stream()方法创建的是【串行流】也可以叫【顺序流】,由主线程按顺序对流执行操作,而 parallelStream()方法创建的是【并行流】,内部以多线程并行执行的方式对流进行操作,但前提是流中的数据处理没有顺序要求。
本文章为系列文章,上一篇《Stream案例体验》通过丰富的案例感受了Stream的便利,本篇主要讲解:
- Stream的运行流程,结合本篇和上一篇案例体会
- Stream的创建方式
- Stream的操作分类
- 串行流和并行流区别
Stream运行流程
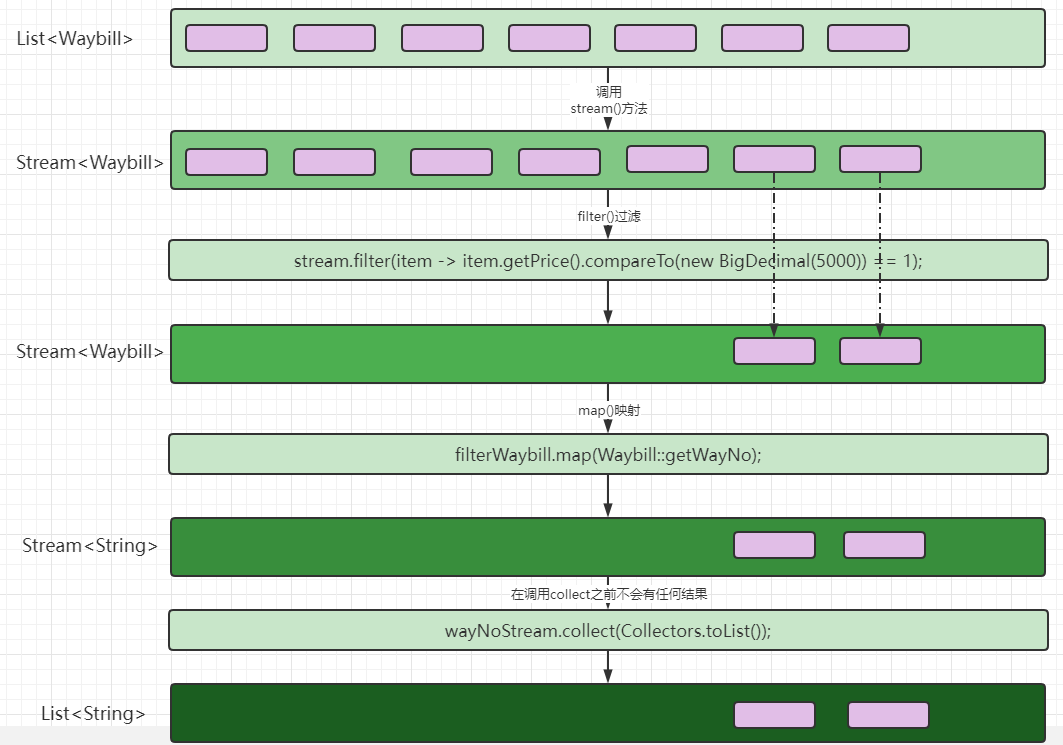
这里通过一个运费案例,通过 【代码实现】 +【 图解】解释清楚Stream计算数据时的流程!
需求:获取运单价格大于 5000元 的运单编号
分析:
- 创建运单数据
- 通过集合的stream方法创建流
- 再通过调用流对象的 filter方法过滤出需要的数据【中间操作】
- 再通过流对象的map方法获取想要的字段数据【中间操作】
- 在通过collect方法将流对象转换为集合,终止流【终止操作】
代码实现:
运单类可直接复用 《Stream案例体验》一篇
import java.math.BigDecimal;
import java.util.*;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class WaybillMain {
private static List<Waybill> waybills = new ArrayList<>();
static {
// 创建数据
waybills.add(new Waybill(1L,"Y11111111111",new BigDecimal(1000),"钢材",new BigDecimal(200),"上海市"));
waybills.add(new Waybill(2L,"Y22222222222",new BigDecimal(2000),"钢材",new BigDecimal(300),"郑州市"));
waybills.add(new Waybill(3L,"Y33333333333",new BigDecimal(3000),"水泥",new BigDecimal(300),"北京市"));
waybills.add(new Waybill(4L,"Y44444444444",new BigDecimal(4000),"水泥",new BigDecimal(400),"广州市"));
waybills.add(new Waybill(5L,"Y55555555555",new BigDecimal(5000),"沙子",new BigDecimal(500),"上海市"));
waybills.add(new Waybill(6L,"Y66666666666",new BigDecimal(6000),"板材",new BigDecimal(500),"深圳市"));
waybills.add(new Waybill(7L,"Y77777777777",new BigDecimal(7000),"蔬菜",new BigDecimal(500),"杭州市"));
}
public static void main(String[] args){
// 1、获取运费大于5000的运单编号
// 1) 通过集合的stream方法创建流
Stream<Waybill> stream = waybills.stream();
// 2) 通过 filter 方法筛选运单大于5000的运单
Stream<Waybill> filterWaybill = stream.filter(item -> item.getPrice().compareTo(new BigDecimal(5000)) == 1);
// 3) 获取筛选后的运单的编号
Stream<String> wayNoStream = filterWaybill.map(Waybill::getWayNo);
// 4) 将流转换为新的集合
List<String> wayNoList = wayNoStream.collect(Collectors.toList());
// 5) 遍历
wayNoList.forEach(System.out::println);
}
}
运行流程:
Stream操作分类
上节我们说,Stream的操作分为两大类,【中间操作】和【结束操作】,这里详细介绍一下

无状态:元素的处理不受之前元素影响,比如:过滤,映射,转换类型
有状态:该元素只有拿到所有元素之后才能继续下去,比如排序,去重
非短路操作:必须处理完所有元素才能得到结果,比如:求最值,遍历
短路操作:遇到某些符合条件的元素就可以得到最终结果,比如:获取第一个出现的数据
Stream创建
流可以用来处理数组、集合、IO资源等数据,而且分为【串行流】和【并行流】两种,它的创建方式主要分为以下几种:
使用Collection下的stream() 方法【串行流】和parallelStream() 方法【并行流】
List<String> list = Arrays.asList("a", "b", "c");
// 创建一个顺序流
Stream<String> stream = list.stream();
// 创建一个并行流
Stream<String> parallelStream = list.parallelStream();使用Arrays中的stream() 方法,将数组转换为流
int[] array={1,3,5,6,8};
IntStream stream = Arrays.stream(array);使用Stream中的静态方法:of()、iterate()、generate()
对于iterate和generate这种没有数据长度的流称为【无限流】,需要使用limit()来指定流长度
比如generate是生成数据,生成多少数据?需要使用limit指定
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6);
// 参数1:为起始值
// 参数2:每次的值进行什么操作,再基于结果做下一次的运算
// limit:最多4次操作
List<Integer> iterate = Stream.iterate(1, x -> x * 3).limit(4).collect(Collectors.toList());
System.out.println(iterate);
// 生成 3 个随机数
Stream<Double> limit = Stream.generate(Math::random).limit(3);
limit.forEach(System.out::println);
使用 BufferedReader.lines() 方法,将每行内容转成流
BufferedReader reader = new BufferedReader(new FileReader("D:\\stream.txt"));
Stream<String> lineStream = reader.lines();
lineStream.forEach(System.out::println);使用 Pattern.splitAsStream() 方法,将字符串分隔成流
Pattern pattern = Pattern.compile(",");
Stream<String> stringStream = pattern.splitAsStream("a,b,c,d");
stringStream.forEach(System.out::println);串行流和并行流区别
stream()方法创建的是【串行流】也可以叫【顺序流】,由主线程按顺序对流执行操作,而 parallelStream()方法创建的是【并行流】,内部以多线程并行执行的方式对流进行操作,但前提是流中的数据处理没有顺序要求。例如筛选集合中的奇数,两者的处理不同之处:
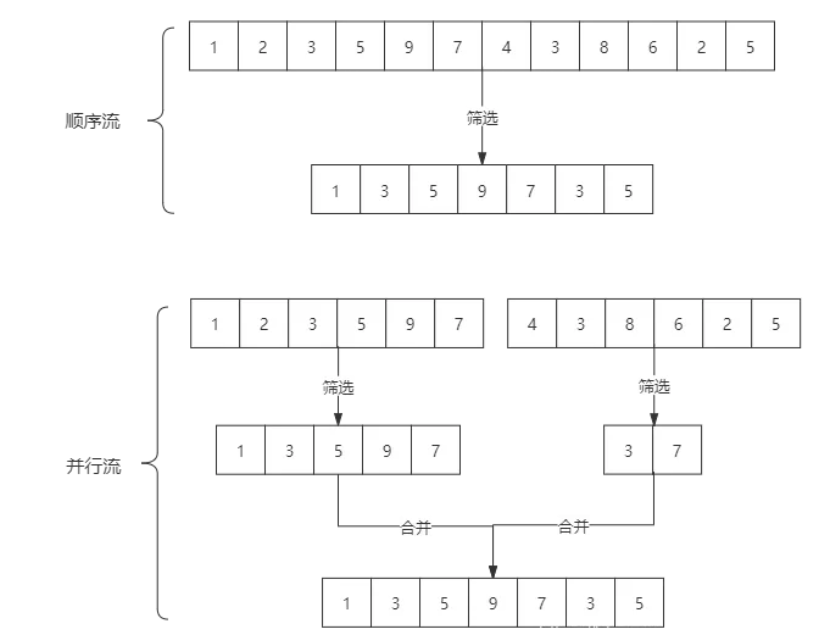
如果流中的数据量足够大,并行流可以加快处速度。
除了直接创建并行流,还可以通过 parallel()把顺序流转换成并行流:
// 创建数组
Integer[] arr = {1,2,3,4,5,6,7,8,9,10};
// 通过 stream 转换为串行流,再通过 Stream 对象的 parallel 方法转换为并行流
Stream<Integer> integerStream = Arrays.stream(arr).parallel();
// 计算,并行流只能对无顺序要求的计算生效
// mao:对每一个数据 * 2
List<Integer> list = integerStream.map(x -> x * 2).collect(Collectors.toList());
list.forEach(System.out::println);


























