设计的必要组成部分,最好前期就考虑好。
- 核心接口监控
接口监控应该不用我多说。重点就那三个指标,QPS、延迟和错误率。这里错误率的统计,对于错误码规范有要求以外,其他基本都是标配。做细致一点,需要对接口调用方单独做监控。比如接口QPS突然飙升,我们需要尽快知道到底是哪个来源。
- 下游依赖监控
下游可能是服务提供方、也可能是个中间件。中间件一般都有单独团队维护,他们会提供通用的监控大盘等。业务方要做的更多是从自己的视角看这些被依赖方他的实际运行情况如何。因为绝大部分依赖都是通过RPC进行的,所以类似接口监控,我们需要关注下游调用成功率,响应时间等等。当然如果下游都提供了监控大盘,可以考虑把两者合并一下,找起来方便。
- 监控大盘
呈现很多时候都挺重要的,就像如果有人PPT写得好,你不能否认他其他方面也大概率比咱更优秀。为了看起来方便,我们需要分层去建设监控大盘。每个大盘也不能太大了。大盘在线上走查,上线回归等场景必不可少。这里没什么新鲜的,把分层设计好就差不多了,不啰嗦了。
2)告警
告警策略其实可以复杂到很多大佬都在谈AI了。常见的就是同比异常、环比异常、超阈值等。策略核心就是在召回和准确性之间各种折中。作者的观点是宁可误报,不能漏报。误报得多了,我们自然就有动力去优化了。至于告警方式,传统的,电话、短信为主,钉钉、email为辅。报警内容一定要尽量多的带一些具体指标项和数据等(注意信息安全,运营商你们懂得),以便我们快速判断问题严重性。
很多时候,我们报警策略本身可能也会不稳定,也可能设计得不够灵敏。这时候就要求我们去主动去巡视。比如上完线,都去看看大盘是否有异常,值班同学每天定时扫几眼(尤其高峰时)。当然机器和服务太多了,无法人肉去看大盘时,也可以搞一些自动巡视脚本提效。
3)Trace
他可以有个高大上的名字“根因分析系统”。通过监控,我们知道系统有问题了,这个还不够。当我们及时止损之后,应该抓紧定位根因。trace系统一般依赖系统日志采集,并通过二次索引,提供快速的查询线上问题和统计分析的能力。通过trace,我们除了追踪单个请求链,还可以生成系统整体拓扑,系统热点分析,整个链路性能分析等等。这里log设计和规范是最关键的。如果系统里的logid(traceid)都还没打通,团队都不知道spanid是个啥的话,那工具其实也可能还不重要。当然最好是这些都在框架层面就解决了,没必要让每个程序员都关注他们的存在(除定位问题时候以外)。最终,trace还是需要有个强大的配套工具支持的。这个数据量可能会很大(降级为采样?),分析效率又很关键,没有好用的工具,全靠写脚本很多时候都不现实。
3、应急处置 & Case Study
1)应急处置
说白了就是线上问题处理。因为每个系统设计和现状,甚至每次遇到的问题都不一样,所以很难搞出一套通用的机制或方法论。这里只是简单聊一聊一些思路。
① 责任人
当线上有问题,我们首先得有明确的责任人去跟进。如果是监控告警发现的问题,那么谁收到告警,谁就应该是那个责任人(不怕多,就怕没人跟)。“首问责任制”听过的朋友大概也能知道我在哪儿被蹂躏过了....其他情况,通过值班机制等保证每个关键时间段(比如高峰期),都有明确的人能及时跟进。每个团队情况不同,可以自行设计。这个值班人可能是研发,可能是SRE,也可能是个技术支持之类的。
② 判断影响面
作为责任人,首先要做到遇事不慌,快速判断影响面。看核心业务大盘是否受影响。影响了核心业务,那就立刻需要升级处理。紧急问题应立即通报。如果业务大盘影响不大,那其他报警叫得再欢,咱们其实也不虚(再论监控的重要性)。一般问题,可以考虑进一步确认影响,或者直接跳到“找根因”环节。
③ 通报
需要明确紧急问题通报范围,让更多的人参与进来协助处理紧急状况。其中至少要包含自己leader。
④ 止损
通报后,紧急事件应优先考虑止损。
- 近期有相关上线,优先考虑回滚(比如时间点比较接近,或改动跟该功能有关)。
- 如果是流量突增,那应该考虑限流+紧急扩容。
- 如果是下游服务异常,那么应该考虑降级。
- 如果单个集群问题,考虑切集群(机房)。这里,你会发现各种case,其实是无法枚举完的。
唯一共同点是,每次事故原因,起初看起来都很迷,最后定位后都很傻X,而且总是惊人的相似。所以应急预案,需要平时积累,现场去想,大概率就迟了。预案主要是依据历史事故和架构师们的经验,不断积累的过程。每个业务不同的故障预案都不同。上面止损里简单描述了集中常见故障及处理预案。作者想强调的是,预案不应该只是文本,而应该是经过验证的(演练过)极简操作步骤,最好是已经工具化(e.g. XX脚本)的。
⑤ 找根因
当我们有效止损之后,应该把精力放在寻找跟因上。如果发现无法快速止损,也别太执着了,至少可以分一部分人力找根因了。定位问题,有时候看起来是一门玄学,大神一出马,往往很快就能破案。而且你会发现,大神总是那几个人。他们为什么比咱快呢?我想,首先肯定不是因为他代码写得好,也不见得有咱写得多(某些人眼里的“技术牛”)。而是,他对系统更熟悉,他了解系统整体架构,知道哪里是一些脆弱环节,容易出问题,上下游依赖情况怎么样,哪个下游比咱还不靠谱;他经常去听各种复盘,知道类似的问题之前出现过,是什么原因导致的;他对各种工具更熟悉,比如trace,监控系统等,所以效率更高。慢慢的他们就形成了一套自己的方法论,甚至可以从现象猜测出几个最可能的原因,然后去逐一验证。可见,平时积累非常重要,要对自己所用的框架,所负责的模块上下游都要做到尽可能多的了解,甚至去多读一读他们的源码。
线上如果有稳定复现的环境,可以下线一台服务器专门定位问题。如果线上无法快速定位,可以考虑线下复现。所以线下镜像环境也是很重要的。一方面,可以用于平时线下测试,当线上有问题时候,也可以用来复现问题。能复现的问题,其实就没什么难度了。最后,大家一定要相信,没有什么问题是无法定位的,事实也是如此。
很多时候无法定位,都是缺少关键日志,所以要养成各种异常分支都需要打个日志的好习惯,我们开始时候不要怕日志多,告警多,等我们无法容忍的时候总会有人去优化他。但是一旦少日志,没告警的时候就欲哭无泪了。
根因找到之后,我们需要上线验证,并统计和修复损失了。
2)Case Study
其实是一种特殊的复盘。每次的线上问题,都是我们成本最高的一次学习机会。所以,一定要珍惜,要认真对待。相信大家也经常做,所以具体复盘模板这些就不用我多说了,相信每个公司都有自己的一套。几个tips:
1)不要把Case Study搞成批斗大会。虽然定责很重要,但是不用太纠结这个。我们得有一套相对客观的定责标准,省得有人纠结这个。比如之前我们就约定线上事故由源头负主要责任(很多时候是全部),什么上游保护下游,上游限流没生效,上游没合理重试这些都是额(che)外(dan)的。还是得想方设法保证自己不挂,挂了就得认。我们更多要去想怎么从失败中学习,不断完善自己的系统。我能想得到唯一需要我们保护的下游可能是MySQL,因为他实在太老,太脆弱了,可得对她温柔一点。
2)围绕根因要多去想是否还有其他类似隐患,要真正做到举一反三,比如排查其他模块是否有类似问题,比如拉上上下游关联系统一起看怎么全链路优化,比如故障期间产品提示等是否可以更友好一点等等。
3)对于发现的问题要做好保护:
- 监控配置和日志打印是否需要优化?以便下次有类似问题不用这么辛苦去定位。
- 相关代码是否需要重构?
- 测试用例增加了吗?
- 线上问题预案是否需要增加相关条目?
4、测试&发布
1)测试
质量跟稳定性很多时候都是划等号的。质量保障是整个软件工程核心活动,是研发人员的职业底线。对于工程团队,如果这个底线没守住,那其他努力都将变得黯淡无光。我们必然要竭尽全力,让问题在上线发布前就发现并解决了。
测试如此重要,以至于国内很多互联网公司都有专职的QA团队。当然,即使有了QA团队,测试工作也并非全部由该团队完全负责。研发人员要对自己编写的代码负全部责任,有没有QA团队都一样。设有QA团队,有提测这些额外的流程,更多是为了再多一层保障。
作者没有实际研究过QA团队自己是如何定位并规划他们团队的工作的,所以以下都是站在研发角度讲的,理解有偏差的请见谅。因为测试相关话题太大了,这里只是简单罗列一些常见的测试类型。至于怎么做,如何算做得好这个估计得再好好学习学习才行。
① 单元测试(Unit Testing)
指单个函数、模块或功能级的测试,属于白盒测试。一般都是由研发人员自己完成。敏捷团队应该都了解测试驱动开发(TDD)。在一些传统软件行业,如通信领域等可靠性要求较高的单位可能工作的会相对好一些。互联网领域,尤其其中做上层业务开发的,真正把TDD用得好的并不多。不过一些思想值得我们时刻参考。要想把单测写好,维护好其实并不那么容易。首先,写出来的代码,得对测试友好。这对于编码能力是有一定要求的。往往抱怨单测很浪费时间的,大概率是代码抽象,尤其接口层面设计,分层这些没有做好的那些人。另外,测试用例需要维护,是有成本的。甚至测试用例的代码量会远远大于业务代码。不过要知道自动化测试用例,不是为了一次功能测试而编写的,更多是一个文档和一种保护。保护测试好的代码不会被后人轻易破坏。他可以反复、全自动执行,所以叠加起来的价值可以很大。有了自动化测试用例,我们就可以在每次代码变更时候,都可以自动跑一下这些case。这个属于check in build的一部分。因为case数量会越积累越多,我们为了不影响开发效率,可以把这些case分成快速的和全量的。快的是每次check in都会执行(check in build),慢的可以是天级执行(daily build)。
② 集成测试(Integration Testing)
指将已经完成了单元测试的模块等组合起来测试,比如接口测试,某个流程测试等等。他一般针对某个功能点(特性)进行测试,通常属于黑盒测试。研发内部的联调测试,QA的大部分测试工作,都属于这个范畴。
③ 系统测试(System Testing)
指从交付角度(用户视角)进行的更宏观的测试。操作系统适配测试,低端机适配测试,弱网测试,安全测试,性能测试,压力测试等等,都可以归为系统测试大类。
④ 回归测试(Regression Testing)
当系统有变更时,我们通过回归测试保证原有功能都没有被破坏。一般分为线上和线下,而且希望这部分自动化程度越高越好。靠人工去做回归测试将必然是个悲惨的故事。
⑤ 冒烟测试(Smoke Testing)
据说是最早做板子的前辈们,在设计好一块板子之后先通电看看会不会哪里冒烟。如果冒烟就说明根本没必要进行任何其他测试了,直接回炉重造。在软件行业,一般指的QA团队的准入测试吧。一般要求他能自动运行,且速度要快一些。冒烟没通过,直接打回提测流程。
⑥ α测试(Alpha Testing)
一般是指客户侧在正式交付前的验证测试。不过互联网行业很少提这个了。
⑦ β测试(Beta Testing)
将产品交付给少部分用户,然后进行实际场景应用,并收集反馈。我们一般叫小流量测试或灰度测试了,换了个名字。
⑧ 压力测试(Stress Testing)
测试一些临界压力情况下的系统表现。比如系统最大同时在线的用户数,最大支持的输入大小,模拟用户恶意下单等等。一般是针对系统级的全流程测试。当然如果某个接口很重要,有时候也会说做接口压测,实际上就跟下面的性能测试有点混淆了,不过这个不重要。在to C场景,压测是非常重要的,如果有一套成熟的压测体系,那恭喜你,至少心里会踏实很多。当然搞一套有效的压测体系,我们也需要不小的投入。可能会面临的几个挑战:
- 压测工具本身并发度是否可以达到我们的要求?
- 压测请求如何模拟,线上录制?签名、token这些都很麻烦。
- 压测流量如何标记?
- 提交接口怎么压?产生的很多“垃圾数据”如何清理,如何跟真实数据隔离会是个大麻烦(影子表?)
- 全链路压测,涉及到多个团队,甚至是多个部门协同。如果要做架构升级(比如增加流量标记),那可能至少都是按月计的。压测期间很可能还会影响线上服务,深夜也有用户咋办?
⑨ 性能测试(Performance Testing)
比如某个接口的单机性能,集群性能等。
⑩ 故障演练(Recovery testing)
模拟各种故障,比如下游宕机,数据库离线等等,然后看系统表现是否跟设计一致。可以认为是系统级的异常测试。Recovery testing还会关注当故障恢复后,系统是否可以自动复原。
还有很多名词,有的作者也没接触过,就不再发散了。
2)发布
据不完全、不可靠统计,70%以上的线上事故是由代码变更(包括配置)引起的。可见把测试好的代码发布上线是一个非常高风险的事情。为了尽量降低这个风险,人们搞出了各种各样的灰度策略和机制。他的本质是:1)开发和测试人员没能测到的问题,就让更多的用户帮我们测试(众测);2)为了控制影响面,需要逐步放量,争取在最小的影响面下发现问题。下面简单介绍下常见的几种灰度方案。
① 金丝雀发布
矿工的故事大家应该都听过了,不再赘述。其实很多时候我们所谓的灰度发布,基本就是等价于金丝雀发布了。通常我们会把集群分成几个集群,典型的预发布、小流量和全量集群(当然可以有更多级)。然后,逐步放量。其中预发布一般不对外,我们把代码上到预发布环境,通过自动化回归脚本+人肉,进行新老功能的回归。如果有内测环节那就更好了,找一些公司内部的用户帮忙验证一下。到小流量环境是要有真实的公网流量的。我们一定要预留足够的时间来收集反馈。当然具体时间是根据版本大小和厂子现状定的。收集反馈最核心就是之前建好的监控大盘了。如果能收集真实的用户反馈那就更好了。VoC自动检测,其实也算监控一种吧。比如直播系统,用户刷屏“卡”“卡死”...
金丝雀发布估计是用的最多的一种发布方式。其核心是制定一套分流机制。最简单就是在router层按流量随机分流了。如果你的服务只跟流量本身有关(典型的就是不用登录的场景,如百度搜索),那用服务器灰度就够了。1台,10%,100%...如果想根据用户分流(要求一个用户要不用旧版服务,要不就用新版的),那么就得需要一些设计,典型的是在HTTP头里增加一些分流标识等。如果再复杂的分流策略,那么就得自己搞个gateway了。有集中存储的时候,比如MySQL,那么存储层面要不要也分开,也是个问题。
客户端在各大应用市场的发布策略,一般也都属于这一类。
② 蓝绿发布
很少用。大致思想是搞两套集群,蓝色是老的,新的是绿的。起初流量指向蓝的,等把代码部署到绿的,验证ok之后把流量指向绿的。下一轮发布,把颜色交换一下。好处是回滚快,成本就是多了100%的冗余。可以做细一点,比如类似滚动发布,每一轮(比如10%)都走蓝绿,到下一轮时就回收蓝色当绿色。这样就只需要10%的冗余了。
③ 影子发布
核心是流量复制。老版本依然保持服务,新版本部署到新环境后,把老版本的流量copy到新版本(可以是部分流量),然后验证新版本的功能。我们做了一轮纯粹的技术重构后,对比新老版本结果是否一致,经常这么玩。如果机器资源不太够,也可以通过代码开关进行相关验证。
④ A/B测试
很多策略模块喜欢A/B。其部署可能都在一个集群,只是策略插件有多分,我们通过程序开关控制不同的用户走不同策略,然后对比不同策略的效果。A/B可以很复杂,也可以认为是金丝雀的一种吧。不展开了,还有专门做ToB的A/B系统的单位,可见其复杂度和价值。
3)CI/CD
聊到DevOps,都会说到这两个概念。这两个单词分别是Continuous Integration和Continuous Delivery的缩写。其核心是通过一对自动化的工具和流程,使得我们迭代开发和发布变得更高效,更有保障。话题有点大,不讨论了,附一张图:

图6 典型的CI/CD流程
5、设计开发
软件设计和开发,应该是我们最熟悉的了。不过这次咱们从稳定性视角再去看一看。很多事情在设计开发阶段考虑好,才是ROI最高的。
1)设计
软件设计也是个很大的概念。什么是一个好的设计?估计不会有什么明确的答案。但是一个糟糕的设计,会导致我们迭代成本越来越高,稳定性保障变得异常困难 。前辈大佬们基于自己的实践经验,概括了一些大家耳熟能详的设计原则。我们遵循这些原则,不见得能解决所有问题,但是可以规避很多可能的大坑。
① KISS(Keep It Simple, Stupid)原则
爱因斯坦讲过:如果你不能简单的解释它,说明你还没有足够的理解它。某度的“简单可依赖”似乎也是在强调这个事情。只有它足够“简单”,它才更“可依赖”的。简单在软件工程里意味着:
- 当有故障时,我们可以快速的定位;
- 当重构或接手时,我们可以更容易;
- 我们往往都少写了很多行代码,无论是开发效率还是维护成本都会更低;
- 能做出简单的设计,意味着我们对这个事情看得更透,实现质量更高。
为了简单我们:
- 要尽量避免引入一些大家不熟知或未被验证的技术栈;
- 不需要一些隐晦的实现,可能他看起来很cool;
- 不提倡每个工程师都最大化自己的“个性”,需要遵循一些规范,虽然他看起来很笨重;
- 最重要的是我们一定要始终相信总会有更简单直接的实现。
② YAGNI(You Ain’t Gonna Need It)原则
意思是,如果一个事情你不是今天就需要,那大概率就是你不需要的。我们总希望自己能高瞻远瞩,一劳永逸,偶尔还想秀一秀技术。但事实是,我们不管是产品功能,还是代码实现,总是有很多无用或者很少用到的东西(2/8定律)。多余的这部分反而是更容易出错且维护成本更高的(因为团队对这部分更陌生,且升级迭代时经常忽略这部分)。所以我们要尽量杜绝过度设计,包括画蛇添足,过于超前等等。很多时候识别真正现在就需要的东西,还是有点难度的。作者认为,
- 如果无法做到事前判断,那时候一定要做到时候及时评估。该删就得大胆删,因为维护成本往往比开发成本更高。这个评估过程,也会对我们未来的判断带来一些经验和依据;
- 判断一个事情暂时用不上,那么就看我们现在实现和未来实现成本差异有多大。如果差别不大,或现在做成本小那么一丢丢,那么就放到后面再去实现吧。做好扩展能力设计等就ok了。
所谓前瞻性设计,更多是在思考和调研阶段要尽量考虑周全,想好各种异常和未来扩展性需求。而真正实现的时候,做取舍才能体现架构师真正的实力。很多时候我们倡导提供简单直接的实现,然后做好兜底。兜底可以很暴力,只要他发生的频率不高,很多时候都是可以接受的。等我们无法容忍的时候,就有动力优化了。敏捷开发中有很多这方面的思考:我们持续交付那些优先级高的最小集合。让系统先跑起来,然后根据用户(可能是甲方)实际使用反馈再决策需要增加哪些特性或哪些体验需要优化。
③ DRY(Don’t Repeat Yourself)原则
顾名思义,要以Ctrl C/Ctrl V为耻。我们应该尽最大努力杜绝重复代码。提高代码复用,对于开发、维护效率至关重要。更重要的是,我们不该把测试等额外的精力浪费在重复测试几乎相同的代码上。为了减少重复,我们自然会对自己的代码做更多的分层、抽象、局部重构等,使得每段代码,每个函数他的职责会越来越明确,单一。
④ SOLID原则
大名鼎鼎,大家应该都非常熟悉了。针对面向对象场景,大佬们(一说是Robert J. Martin,即Uncle Bob首次提出的,应该不全是他的)总结出了五条原则,目的是让代码可维护性更高,更好理解,更容易扩展,避免随着代码量的增加代码越来越复杂。从稳定性角度,遵循SOLID原则,也会使得我们的代码变更更加可控,影响面不会被无限放大。这几个原则实在太出名了,请各位客观自行查阅相关资料吧。附图如下:

图7 SOLID原则
⑤ IDEALS原则
分布式系统,尤其是微服务盛行的今天,有人觉得也应该有类似SOLID的一些准则,用来指导整体微服务架构设计和实现。2020年时候,InfoQ上有位大佬提出了IDEALS的概念,目前看影响肯定没有SOLID那么大,但可以对我们带来一些启发。遵循这些原则,虽然不能解决所有问题,但是可以让我们的设计和技术选型有据可依,至少不会跑太偏。下面大致解释下概念:
IDEALS是以下几个单词的首字母拼接:Interface segregation, Deployability (is on you), Event-driven, Availability over consistency, Loose coupling, Single responsibility。
- 接口隔离(Interface segregation)
希望通过面向不同的客户、不同的应用场景提供单独的接口,减少不同客户之间的改动影响到其他客户。这里最典型的一个问题是web和移动APP是否要提供独立的接口?BFF(Backend for Frontends)就是非常典型的一个设计模式,可以自行了解下。
- 可部署性(Deployability (is on you))
中文翻译不一定准确,仅供参考。微服务架构使得线上部署单元变多了,所以如何更高效的发布和监控变得更加重要。这里好的工具对效率的提升至关重要。下面几类技术和工具,兴许都能用得上:容器化(Docker+k8s)、Service Mesh(Istio含Envoy)、API Gateway(提供协议转换、接口路由、安全控制、熔断、限流、配额管理、流量监控等等能力,部分能力逐渐在被Service Mesh和开发框架,如Spring Cloud等代替。Kong/tyk),Serverless(各云厂商提供的云函数FaaS),监控工具(Prometheus/Grafana,还可以关注laiwei老师的Open Falcon和最新的Nightingale),日志采集(其实很多监控方案都自带了采集能力,ELK/splunk),链路追踪(Zipkin/Jaeger),DevOps(文化+工具+实践),灰度发布,IaC(Infrastructure as Code),CI/CD(Jenkins/Argo CD/Flux)。如果你有个非常靠谱的基础架构或运维团队,那么以上其实更多是关注如何使用就好了。如果没有或你就是那个团队成员,恭喜你,在微服务和云原生的冲击下,这块更新换代还是比较快的,要学习掌握的真不少。关键这些都是一些基础设施,对稳定性和易用性要求都极高。
- 事件驱动(Event-Driven)
虽然他不等价于异步模式,但他们密不可分。微服务架构中,鼓励大家大量使用基于消息的异步通信。这是调用方和服务提供方之间比较彻底的解耦方式。一方面,可以做到消峰,高并发情况下,也不会因为下游服务处理能力导致拒绝服务;另一方面,消费方可以根据消息量灵活扩缩容,而且还给你留了一定的反应时间。目前MQ中间件基本都已经很成熟了,一般场景下甚至丢消息都不用太考虑,只有增加一些兜底措施就好。另外,MQ的可用性一般都远高于业务服务,所以也不用担心引入他带来的稳定性损失。只要对于响应时间没有特别敏感,原则上能异步就异步。挑战可能是对于业务本身的事件驱动的抽象,前端的体验设计和MQ本身的规划和管理上吧。
- 可用性胜过一致性(Availability over Consistency)
在大部分互联网场景下,我们更注重可用性,而对于一致性,降级为了追求最终一致性。CAP原理相信大家都非常熟悉了,而且这个话题有点大。这里就当做是一种常识吧。Command Query Responsibility Segregation (CQRS) 可以了解下,附一张原图:

图8 CQRS
- 松耦合(Loose-Coupling)
解耦带来的好处应该不用解释了。具体解耦方式也有多种。这里核心不是怎么解,而是怎么发现。比如一个模块本来很简单,后来由两个团队共同维护,那可能这两个团队分工合作就有耦合了,可以考虑拆分。如果一个系统足够简单,数据量也不大,非得搞个CQRS,全异步那也只是在徒增烦恼,不见得能真的体会到“解耦”的好处。
- 单一职责(Single Responsibility)
类似SOLID里的S,他强调的是服务内部要高内聚。很容易理解,但是可能很难把握。服务分的太粗,就逐渐退化成单体应用了。如果拆的特别细碎,部署运维会是个问题,另外还会额外增加一些RPC代价。个人一些简单原则(只要纠结,肯定都能找到一个反例,仅供参考):
- 一个微服务,尽量对应一个数据库。这里,如果某种场景必须要有事务保证,那相关操作必然得在一个服务。不过建议尽量减少大事务,而是追求最终一致性,上面有讨论;
- 如果业务场景中,绝大部分请求,都会涉及多个同一层“模块”(分层是另一个维度,不算),那这些“模块”就放到一个服务吧,除非有很强的拆开的理由。这里如果用DDD描述可能更容易理解。不过作者对DDD理解不够深入,不敢提;
- 组织架构决定系统架构,不同团队维护的,就想办法从代码层面拆清楚;
- 如果拆开目前没有引入无法接受的成本,那么就先拆开吧。合并,一般都会比拆分成本更小。
- 拆分过程可能比结果更重要。能把一个看起来凌乱的事情抽象成多个相对独立的事务的组合,必然会降低其复杂度。如果考虑运维成本等,可以先只是逻辑拆分,物理上可以是一个包,一个节点。
2)开发
开发过程其实真正写码的时间也很少,这里强调的更多是一些局部设计和编码过程中要避免的一些坑。当然我们编写出来的代码质量才是最终决定系统运行情况的根本保障。各大厂应该都会有一些开发手册等。其中最出名的应该是《阿里巴巴java开发手册》了,作者认为没有之一。手册中自称愿景是“码出高效,码出质量”。很显然通过此类手册,我们希望一方面能规范一些开发过程,另外,也通过一些基础的保障和警示,提高程序员编码质量。其中每一条规约后面,可能都深藏着无数深坑和历史上在此坑掉下去的大侠们。
我们也可以从稳定性角度制定类似规范。我们要做的是不断完善自己的开发规范同时,应该根据团队实际遇到的一些问题,复盘的线上事故等来不断沉淀自己团队的一些相应的规范和禁忌。线上事故是我们缴的最贵的学费,不要轻易浪费他。
有规范是一方面,更重要的是执行。这块可能更多是依赖一线leader的执行力和管理能力了。
6、工具&文化
这俩放一起,其实没那么生硬。有一种文化叫“工具文化”~
1)工具
其实前面聊了很多工具相关的事情了。这些工具包括一些开源项目或商业软件,也可能是团队自研小工具等等。我们经常讲能依靠工具就不要依赖流程,能建立流程就不要依赖人的主动性。合理使用工具,让一切能自动化的自动化,一方面是提高执行效率,另一方面降低人为引入的失误风险。一些常规,繁琐或容易出错的事情,我们就应该考虑建设相对应的工具。比如一些环境搭建,代码检查,自动化测试和CI/CD流程等都可以完全交给工具去完成。除此之外,线上trace,debug,兜底操作等都依赖工具支持。还可以例举很多场景。
作为一名优秀的工程师,咱们能自己动手提升自身工作效率,降低犯错的概率,为什么不多去努力呢?
相反,如果工具层面欠缺太多,那就该咬咬牙把这块能力先补上吧。比如,日志采集和监控,CI/CD,如果没有很好的工具支撑,那我们就需要(反复地)做很多额外的事情,而且随着系统演进和团队壮大,这部分工作量都是成倍的增长的。我们就该尽早重视这部分建设。一些小团队创业型团队,这部分反而往往被忽略,不被重视。看起来组织永远没人力投入,实际上过段时间去统计,你就会发现总的额外投入往往要比工具本身上的投入要大好多倍。
稳定性建设是个无底洞,如果没有很好地提效工具,那么ROI就会越来越低。如果你想说服你老板加大在稳定性方面的投入,那不得不去讲ROI。工具虽然不是全部提效手段,但肯定是最重要的一个。
2)文化
我们通篇都在讲稳定性可以怎么怎么保障,看似很系统。实际情况是,很多时候所谓稳定性建设可能都只是有一阵风,吹过之后似乎什么也没留下。系统在不断迭代,人员也会不停流动,如果没有一个好的文化传承,我们其实无法保证这块的持续投入和效果。那怎么建设一个团队的稳定性文化呢?其实这话题可能是我一万个最不擅长的事情之一了。不过既然提出来了,就简单分享下此刻的一些认知吧。参考HR部门关于企业文化建设的思路:
首先,提炼它。文化一般都希望能提炼成一两句话,让团队朗朗上口。这样才能更好的传播和传承。我自己团队,用一句话强调稳定性的重要性:稳定性是我们的底线。意思是,如果稳定性没有做好,做再多拔高的事情,其实也都可能会归零。我们不要求一切都以稳定性为前提(很多时候迭代压力会极端的大),但是要明确意识到,稳定性不管什么时候都是我们的底线,要时刻提醒自己是不是做的足够好了。至少要做到在当时那个环境下充分评估稳定性风险,并保证最大程度的投入。如果因为一些交付时间等原因,做了一些妥协,那一定要在接下来最快的时间内把稳定性欠债还上。
其次,运营好。文化是需要运营的。作者认为比较实用的一些运营方式有:
1)建立明确的奖惩措施。比如线上事故得有些具体惩罚措施。可以是物质的,也可能是更柔和的。当然做得好的,要多去鼓励,多去传播。
2)识别关键人员,并加以引导。让更多的人帮助自己推广相关理念和要求。比如每个小组的leader,一些核心开发人员。他们在一线,很多时候他们说的话更有感染力。所以一定要先跟这些人员达成一致,并让他们一方面身体力行;另一方面,作为稳定性文化的坚定传播者,帮助组织共同传承和发扬光大。
3)洗脑式宣贯。我们要不停的讲一些稳定性方面的意识和实操层面要关注的事情(比如监控设计和发布设计都是系统设计阶段要考虑的)。稳定性宣贯有个特别好的时机,那就是线上出故障时,我们一般都会组织复盘或case study。那这时候所有的稳定性主张都可以重新再review下。看我们哪里做得好,哪些点没做到位。只要坚持高质量的复盘和case study,就可以在团队内部不断强化相关意识。而且问题越多,力度越大。问题不多时候有稍微放一放不见得一定是坏事。当然系统不可能没有问题的,这个度就得管理者自己拿捏了。小道cr问题,qa发现的bug等等只要想强调,就可以组织case study。这里复盘再稍微罗嗦下的是:一方面,复盘时不一定都是全员可以参加,所以复盘结论的通晒就很重要了(不要藏着掖着);另一方面,复盘容易,闭环往往都不是很理想,所以应该更多的去关注闭环效果。其中就可以review下文化,意识层面的改进项。
再者,把它融入到其他文化建设中,形成更广泛的传播。稳定性文化单独拿出来,其实有可能只是一个点。但是像工程师文化,新人融(xi)入(nao),这些都是我们经常会去讲,会去做的。那么作为喜欢追求极致的工程师们,能够容忍自己开发的系统有缺陷吗?至少应该以此为耻吧?新入职培训和熟悉业务阶段,是否可以专门设置相关课程?作为一个新人,至少应该看一看组织历史上都犯过哪些错误吧?不断沉淀一些相关案例,让成员们定期多去关注这些案例。自然就可以从中吸取一些教训,尤其哪些重复犯的错误,都应该被深深地记住。
写在后面
稳定性建设至关重要。
服务稳定性对于公司口碑,甚至是对其直接的商业利益都有重大影响。历史上血淋淋的宕机事件、安全事故比比皆是。不知这背后又有多少猿类内心和肉体上留下了挥之不去的烙印。
稳定性建设,对于系统设计,团队协同效率,程序员自身修养都提出了更高的要求。所以只要坚持投入,对于系统稳定性提升,团队整体战斗力提升和成员个人成长都是大有裨益的。
稳定性建设不好做,需要耐心。
1)稳定性建设很多时候都是在做保底线的事情。这就意味着,不出问题甲方(用户、老板、合作伙伴)基本没有人能感受到。他们关注到你的时候,大概率线上已经出了事故。所以,想得到大家的欣赏还是挺难的,如果想长期从事相关工作,得做好吃土的准备。不过一般很少有人专门做稳定性建设,更多是在自己开发交付过程中不断完善系统,使其更让人放心。
2)稳定性建设投入总是没保障。我们总是(尤其是在业务初期)着急的开发着新的特性,迭代效率基本就是个无法妥协的事情。如果不咬牙坚持,付出额外的努力,根本就没法坚持。
3)稳定性建设涉及软件开发整个生命周期。想每个环节同时都做到理想状态几乎不可能。所以也意味着他是个慢功夫,甚至刚开始时候很容易犯左倾冒进主义错误,后期又无法坚持长期斗争。从上到下得有耐心才可能做得更好。