这篇文章,我们来聊一下最近这一两年行业内Java高级工程师面试的时候尤为常见的一个问题:谈谈你对分布式搜索引擎的理解,聊聊他的架构原理?
很多同学可能从来没接触过这个东西,所以本文我们就以现在最火最流行的Elasticsearch为例,来聊一下分布式搜索引擎的核心架构原理。
一、倒排索引到底是啥?
要了解分布式搜索引擎,先了解一下搜索这个事儿吧,搜索这个技术领域里最入门级别的一个概念就是倒排索引。
我们先简单说一下倒排索引是个什么东西。
假如说你现在不用搜索引擎,单纯使用数据库来存放和搜索一些数据,比如说放了一些论坛的帖子数据吧,那么这个数据的格式大致如下:
id | title | content |
1 | Java好用吗? | Java是非常非常好的一门语言。。。。 |
2 | 大家一起来学Java | 我这儿有一些很好的Java学习资源,比如说。。。 |
3 | 一次Java面试经验 | 去年这个时候,我学了Java,今年开始了面试。。。 |
很简单吧,假设有一个id字段标识了每个帖子数据,然后title字段是帖子的标题,content字段是帖子的内容。
那么这个时候,比如我们要是用数据库来进行搜索包含“Java”这个关键字的所有帖子,大致SQL如下:

咱们姑且不论这个数据库层面也有支持全文检索的一些特殊索引类型,或者数据库层面是怎么执行的,这个不是本文讨论的重点,你就看看数据库的数据格式以及搜索的方式就好了。
但是如果你通过搜索引擎类的技术来存放帖子的内容,他是可以建立倒排索引的。
也就是说,你把上述的几行数据放到搜索引擎里,这个倒排索引的数据大致看起来如下:
关键词 id
- Java [1, 2, 3]
- 语言 [1]
- 面试 [3]
- 资源 [2]
所谓的倒排索引,就是把你的数据内容先分词,每句话分成一个一个的关键词,然后记录好每个关键词对应出现在了哪些id标识的数据里。
那么你要搜索包含“Java”关键词的帖子,直接扫描这个倒排索引,在倒排索引里找到“Java”这个关键词对应的那些数据的id就好了。
然后你可以从其他地方根据这几个id找到对应的数据就可以了,这个就是倒排索引的数据格式以及搜索的方式,上面这种利用倒排索引查找数据的方式,也被称之为全文检索。
二、什么叫做分布式搜索引擎?
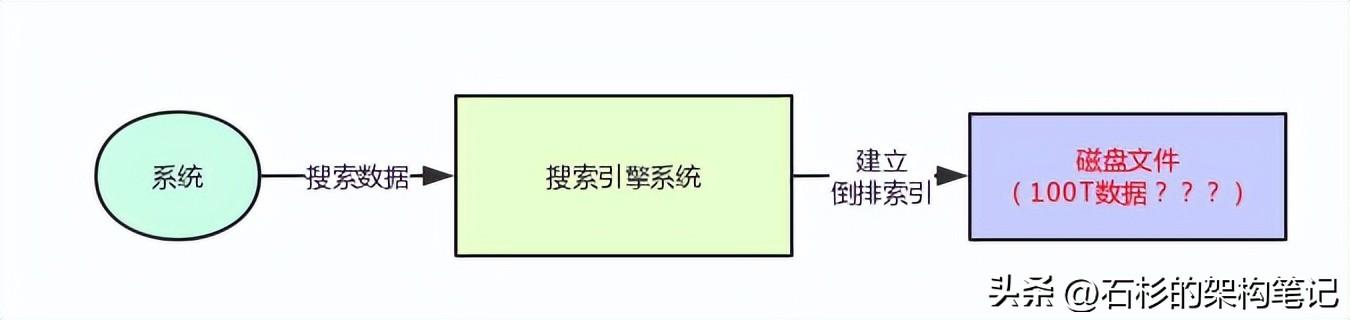
其实要知道什么叫做分布式搜索引擎,你首先得知道,假如我们就用一台机器部署一个搜索引擎系统,然后利用上述的那种倒排索引来存储数据,同时支持一些全文检索之类的搜索功能,那么会有什么问题?
其实还是很简单,假如说你现在要存储1TB的数据,那么放在一台机器还是可以的。
但是如果你要存储超过10TB,100TB,甚至1000TB的数据呢?你用一台机器放的下吗?
当然是放不下的了,你的机器磁盘空间是不够的。
大家看一下下面的图:
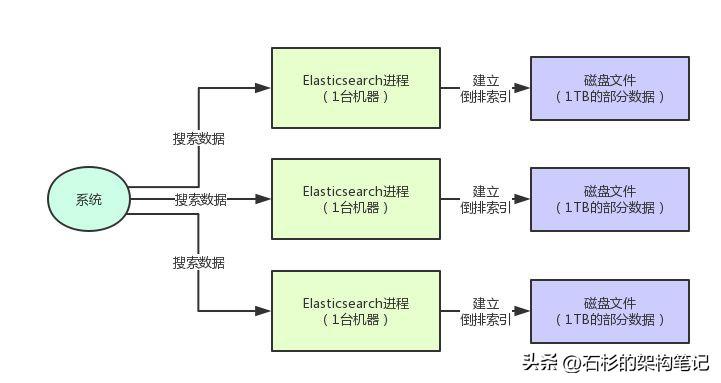
所以这个时候,你就得用分布式搜索引擎了,也就是要使用多台机器来部署搜索引擎集群。
比如说,假设你用的是Elasticsearch(后面简写为:ES)。
现在你总共有3TB的数据,那么你搞3台机器,每台机器上部署一个ES进程,管理那台机器上的1TB数据就可以了。
这样不就可以把3TB的数据分散在3台机器上来存储了?这不就是索引数据的分布式存储吗?
而且,你在搜索数据的时候,不就可以利用3台机器来对分布式存储后的数据进行搜索了?每台机器上的ES进程不都可以对一部分数据搜索?这不就是分布式的搜索?
是的,这就是所谓的分布式搜索引擎:把大量的索引数据拆散成多块,每台机器放一部分,然后利用多台机器对分散之后的数据进行搜索,所有操作全部是分布在多台机器上进行,形成了完整的分布式的架构。
同样,我们来看下面的图,直观的感受一下。
三、Elasticsearch的数据结构
如果你要是使用Elasticsearch这种分布式搜索引擎,必须要熟悉他的一些专业的技术名词,描述他的一些数据结构。
比如说“index”这个东西,他是索引的意思,其实他有点类似于数据库里的一张表,大概对应表的那个概念。
比如你搞一个专门存放帖子的索引,然后他有id、title、content几个field,这个field大致就是他的一个字段。
然后还有一个概念,就是document,这个就代表了index中的一条数据。
下面就是一个document,这个document可以写到index里去,算是index里的一条数据。
而且写到es之后,这条数据的内容就会拆分为倒排索引的数据格式来存储。
id | title | content |
1 | Java好用吗? | Java是非常非常好的一门语言。。。。 |
四、Shard数据分片机制
那么这个时候大家考虑一下,比如说你有一个index,专门存放论坛里的帖子,现在论坛里的帖子有1亿,占用了1TB的磁盘空间,这个还好说。
如果这个帖子有10亿,100亿,占用了10TB、甚至100TB的磁盘空间呢?
那你这个index的数据还能在一台机器上存储吗?答案明显是不能的。
这个时候,你必须得支持这个index的数据分布式存储在多台机器上,利用多台机器的磁盘空间来承载这么大的数据量。
而且,需要保证每台机器上对这个index存储的数据量不要太大,因为控制单台机器上这个index的数据量,可以保证他的搜索性能更高。
所以这里就引入了一个概念:Shard数据分片结构。每个index你都可以指定创建多少个shard,每个shard就是一个数据分片,会负责存储这个index的一部分数据。
比如说index里有3亿帖子,占据3TB数据。然后这个index你设置了3个shard。
那么每个shard就可以包含一个1TB大小的数据分片,每个shard在集群里的一台机器上,这样就形成了利用3台机器来分布式存储一个index的数据的效果了。
大家看下面的图:
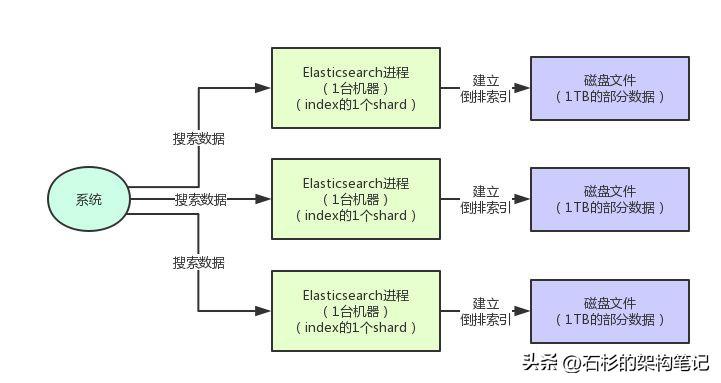
现在index里的3TB数据分布式存储在了3台机器上,每台机器上有一个shard,每个shard负责管理这个index的其中1TB数据的分片。
而且,另外一个好处是,假设我们要对这个index的3TB数据运行一个搜索,是不是可以发送请求到3台机器上去?
3台机器上的shard直接可以分布式的并行对一部分数据进行搜索,起到一个分布式搜索的效果,大幅度提升海量数据的搜索性能和吞吐量。
五、Replica多副本数据冗余机制
但是现在有一个问题,假如说3台机器中的其中一台宕机了,此时怎么办呢?
是不是这个index的3TB数据的1/3就丢失了?因为上面有1TB的数据分片没了。
所以说,还需要为了实现高可用使用Replica多副本数据冗余机制。
在Elasticsearch里,就是支持对每个index设置一个replica数量的,也就是每个shard对应的replica副本的数量。
比如说你现在一个index有3个shard,你设置对每个shard做1个replica副本,那么此时每个shard都会有一个replica shard。
这个初始的shard就是primary shard,而且primary shard和replica shard是绝对不会放在一台机器上的,避免一台机器宕机直接一个shard的副本也同时丢失了。
我们再来看下面的图,感受一下:
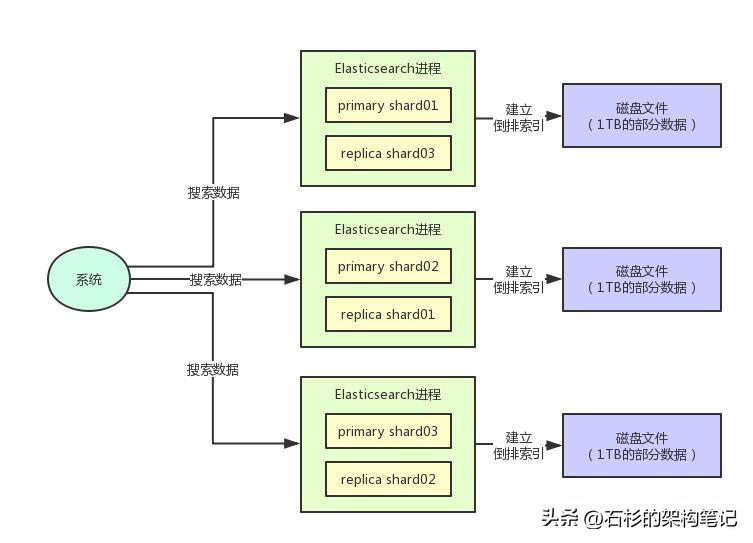
在上述的replica机制下,每个primary shard都有一个replica shard在别的机器上,任何一台机器宕机,都可以保证数据不会丢失,分布式搜索引擎继续可用。
Elasticsearch默认是支持每个index是5个primary shard,每个primary shard有1个replica shard作为副本。
六、文末总结
好了,本文到这儿就结束了,再来给大伙简单小结。
我们从搜索引擎的倒排索引开始,到单机无法承载海量数据,再到分布式搜索引擎的存储和搜索。
然后我们以优秀的分布式搜索引擎ES为例,阐述了ES的数据结构,shard数据分片机制,replica多副本机制,解释了一下分布式搜索引擎的架构原理。
最后还是强调一下,在Java面试尤其是高级Java面试中,对于分布式搜索引擎技术的考察越来越重,所以这块技术的重要性,还是不容小觑的!