时间序列数据是一种在一段时间内收集的数据类型,它通常用于金融、经济学和气象学等领域,经常通过分析来了解随着时间的推移的趋势和模式
Pandas是Python中一个强大且流行的数据操作库,特别适合处理时间序列数据。它提供了一系列工具和函数可以轻松加载、操作和分析时间序列数据。
在本文中,我们介绍时间序列数据的索引和切片、重新采样和滚动窗口计算以及其他有用的常见操作,这些都是使用Pandas操作时间序列数据的关键技术。
数据类型 Python 在Python中,没有专门用于表示日期的内置数据类型。一般情况下都会使用datetime模块提供的datetime对象进行日期时间的操作。
复制 import datetime
t = datetime .datetime .now ()
print (f "type: {type(t)} and t: {t}" )
#type : < class 'datetime.datetime' > and t : 2022 - 12 - 26 14 :20 :51.278230 一般情况下我们都会使用字符串的形式存储日期和时间。所以在使用时我们需要将这些字符串进行转换成datetime对象。
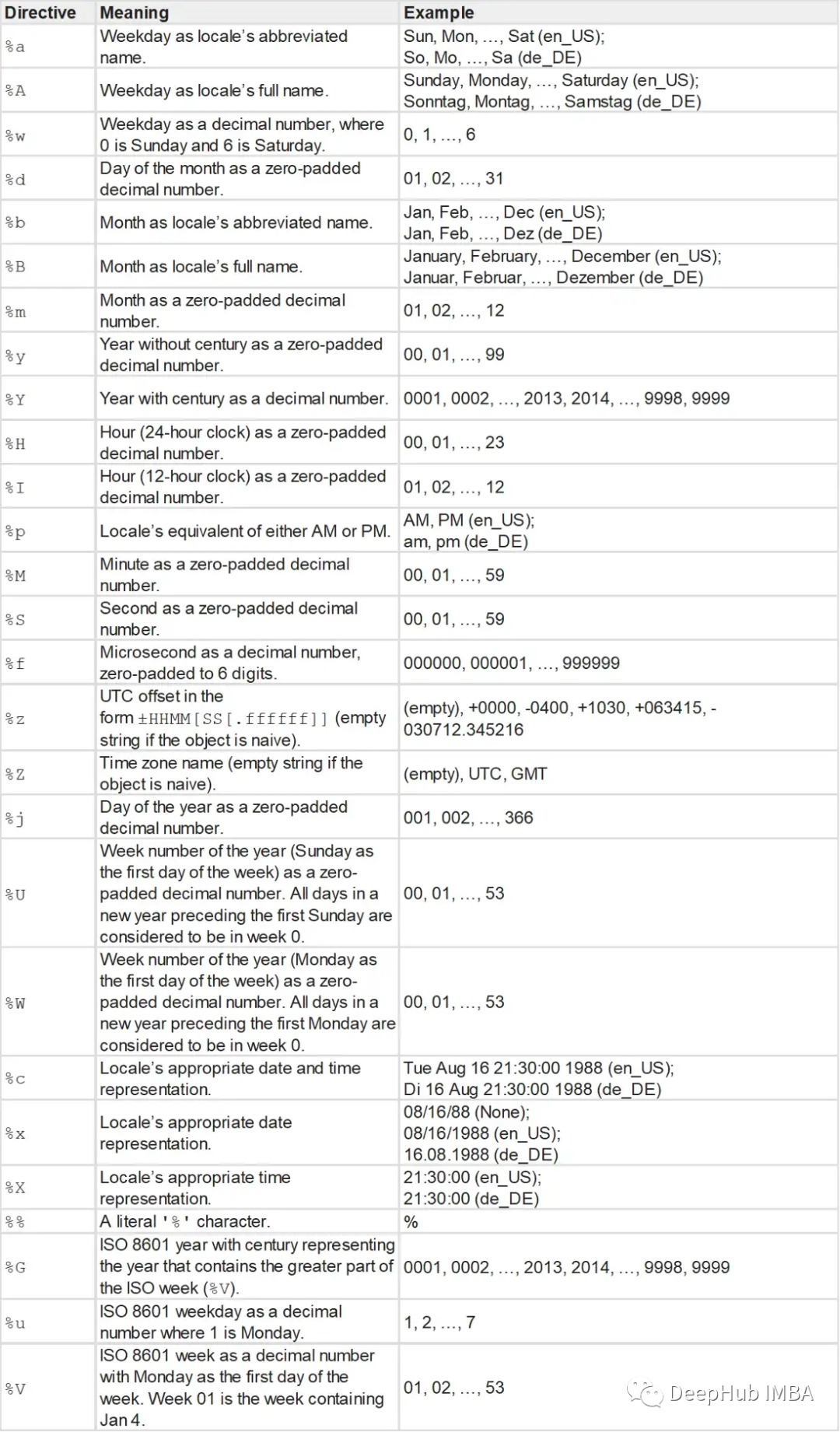
一般情况下时间的字符串有以下格式:
YYYY-MM-DD (e.g. 2022-01-01) YYYY/MM/DD (e.g. 2022/01/01) DD-MM-YYYY (e.g. 01-01-2022) DD/MM/YYYY (e.g. 01/01/2022) MM-DD-YYYY (e.g. 01-01-2022) MM/DD/YYYY (e.g. 01/01/2022) HH:MM:SS (e.g. 11:30:00) HH:MM:SS AM/PM (e.g. 11:30:00 AM) HH:MM AM/PM (e.g. 11:30 AM) strptime 函数以字符串和格式字符串作为参数,返回一个datetime对象。
复制 string = '2022-01-01 11:30:09'
t = datetime .datetime .strptime (string , "%Y-%m-%d %H:%M:%S" )
print (f "type: {type(t)} and t: {t}" )
#type : < class 'datetime.datetime' > and t : 2022 - 01 - 01 11 :30 :09 格式字符串如下:
还可以使用strftime函数将datetime对象转换回特定格式的字符串表示。
复制 t = datetime .datetime .now ()
t_string = t .strftime ("%m/%d/%Y, %H:%M:%S" )
#12 / 26 / 2022 , 14 :38 :47
t_string = t .strftime ("%b/%d/%Y, %H:%M:%S" )
#Dec / 26 / 2022 , 14 :39 :32 Unix时间(POSIX时间或epoch时间)是一种将时间表示为单个数值的系统。它表示自1970年1月1日星期四00:00:00协调世界时(UTC)以来经过的秒数。
Unix时间和时间戳通常可以互换使用。Unix时间是创建时间戳的标准版本。一般情况下使用整数或浮点数据类型用于存储时间戳和Unix时间。
我们可以使用time模块的mktime方法将datetime对象转换为Unix时间整数。也可以使用datetime模块的fromtimestamp方法。
复制 #convert datetime to unix time
import time
from datetime import datetime
t = datetime .now ()
unix_t = int (time .mktime (t .timetuple ()))
#1672055277
#convert unix time to datetime
unix_t = 1672055277
t = datetime .fromtimestamp (unix_t )
#2022 - 12 - 26 14 :47 :57 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 使用dateutil模块来解析日期字符串获得datetime对象。
复制 from dateutil import parser
date = parser .parse ("29th of October, 1923" )
#datetime .datetime (1923 , 10 , 29 , 0 , 0 )Pandas Pandas提供了三种日期数据类型:
1、Timestamp或DatetimeIndex:它的功能类似于其他索引类型,但也具有用于时间序列操作的专门函数。
复制 t = pd .to_datetime ("29/10/1923" , dayfirst = True )
#Timestamp ('1923-10-29 00:00:00' )
t = pd .Timestamp ('2019-01-01' , tz = 'Europe/Berlin' )
#Timestamp ('2019-01-01 00:00:00+0100' , tz = 'Europe/Berlin' )
t = pd .to_datetime (["04/23/1920" , "10/29/1923" ])
#DatetimeIndex (['1920-04-23' , '1923-10-29' ], dtype = 'datetime64[ns]' , freq = None )2、period或PeriodIndex:一个有开始和结束的时间间隔。它由固定的间隔组成。
复制 t = pd .to_datetime (["04/23/1920" , "10/29/1923" ])
period = t .to_period ("D" )
#PeriodIndex (['1920-04-23' , '1923-10-29' ], dtype = 'period[D]' )3、Timedelta或TimedeltaIndex:两个日期之间的时间间隔。
复制 delta = pd .TimedeltaIndex (data = ['1 days 03:00:00' ,
'2 days 09:05:01.000030' ])
"" "
TimedeltaIndex (['1 days 02:00:00' , '1 days 06:05:01.000030' ],
dtype = 'timedelta64[ns]' , freq = None )
"" " 在Pandas中,可以使用to_datetime方法将对象转换为datetime数据类型或进行任何其他转换。
复制 import pandas as pd
df = pd .read_csv ("dataset.txt" )
df .head ()
"" "
date value
0 1991 - 07 - 01 3.526591
1 1991 - 08 - 01 3.180891
2 1991 - 09 - 01 3.252221
3 1991 - 10 - 01 3.611003
4 1991 - 11 - 01 3.565869
"" "
df .info ()
"" "
< class 'pandas.core.frame.DataFrame' >
RangeIndex : 204 entries , 0 to 203
Data columns (total 2 columns ):
# Column Non - Null Count Dtype
-- - -- -- -- -- -- -- -- -- -- -- -- -- -
0 date 204 non - null object
1 value 204 non - null float64
dtypes : float64 (1 ), object (1 )
memory usage : 3.3 + KB
"" "
# Convert to datetime
df ["date" ] = pd .to_datetime (df ["date" ], format = "%Y-%m-%d" )
df .info ()
"" "
< class 'pandas.core.frame.DataFrame' >
RangeIndex : 204 entries , 0 to 203
Data columns (total 2 columns ):
# Column Non - Null Count Dtype
-- - -- -- -- -- -- -- -- -- -- -- -- -- -
0 date 204 non - null datetime64 [ns ]
1 value 204 non - null float64
dtypes : datetime64 [ns ](1 ), float64 (1 )
memory usage : 3.3 KB
"" "
# Convert to Unix
df ['unix_time' ] = df ['date' ].apply (lambda x : x .timestamp ())
df .head ()
"" "
date value unix_time
0 1991 - 07 - 01 3.526591 678326400.0
1 1991 - 08 - 01 3.180891 681004800.0
2 1991 - 09 - 01 3.252221 683683200.0
3 1991 - 10 - 01 3.611003 686275200.0
4 1991 - 11 - 01 3.565869 688953600.0
"" "
df ["date_converted_from_unix" ] = pd .to_datetime (df ["unix_time" ], unit = "s" )
df .head ()
"" "
date value unix_time date_converted_from_unix
0 1991 - 07 - 01 3.526591 678326400.0 1991 - 07 - 01
1 1991 - 08 - 01 3.180891 681004800.0 1991 - 08 - 01
2 1991 - 09 - 01 3.252221 683683200.0 1991 - 09 - 01
3 1991 - 10 - 01 3.611003 686275200.0 1991 - 10 - 01
4 1991 - 11 - 01 3.565869 688953600.0 1991 - 11 - 01
"" " 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56. 57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 我们还可以使用parse_dates参数在任何文件加载时直接声明日期列。
复制 df = pd .read_csv ("dataset.txt" , parse_dates = ["date" ])
df .info ()
"" "
< class 'pandas.core.frame.DataFrame' >
RangeIndex : 204 entries , 0 to 203
Data columns (total 2 columns ):
# Column Non - Null Count Dtype
-- - -- -- -- -- -- -- -- -- -- -- -- -- -
0 date 204 non - null datetime64 [ns ]
1 value 204 non - null float64
dtypes : datetime64 [ns ](1 ), float64 (1 )
memory usage : 3.3 KB
"" " 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 如果是单个时间序列的数据,最好将日期列作为数据集的索引。
复制 df .set_index ("date" ,inplace = True )
"" "
Value
date
1991 - 07 - 01 3.526591
1991 - 08 - 01 3.180891
1991 - 09 - 01 3.252221
1991 - 10 - 01 3.611003
1991 - 11 - 01 3.565869
... ...
2008 - 02 - 01 21.654285
2008 - 03 - 01 18.264945
2008 - 04 - 01 23.107677
2008 - 05 - 01 22.912510
2008 - 06 - 01 19.431740
"" " 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. Numpy也有自己的datetime类型np.Datetime64。特别是在大型数据集时,向量化是非常有用的,应该优先使用。
复制 import numpy as np
arr_date = np .array ('2000-01-01' , dtype = np .datetime64 )
arr_date
#array ('2000-01-01' , dtype = 'datetime64[D]' )
#broadcasting
arr_date = arr_date + np .arange (30 )
"" "
array (['2000-01-01' , '2000-01-02' , '2000-01-03' , '2000-01-04' ,
'2000-01-05' , '2000-01-06' , '2000-01-07' , '2000-01-08' ,
'2000-01-09' , '2000-01-10' , '2000-01-11' , '2000-01-12' ,
'2000-01-13' , '2000-01-14' , '2000-01-15' , '2000-01-16' ,
'2000-01-17' , '2000-01-18' , '2000-01-19' , '2000-01-20' ,
'2000-01-21' , '2000-01-22' , '2000-01-23' , '2000-01-24' ,
'2000-01-25' , '2000-01-26' , '2000-01-27' , '2000-01-28' ,
'2000-01-29' , '2000-01-30' ], dtype = 'datetime64[D]' )
"" " 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 有用的函数 下面列出的是一些可能对时间序列有用的函数。
复制 df = pd .read_csv ("dataset.txt" , parse_dates = ["date" ])
df ["date" ].dt .day_name ()
"" "
0 Monday
1 Thursday
2 Sunday
3 Tuesday
4 Friday
...
199 Friday
200 Saturday
201 Tuesday
202 Thursday
203 Sunday
Name : date , Length : 204 , dtype : object
"" " 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. DataReader Pandas_datareader是pandas库的一个辅助库。它提供了许多常见的金融时间序列数据。
复制 #pip install pandas - datareader
from pandas_datareader import wb
#GDP per Capita From World Bank
df = wb .download (indicator = 'NY.GDP.PCAP.KD' ,
country = ['US' , 'FR' , 'GB' , 'DK' , 'NO' ], start = 1960 , end = 2019 )
"" "
NY .GDP .PCAP .KD
country year
Denmark 2019 57203.027794
2018 56563.488473
2017 55735.764901
2016 54556.068955
2015 53254.856370
... ...
United States 1964 21599.818705
1963 20701.269947
1962 20116.235124
1961 19253.547329
1960 19135.268182
[300 rows x 1 columns ]
"" " 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 日期范围 我们可以使用pandas的date_range方法定义一个日期范围。
复制 pd .date_range (start = "2021-01-01" , end = "2022-01-01" , freq = "D" )
"" "
DatetimeIndex (['2021-01-01' , '2021-01-02' , '2021-01-03' , '2021-01-04' ,
'2021-01-05' , '2021-01-06' , '2021-01-07' , '2021-01-08' ,
'2021-01-09' , '2021-01-10' ,
...
'2021-12-23' , '2021-12-24' , '2021-12-25' , '2021-12-26' ,
'2021-12-27' , '2021-12-28' , '2021-12-29' , '2021-12-30' ,
'2021-12-31' , '2022-01-01' ],
dtype = 'datetime64[ns]' , length = 366 , freq = 'D' )
"" "
pd .date_range (start = "2021-01-01" , end = "2022-01-01" , freq = "BM" )
"" "
DatetimeIndex (['2021-01-29' , '2021-02-26' , '2021-03-31' , '2021-04-30' ,
'2021-05-31' , '2021-06-30' , '2021-07-30' , '2021-08-31' ,
'2021-09-30' , '2021-10-29' , '2021-11-30' , '2021-12-31' ],
dtype = 'datetime64[ns]' , freq = 'BM' )
"" "
fridays = pd .date_range ('2022-11-01' , '2022-12-31' , freq = "W-FRI" )
"" "
DatetimeIndex (['2022-11-04' , '2022-11-11' , '2022-11-18' , '2022-11-25' ,
'2022-12-02' , '2022-12-09' , '2022-12-16' , '2022-12-23' ,
'2022-12-30' ],
dtype = 'datetime64[ns]' , freq = 'W-FRI' )
"" " 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29.
我们可以使用timedelta_range方法创建一个时间序列。
复制 t = pd .timedelta_range (0 , periods = 10 , freq = "H" )
"" "
TimedeltaIndex (['0 days 00:00:00' , '0 days 01:00:00' , '0 days 02:00:00' ,
'0 days 03:00:00' , '0 days 04:00:00' , '0 days 05:00:00' ,
'0 days 06:00:00' , '0 days 07:00:00' , '0 days 08:00:00' ,
'0 days 09:00:00' ],
dtype = 'timedelta64[ns]' , freq = 'H' )
"" " 格式化 我们dt.strftime方法改变日期列的格式。
复制 df ["new_date" ] = df ["date" ].dt .strftime ("%b %d, %Y" )
df .head ()
"" "
date value new_date
0 1991 - 07 - 01 3.526591 Jul 01 , 1991
1 1991 - 08 - 01 3.180891 Aug 01 , 1991
2 1991 - 09 - 01 3.252221 Sep 01 , 1991
3 1991 - 10 - 01 3.611003 Oct 01 , 1991
4 1991 - 11 - 01 3.565869 Nov 01 , 1991
"" " 解析 解析datetime对象并获得日期的子对象。
复制 df ["year" ] = df ["date" ].dt .year
df ["month" ] = df ["date" ].dt .month
df ["day" ] = df ["date" ].dt .day
df ["calendar" ] = df ["date" ].dt .date
df ["hour" ] = df ["date" ].dt .time
df .head ()
"" "
date value year month day calendar hour
0 1991 - 07 - 01 3.526591 1991 7 1 1991 - 07 - 01 00 :00 :00
1 1991 - 08 - 01 3.180891 1991 8 1 1991 - 08 - 01 00 :00 :00
2 1991 - 09 - 01 3.252221 1991 9 1 1991 - 09 - 01 00 :00 :00
3 1991 - 10 - 01 3.611003 1991 10 1 1991 - 10 - 01 00 :00 :00
4 1991 - 11 - 01 3.565869 1991 11 1 1991 - 11 - 01 00 :00 :00
"" " 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 还可以重新组合它们。
复制 df ["date_joined" ] = pd .to_datetime (df [["year" ,"month" ,"day" ]])
print (df ["date_joined" ])
"" "
0 1991 - 07 - 01
1 1991 - 08 - 01
2 1991 - 09 - 01
3 1991 - 10 - 01
4 1991 - 11 - 01
...
199 2008 - 02 - 01
200 2008 - 03 - 01
201 2008 - 04 - 01
202 2008 - 05 - 01
203 2008 - 06 - 01
Name : date_joined , Length : 204 , dtype : datetime64 [ns ]1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 过滤查询 使用loc方法来过滤DataFrame。
复制 df = df .loc ["2021-01-01" :"2021-01-10" ]
truncate 可以查询两个时间间隔中的数据
复制 df_truncated = df .truncate ('2021-01-05' , '2022-01-10' )
常见数据操作 下面就是对时间序列数据集中的值执行操作。我们使用yfinance库创建一个用于示例的股票数据集。
复制 #get google stock price data
import yfinance as yf
start_date = '2020-01-01'
end_date = '2023-01-01'
ticker = 'GOOGL'
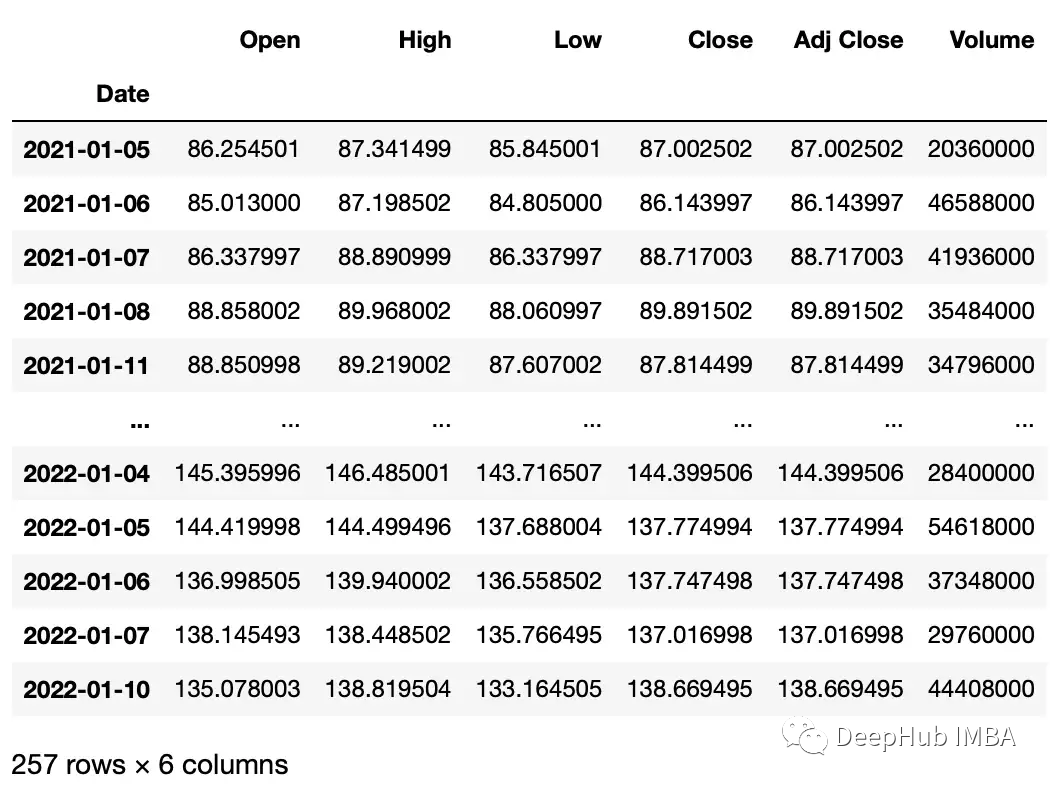
df = yf .download (ticker , start_date , end_date )
df .head ()
"" "
Date Open High Low Close Adj Close Volume
2020 - 01 - 02 67.420502 68.433998 67.324501 68.433998 68.433998 27278000
2020 - 01 - 03 67.400002 68.687500 67.365997 68.075996 68.075996 23408000
2020 - 01 - 06 67.581497 69.916000 67.550003 69.890503 69.890503 46768000
2020 - 01 - 07 70.023003 70.175003 69.578003 69.755501 69.755501 34330000
2020 - 01 - 08 69.740997 70.592499 69.631500 70.251999 70.251999 35314000
"" " 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 计算差值 diff函数可以计算一个元素与另一个元素之间的插值。
复制 #subtract that day 's value from the previous day
df ["Diff_Close" ] = df ["Close" ].diff ()
#Subtract that day 's value from the day' s value 2 days ago
df ["Diff_Close_2Days" ] = df ["Close" ].diff (periods = 2 )
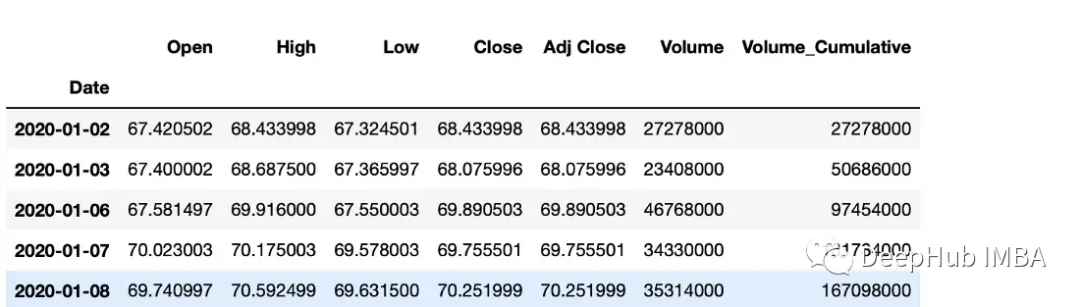
累计总数 复制 df ["Volume_Cumulative" ] = df ["Volume" ].cumsum ()
滚动窗口计算 滚动窗口计算(移动平均线)。
复制 df ["Close_Rolling_14" ] = df ["Close" ].rolling (14 ).mean ()
df .tail ()
可以对我们计算的移动平均线进行可视化
常用的参数:
center:决定滚动窗口是否应以当前观测值为中心。 min_periods:窗口中产生结果所需的最小观测次数。 复制 s = pd .Series ([1 , 2 , 3 , 4 , 5 ])
#the rolling window will be centered on each observation
rolling_mean = s .rolling (window = 3 , center = True ).mean ()
"" "
0 NaN
1 2.0
2 3.0
3 4.0
4 NaN
dtype : float64
Explanation :
first window : [na 1 2 ] = na
second window : [1 2 3 ] = 2
"" "
# the rolling window will not be centered ,
#and will instead be anchored to the left side of the window
rolling_mean = s .rolling (window = 3 , center = False ).mean ()
"" "
0 NaN
1 NaN
2 2.0
3 3.0
4 4.0
dtype : float64
Explanation :
first window : [na na 1 ] = na
second window : [na 1 2 ] = na
third window : [1 2 3 ] = 2
"" " 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 平移 Pandas有两个方法,shift()和tshift(),它们可以指定倍数移动数据或时间序列的索引。Shift()移位数据,而tshift()移位索引。
复制 #shift the data
df_shifted = df .shift (5 ,axis = 0 )
df_shifted .head (10 )
#shift the indexes
df_tshifted = df .tshift (periods = 4 , freq = 'D' )
df_tshifted .head (10 )
df_shifted
df_tshifted
时间间隔转换 在 Pandas 中,操 to_period 函数允许将日期转换为特定的时间间隔。可以获取具有许多不同间隔或周期的日期
复制 df ["Period" ] = df ["Date" ].dt .to_period ('W' )
频率 Asfreq方法用于将时间序列转换为指定的频率。
复制 monthly_data = df .asfreq ('M' , method = 'ffill' )
常用参数:
freq:数据应该转换到的频率。这可以使用字符串别名(例如,'M'表示月,'H'表示小时)或pandas偏移量对象来指定。
method:如何在转换频率时填充缺失值。这可以是'ffill'(向前填充)或'bfill'(向后填充)之类的字符串。
采样 resample可以改变时间序列频率并重新采样。我们可以进行上采样(到更高的频率)或下采样(到更低的频率)。因为我们正在改变频率,所以我们需要使用一个聚合函数(比如均值、最大值等)。
resample方法的参数:
rule:数据重新采样的频率。这可以使用字符串别名(例如,'M'表示月,'H'表示小时)或pandas偏移量对象来指定。
复制 #down sample
monthly_data = df .resample ('M' ).mean ()
复制 #up sample
minute_data = data .resample ('T' ).ffill ()
百分比变化 使用pct_change方法来计算日期之间的变化百分比。
复制 df ["PCT" ] = df ["Close" ].pct_change (periods = 2 )
print (df ["PCT" ])
"" "
Date
2020 - 01 - 02 NaN
2020 - 01 - 03 NaN
2020 - 01 - 06 0.021283
2020 - 01 - 07 0.024671
2020 - 01 - 08 0.005172
...
2022 - 12 - 19 - 0.026634
2022 - 12 - 20 - 0.013738
2022 - 12 - 21 0.012890
2022 - 12 - 22 - 0.014154
2022 - 12 - 23 - 0.003907
Name : PCT , Length : 752 , dtype : float64
"" " 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 总结 在Pandas和NumPy等库的帮助下,可以对时间序列数据执行广泛的操作,包括过滤、聚合和转换。本文介绍的是一些在工作中经常遇到的常见操作,希望对你有所帮助。