一、背景
百度贴吧是一个拥有10多年历史的UGC产品,在业务迭代中难免会有很多业务逻辑的代码,其中一部分业务逻辑用if-else等硬编码的形式开发,一部分引入了配置文件,通过配置文件的规则去执行不同的业务逻辑。在某些运营活动或权益规则中,需要频繁增加或者更改一些规则,这部分规则经常变动的部分就需要规则引擎来统一管理。
规则引擎是一种专注于业务规则的服务,它可以将业务规则从代码中剥离出来,使用预先定义好的语义规范来实现这些剥离出来的业务规则。规则引擎通过接受输入的数据,进行业务规则的评估,并做出业务决策。
因为规则引擎将复杂的业务逻辑从业务代码中剥离出来,所以可以显著降低业务逻辑实现难度;同时,剥离的业务规则使用规则引擎实现,这样可以使多变的业务规则变的可维护,配合规则引擎提供的良好的业务规则设计器,不用编码就可以快速实现复杂的业务规则,同样,即使是完全不懂编程的运营或者产品人员,也可以使用图形化的界面来自定义规则,实现代码一样的效果。
下面对一些需要使用规则引擎的场景进行举例:
1.单规则迭代
用户标签->包含A关键词->权益A
用户标签->包含A关键词->权益A
->包含B关键词->权益B
用户标签->身份豁免策略/机器账号->包含A关键词->权益A
->包含B关键词->权益B
用户标签->A模型结果大于1 ->豁C类用户->包含A关键词->权益C
可见随着业务的发展,需要不断的调整权益规则,这部分如果硬编码写死在代码中,需要频繁上线,增加了工作量,并且随着业务逻辑的增多,后期维护成本增高。
2、持续接入新的能力
除了目前的字符串比较能力,一般的规则引擎还会接入各种各样的模型能力,一般通过RPC的形式请求不同的服务,随着接入的服务越来越多,可以组合的规则也是成倍的增长;
比如新接入图片模型识别后,所有图片识别的结果会过其他相关的模型,相关的模型调用逻辑就增加了一倍;
又如接入了某些模型,要根据模型的分数做相应的处理调整,需要频繁的改动分值对应的处置手段,同时为了应对突发的场景,也需要频繁的更改规则。
这些操作如果没有一个自动化的规则引擎,就需要把大量的规则逻辑写在代码里,经过长时间的迭代,规则变得非常臃肿,无论对后续的开发还是定位问题的效率都会带来问题。
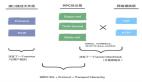
二、贴吧规则引擎组成部分
贴吧规则引擎要做到规则灵活可配,无需研发介入,就需要尽可能的把包含判断逻辑的部分全部下放到平台,通过平台的勾选对规则进行实现。

上图为规则引擎整体的模块划分,主要分为四部分:
组件服务:组件服务是对第三方服务的封装,比如调用图片模型服务、调用帖子属性等内容服务,一般是RPC调用;组件需要RD开发代码,但是贴吧规则引擎的组件调用不掺杂业 务逻辑,仅仅是定义一个函数function,通过函数的入参调用第三方服务返回结果;
变量平台:变量又称算子,是配置规则的参数;变量分为业务调用时传的入参、使用组件返回的结果等。贴吧规则引擎通过专用平台管理变量,RD和PM均可以在平台上配置变量;
规则引擎:规则引擎平台涉及到了具体每一条规则,通过图形化的界面生成规则,该平台不需要RD介入,通过平台化的操作生成具体的规则。
处置方法:该处置为RD定制化开发,针对帖子、用户或其他场景的召回处置处理。一般定义一个rpc请求回调相关业务,处置方法因为是场景定制化的,所以这部分需要研发介入开发,但是处置方法更新的频率非常低,一般都是复用已有的能力。
2.1 组件服务
规则引擎所有配置的数据不可能都是上游参数传递,很多是通过调用第三方服务获取;比如通过帖子id获取的帖子详情数据,通过用户uid获取用户的扩展属性,这里都需要调用第三方服务;
组件的开发非常简单,只需要声明一个函数,并实现其静态方法。为了后续的性能考虑,函数声明时可以指定sync(串行)、async(异步)、parallel(并行)三种执行方式,贴吧规则引擎会在调度的时候按照类型,使用更高效的方式执行对应的方法。

图中给出了一个demo组件,可以看出组件是不关注业务的,可以自定义入参和返回值,具体调用函数的入口及参数也不需要额外关注,更符合lib库或者util方法的实现方式,这种组件的好处是开发简单,解耦业务逻辑,增加组件的复用性,同时也降低了研发同学的工作量。
另外对于mode的工作模式,分为以下三类,具体的实现都是框架实现,组件的开发方不需要关注:
sync:同步调用,使用的时候串行执行,函数间是阻塞的;
async:异步调用,定义function的时候分为before、after两组方法。Before阶段为发起rpc请求,等待第三方服务回调后执行after方法,可以应对好耗时的服务接入。
parallel:并行模式,属于同一层级的parallel 函数并行执行,类似于多线程或者golang的goroutine模式,目前贴吧的规则引擎采用php开发,不具备多线程的相关能力,所以这里并行是在before组装rpc参数,通过curl_multi统一发起并行请求,在after函数取到结果。
以上能力在规则引擎框架上已经封装,组件的研发RD只需要关注PRC的实现即可,根据函数的定义框架实现并行或者异步的调用。
2.2 变量平台
变量或者算子就是规则引擎中做规则判断使用的参数,比如用户名、帖子id、用户等级、帖子内容、模型识别的结果等,这部分的内容越多,规则引擎可以创建规则的『素材』越多;
变量的来源分为三个部分:
(1)平台预定义的变量:比如一些常量数字或者特定字符串,这部分内容比较固定,变动较少。
(2)业务入参:业务在请求规则引擎的时候可以把尽可能多的参数变量传递过来,除了帖子、用户、吧相关的数据,还可以把用户ip、ua等各种数据一并传递,这些数据在变量的平台化界面上可以做简单的筛选或者摘取,生成新的变量。

如图举例:input是一个完成的业务请求的变量,取input中的title生成testTitle变量,这样就可以单独使用testTitle做一些规则上的判断。
(3)组件调用:在组件的部分已经定义了具体的方法,该方法类似于lib库或者util,具体的请求的入口在变量平台实现,入参就是其他变量。

如图举例:testRPC是定义的组件,其中入参是testTitle变量,返回的大结果作为一个testRPC变量。
后面可以对testRPC变量做具体的拆分,比如testRPC中的data.score作为一个单独的变量,用score这个变量做后面的规则定义。
整体来说,input是上游传过来的基础变量。对入参变量的整理和过滤可以生成额外的基础变量;使用基础参数(比如帖子id),通过rpc调用,可以生成扩展的结果;对结果的提取可以生成额外的第二级变量;进一步对二级变量继续调用服务,可以生成更多的变量:比如通过图片模型结果过一些文本模型,但是随着层级的变深,整体服务呈现多级依赖关系,这也增加了整体的系统耗时。

对于入参或者RPC请求结果的处理,全部可以在变量平台上进行操作,变量平台定义了规则引擎可以使用的变量及具体的实现方式。因为变量平台支持编辑代码,所以一般的变量都可以直接在变量平台编辑完成,而对相对复杂的模型调用,则可以封装通用的util方法,之后在变量平台直接使用这些方法。
2.3 规则引擎平台
组件是一个个简单的util静态方法,通过入参及调用组件生成扩展的变量;自此进行规则判断的『素材』准备好了,接下来需要使用这些变量配置规则,而核心的规则引擎平台就是使用这些变量,生成规则。
规则引擎目前支持的运算规则:
规则运算符:目前支持变量值与常量的比较,包含基本的>,<,>=,<=,==,!=多种比较方式;另外不仅可以直接使用变量,对于数组类型的变量,还可以直接使用了变量的计数count,对于string类型,可以使用变量的长度len做参数直接进行判断。
词表比较:判断某个词是否在词表中是一个比较常用的规则;规则引擎平台支持本地词表与远程词表;远程词表为了解决词表量级太大的问题。字符与词表的比较包括精确匹配,包含、不包含、前缀匹配及后缀匹配几种方式,基本覆盖了常见的使用方式。
粒度控制判断:为了判断某个调整在一段时间内的出现次数,平台支持配置变量的出现次数统计。对于某些使用频次较少的运算规则,平台不在功能上进行统一支持,但是可以通过修改变量来支持。比如想判断变量A的sin值大于Z,可以在变量平台新配置一个变量B,它的定位为sin(A),然后在规则引擎上使用B这个变量做判断,就解决了某些特殊的计算方式。对于判断逻辑,目前支持if条件判断,switch多分支判断,确定召回,确定豁免四种方式,基本囊括了常用的判断逻辑。

△简单的策略配置demo
2.4 处置方法
处置方法是针对不同的业务场景召回的个性化处置逻辑,这部分需要RD开发代码,做个性化的处理;比如命中召回后返回true or false或者命中的规则号或者回调特殊标记。
处置方法添加的频率不会很高,基本固定对帖子、用户或者各个场景有1-2个处置方法即可,后续的多个规则直接复用处置方法。
三、规则引擎实现原理
规则引擎最终生成是一个包含所有规则逻辑的代码块,代码块在规则引擎框架中运行;生成的代码块类似研发开发的代码:代码的逻辑依旧是定义变量、使用变量做条件判断(规则)、命中召回的处置。
1. 变量
这部分比较容易理解,就是2.2部分;将所有定义的变量取出来,当然因为变量之间是递归依赖的,所以当变量中需要其他变量时,会递归获取内容,直到获取常量或没有依赖为止,最后倒序输出为代码片段。
2. 规则文件生成
每一条规则在存储上都是一个json串,存储形式为一个nodeTree。其中一个node节点存储了类型:判断节点、召回节点、豁免节点以及多组(switch)判断节点。其中召回节点和豁免节点是程序判断的终止位置,当执行到召回节点时会加载规则引擎对应的处置方法。判断节点是整个规则引擎的核心,包含对应的变量与比较方式。其中比较方式有数字比较、字符串比较及词表比较。比如内容中是否包含关键词“AB”,则在判断节点上选取内容变量,比较方式为词表包含,词表内容为“AB”。
在规则文件的设计上,采用nodeTree的方式,既能方便后续扩展node的属性和类型,又通过父子节点树的方式多层级的表示复杂的if、switch逻辑,层级可以无限深。
在新的规则上线时,将nodeTree文件从数据库中全部导出,生成全部的规则文件。规则文件依赖的变量已经在变量文件中全部定义好,剩下的工作就是将变量与规则进行组装,生成最终的可执行代码。
另外对于某些特殊的需求,需要对白名单中的uid或者类型进行全部策略豁免。对于此类需求可以修改所有的规则,增加前置判断逻辑,但是此操作需要对现有的全部规则及增量规则都修改,且在规则执行中会增加额外的判断逻辑,增加整体规则引擎的执行耗时,所以除了普通的规则外,贴吧规则引擎增加了全局规则区。全局规则区相当于所有规则的前置条件,具体配置的规则为普通的node判断节点,当全局的所有规则判断均为true时才会依次执行具体的普通规则,这样对于想全局豁免的需求,只需要简单配置全局规则即可,不需要修改具体的详细规则。
3. 生成可执行规则文件
规则引擎的前期编译工作需要生成可以执行的代码,这部分就是将图形化配置的规则与变量进行组合,优化整体的代码执行逻辑,生成可执行的代码,将文件下发到所有的线上机器。
其中变量文件是可以执行的php语法,规则为导出的json文件,需要将不同类型的文件进行组合,这里需要将不同文件源转为同一种结构化数据。
对于原本是php语法的文件,贴吧规则引擎采用ply和yacc进行词法和语法的解析,对php语法中array、函数、赋值、条件判断、运算符等进行提取,转为结构化的数据。
对于规则文件,因为是预先定义好的json nodeTree,包含的格式是有限可枚举的,只要将每种类型与规则映射为结构化的字段,就可以将规则文件转位目标结构化数据。
之后就是可执行文件的生成过程,具体需要以下步骤:

语法树展开:通过递归调用,将函数嵌套展开。比如res = funA(funB($params))展开为 tmp1 = funB($params);res = funA(tmp1);展开后将高阶函数展开成普通函数,方便后续的优化处理。
接下来就是语句优化部分:
将不同变量重名的部分自动增加_n后缀,避免变量的相互覆盖;遍历整体规则中使用的变量,如果存在变量从未使用过,从整体代码中去除;对于定义了多遍重复的函数调用,整体去重只保留一份;对并行或者异步方法的函数组拆分成真正可执行的静态方法。经过以上步骤,对将要生成的最终规则文件进行了初步的整理及优化。
在组件服务中提到了异步函数async;对于某些耗时非常高的模型服务,异步函数的作用是触发调用后结束,等待第三方服务回调。
对于使用异步函数的情况,至少拆分成两步,第一步发起触发,第二步收到模型回调,取到该步骤的结果作为变量,所有依赖该变量的规则只能放到第二步执行。如果有函数依赖第二步的结果,则步骤会继续增加,该函数取某变量的异步结果,发起服务请求,第三步回调收到结果;异步函数展开的作用是将所有无依赖的异步函数请求方法统一放在一起,并行请求,通过回调触发执行第二步的规则逻辑。这样贴吧规则引擎可以很方便的接入高耗时的模型服务。
除了异步函数,还存在一种parallel并行调用的方式。由于规则引擎采用php的语言选型,没有其他语言方便的多线程或者协程调用方式,对于无依赖的函数不能支持并行调用,所以在规则引擎的设计上通过curl_multil并行rpc调用服务的形式来减少耗时。
目前比较耗时的函数一般是请求数据库服务或者第三方服务,这里将数据库及第三方的调用全部封装为http协议的形式,在策略文件调用上通过before方法整理入参,通过类似curl_multil的方法并行调用服务,取到结果后执行各自函数的after方法,整理函数对应的变量,这样就将无依赖关系的调用进行了并行处理,整体降低了耗时。并行函数合并就是框架层面做的自动化合并,规则引擎的研发同学只需要简单定义before和after方法,编译阶段就会自动将所有无依赖的函数before方法执行,组装rpc请求。如果某些函数在before阶段依赖其他服务的结果,那么这批函数将在第二次发起请求,即无任何依赖的函数先发起并行请求,依赖第一批结果的函数再发起第二次并行请求,以此类推,最大限度的使用并行调用的方式。

最终生成的可执行的文件,基本的最小单元为name、func、param、cond四组字段组成。如果cond判断条件为真,则name通过函数和入参数执行对应方法,产出值;该值又是其他单元的条件变量或者函数入参,这样由上到下依次执行,完成了所有规则的执行。
仍然以上述demo策略为例:

最终生成了四组单元,基本格式如下:

如图所示,基于上述的规则,只需要四组基本单元,每一组通过函数计算结果,下一组的条件依赖结果的值,如果走到“召回”逻辑,则进行表示规则命中,返回对应的规则号及其处置方法,框架中根据处置方法执行对应的逻辑。
每一个规则都是上述基本单元组成,最终将nodeTree中的全部规则生成基本单元,文件下发到所有运行的机器上,至此完成了规则文件的产出与规则上线。
四、总结
贴吧规则引擎搭配图形化的界面,非常方便非技术同学配置业务规则,将冗余的业务逻辑全部托管在规则引擎平台上,无需代码开发,即可上线或者修改规则。
另外框架层面将异步、并行等复杂逻辑进行了封装,研发同学调用新的模型只需要按照模版修改简单的参数整理及返回数据整理,即可完成并行或者异步的操作,减少规则引擎的执行耗时。对于变量结果的转换,也可以通过变量管理平台,在平台上简单的修改即可完成一些基本的整理逻辑,大大减少代码的开发量。
通过规则引擎,可以灵活配置运营活动中的抽奖规则、用户身份权益配置、商品价格等包含复杂业务逻辑判断的部分,将规则抽象出来,解放研发同学的人力,同时规则在平台上可以方便查找和定位,方便后续的维护。