模拟电路是可以利用三极管的导通 / 截止的状态切换,来实现数字逻辑的。
最简单的数字逻辑有3种:与、或、非。
这种简单的数字电路叫门电路。
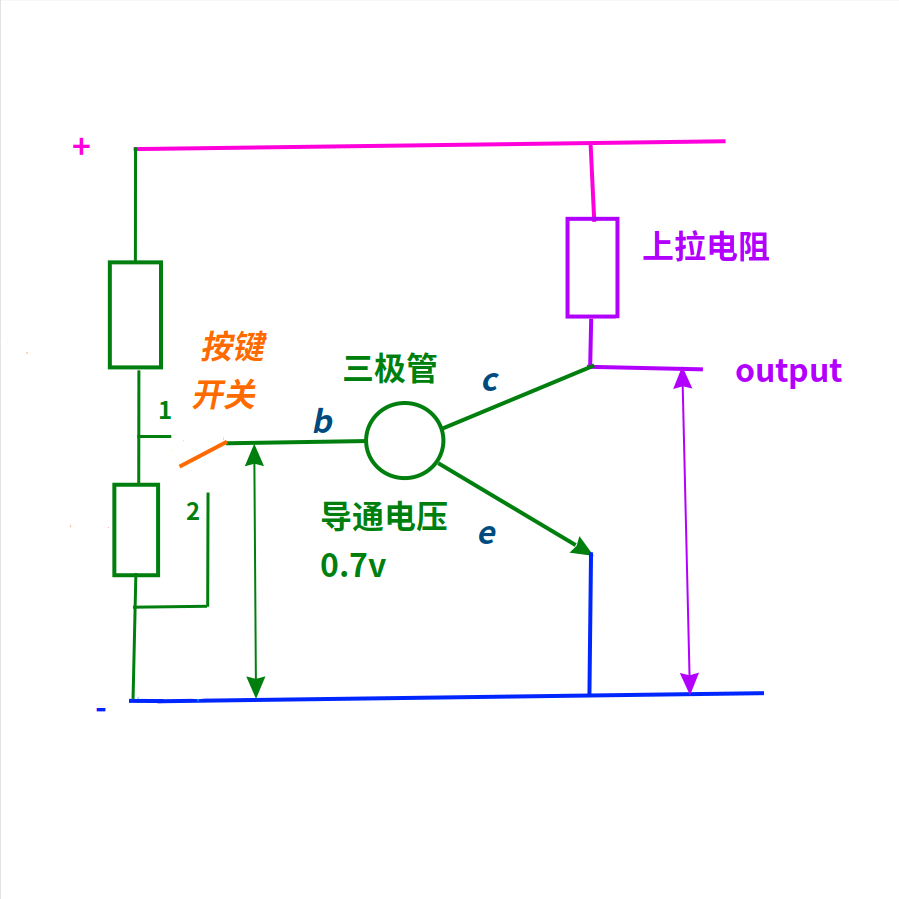
非门
最简单的非门,就是使用一个三极管和一个电阻。
最简单的与门,是使用两个二极管和一个电阻。
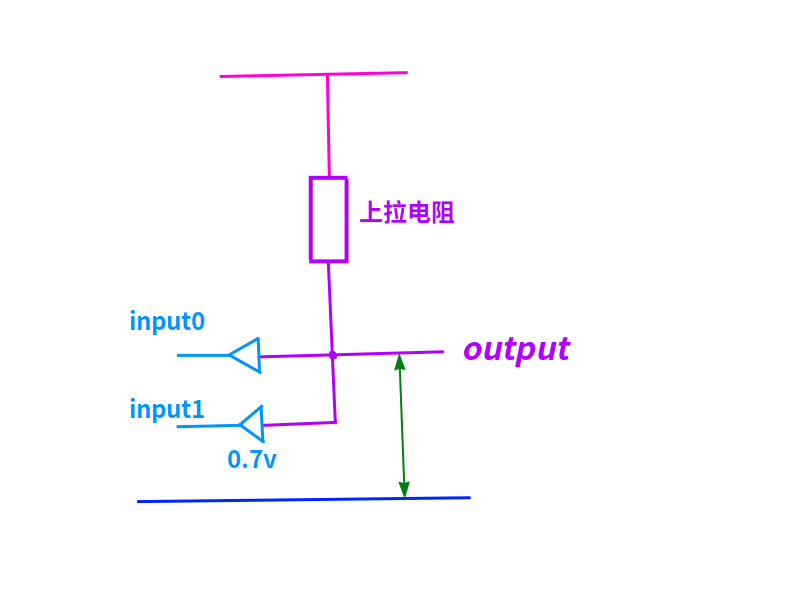
与门
如上图,2个二极管只要有一个(与电源负极)导通时,输出端的电压就是0.7v,为低电位。
2个二极管都截止时,输出端的电压等于电源电压,为高电位。
只使用三极管的b-e两极时,三极管就相当于二极管。
这些简单的门电路,都可以用来处理一个二进制位的运算,即位运算。
1.位运算
位运算,是比加减乘除更简单的运算。
在位运算时,一个数的多个二进制位之间是不相关的。
所以,只要把32个上图的电路并联起来,就可以处理32位的位运算。
2.加减运算
加法和减法因为有进位和借位,它们的多个二进制位之间是相关的。
所以,加法和减法的电路实现是比较复杂的,乘法和除法更复杂。
但是,加减乘除运算都是可以用电路实现的。
(这里就不展开了,否则又得写一大篇)
3.C语言
在位运算和加减乘除的基础上,就可以实现一门编程语言了。
逻辑运算(&&, ||, !),就是1个二进制位的位运算。
比较运算(>, <, ==, !=, >=, <=),实际比较的是运算结果与0的大小。
2 > 1 比较的是 2 - 1 > 0,
0可以用1个二进制位表示,所以比较运算实际上也是加减运算+位运算。
if / else,就是逻辑运算。
while / for,就是个复杂点的if / else:
它会根据条件跳转到循环开头或结尾,而if / else不会跳转到开头,就这么点区别。
位运算、加减乘除、逻辑、比较、if else、while for,一门编程语言的主要运算也就这些。
当然,从数字计算机的出现到C语言的诞生,中间还隔了20多年的时间,经历了机器语言、汇编语言,上古高级语言3个阶段。
C语言从出现到现在,已经用了50年了,依然宝刀未老
C语言之后的编程语言,基本都是在C语言的基础上修修补补。
例如:C++添加了OOP机制;
java又在C++的基础上做了一些简化,并且把运行平台从CPU搬到了jvm虚拟机,实现了跨平台;
go语言除了有点古怪的语法之外,又差不多回到了C语言的最初设计,并且添加了协程。
现在,人们在编程语言上能够做的改进已经比较少了,更多的是顺应程序员的习惯。
所以,有个编译器大牛好几年前就说过:编程语言是程序员的“宗教战争”。
所以,php是最好的编程语言
4.unix系统
C语言出现之后,丹尼斯-里奇和肯-汤普森马上就用它重写了unix系统。
这是C语言被发明的主要目的,和第一个应用。
丹尼斯-里奇在unix系统的设计模式,成了后来操作系统的典范。
unix说,“一切皆是文件”。
包括Linux在内的泛unix系的操作系统,都遵循了这一原则,而且API高度相同。
但是,API这个词是从“异端”windows那里来的。
unix / linux 的API学名叫系统调用(syscall),但因为2000年前后微软巨大的影响了,都被叫成了API。
并且,windows把文件的描述结构叫句柄,linux叫文件描述符,现在很多linux程序员也把文件描述符叫句柄。
毕竟,windows XP在代表了一个时代!
操作系统、数据库、编译器,是传统的三大基础软件。
在1970年,unix和C语言出现之后,美国巨头们就迅速垄断了这三大领域。
不过,人类的科技发展,从来都是想重新发明自己!
怎么让电脑像人一样的看东西,是科学家们从1980年之后的研究重点。
5.计算机视觉
让电脑去识别图像的技术,叫计算机视觉,英文缩写CV.
CV的大概可以分为两步:
1)目标检测,即把目标位置从背景图片里画出来,
2)目标识别,识别画出来的目标是什么。

人脸识别
把人的面部从图片中框出来,就是人脸检测:常用的算法是Haar小波分类器。
识别框出来的人脸是谁,就是人脸识别:常用的算法是CNN,它是深度学习的一种模型。
在深度学习出现之前,人们经常使用传统算法的组合去识别图像。
例如:
高斯模糊,可以平滑掉图像中的一些斑点。
拉普拉斯变换,可以检测图像的边缘。
形态学膨胀,可以把一大片邻近的点连成一块区域:在文字识别中常用这个算法。
文字是一种边缘特别突出的图形,与自然物体的差异很大,所以拉普拉斯变化之后文字区域非常的明显。
但是在阀值分隔之后,这个区域往往形成一些密集而不连续的点:
经过形态学膨胀之后,这些点就连成了一块,可以求它的外接矩形了;
外接矩形,基本上就可以框出文字所在的区域;
然后,就可以根据特征去识别了。
对人脸的识别,也是先框出所在的区域,然后根据特征去识别。
传统算法经常使用的是特征点检测+分类器:
SIFT算法用来检测特征点,SVM支持向量机用来对特征点分类,SIFT+SVM曾经是深度学习出现之前使用最多的CV算法。
当然,SIFT+SVM的效果也就那样,毕竟它们都是非常死板的固定算法,适用场景有限。
在2006年,辛顿提出深度学习之前,CV算法对复杂场景的识别率一直不高。
虽然传统算法在数学上都是可解释的,但识别率是硬伤。
深度学习的参数虽然难以解释,但它的识别率比传统算法高得多。
这十几年来,深度学习基本一统了CV领域。
深度学习的入门,所需要的数学知识并不多,学过高数和线代的都能很快入门。