













Pandas是Python中最著名的数据分析工具。在处理数据集时,每个人都会使用到它。但是随着数据大小的增加,执行某些操作的某些方法会比其他方法花费更长的时间。所以了解和使用更快的方法非常重要,特别是在大型数据集中,本文将介绍一些使用Pandas处理大数据时的技巧,希望对你有所帮助。

数据生成
为了方便介绍,我们生成一些数据作为演示,faker是一个生成假数据的Python包。这里我们直接使用它。
import random
from faker import Faker
fake = Faker()
car_brands = ["Audi","Bmw","Jaguar","Fiat","Mercedes","Nissan","Porsche","Toyota", None]
tv_brands = ["Beko", "Lg", "Panasonic", "Samsung", "Sony"]
def generate_record():
""" generates a fake row
"""
cid = fake.bothify(text='CID-###')
name = fake.name()
age=fake.random_number(digits=2)
city = fake.city()
plate = fake.license_plate()
job = fake.job()
company = fake.company()
employed = fake.boolean(chance_of_getting_true=75)
social_security = fake.boolean(chance_of_getting_true=90)
healthcare = fake.boolean(chance_of_getting_true=95)
iban = fake.iban()
salary = fake.random_int(min=0, max=99999)
car = random.choice(car_brands)
tv = random.choice(tv_brands)
record = [cid, name, age, city, plate, job, company, employed,
social_security, healthcare, iban, salary, car, tv]
return record
record = generate_record()
print(record)
"""
['CID-753', 'Kristy Terry', 5877566, 'North Jessicaborough', '988 XEE',
'Engineer, control and instrumentation', 'Braun, Robinson and Shaw',
True, True, True, 'GB57VOOS96765461230455', 27109, 'Bmw', 'Beko']
"""
我们创建了一个100万行的DF。
import os
import pandas as pd
from multiprocessing import Pool
N= 1_000_000
if __name__ == '__main__':
cpus = os.cpu_count()
pool = Pool(cpus-1)
async_results = []
for _ in range(N):
async_results.append(pool.apply_async(generate_record))
pool.close()
pool.join()
data = []
for i, async_result in enumerate(async_results):
data.append(async_result.get())
df = pd.DataFrame(data=data, columns=["CID", "Name", "Age", "City", "Plate", "Job", "Company",
"Employed", "Social_Security", "Healthcare", "Iban",
"Salary", "Car", "Tv"])

磁盘IO
Pandas可以使用不同的格式保存DF。让我们比较一下这些格式的速度。
#Write
%timeit df.to_csv("df.csv")
#3.77 s ± 339 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit df.to_pickle("df.pickle")
#948 ms ± 13.1 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit df.to_parquet("df")
#2.77 s ± 13 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit df.to_feather("df.feather")
#368 ms ± 19.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
def write_table(df):
dtf = dt.Frame(df)
dtf.to_csv("df_.csv")
%timeit write_table(df)
#559 ms ± 10.1 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)

#Read
%timeit df=pd.read_csv("df.csv")
#1.89 s ± 22.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit df=pd.read_pickle("df.pickle")
#402 ms ± 6.96 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit df=pd.read_parquet("df")
#480 ms ± 3.62 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit df=pd.read_feather("df.feather")
#754 ms ± 8.31 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
def read_table():
dtf = dt.fread("df.csv")
df = dtf.to_pandas()
return df
%timeit df = read_table()
#869 ms ± 29.8 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
CSV格式是运行最慢的格式。在这个比较中,我有包含Excel格式(read_excel),因为它更慢,并且还要安装额外的包。
在使用CSV进行的操作中,首先建议使用datatable库将pandas转换为datatable对象,并在该对象上执行读写操作这样可以得到更快的结果。
但是如果数据可控的话建议直接使用pickle 。
数据类型
在大型数据集中,我们可以通过强制转换数据类型来优化内存使用。
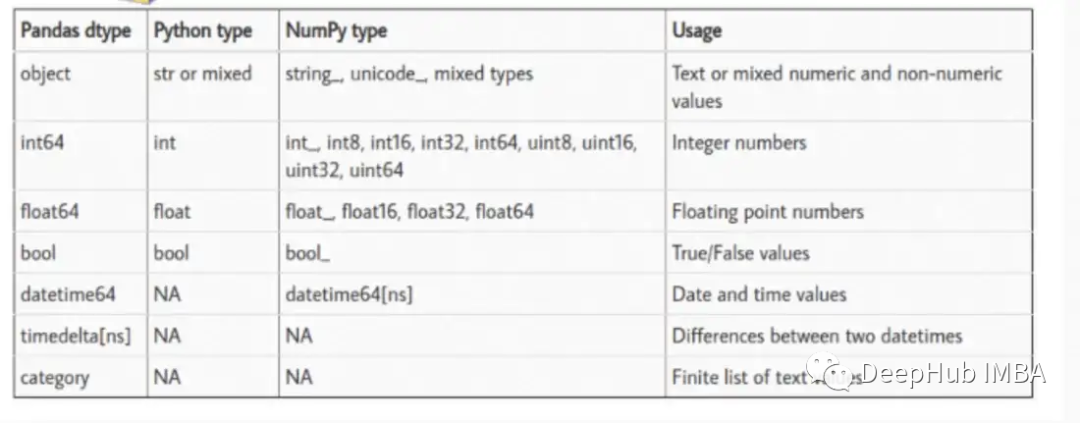
例如,通过检查数值特征的最大值和最小值,我们可以将数据类型从int64降级为int8,它占用的内存会减少8倍。
df.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000000 entries, 0 to 999999
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 CID 1000000 non-null object
1 Name 1000000 non-null object
2 Age 1000000 non-null int64
3 City 1000000 non-null object
4 Plate 1000000 non-null object
5 Job 1000000 non-null object
6 Company 1000000 non-null object
7 Employed 1000000 non-null bool
8 Social_Security 1000000 non-null bool
9 Healthcare 1000000 non-null bool
10 Iban 1000000 non-null object
11 Salary 1000000 non-null int64
12 Car 888554 non-null object
13 Tv 1000000 non-null object
dtypes: bool(3), int64(2), object(9)
memory usage: 86.8+ MB
"""
我们根据特征的数值范围对其进行相应的转换,例如AGE特征的范围在0到99之间,可以将其数据类型转换为int8。
#int
df["Age"].memory_usage(index=False, deep=False)
#8000000
#convert
df["Age"] = df["Age"].astype('int8')
df["Age"].memory_usage(index=False, deep=False)
#1000000
#float
df["Salary_After_Tax"] = df["Salary"] * 0.6
df["Salary_After_Tax"].memory_usage(index=False, deep=False)
#8000000
df["Salary_After_Tax"] = df["Salary_After_Tax"].astype('float16')
df["Salary_After_Tax"].memory_usage(index=False, deep=False)
#2000000
#categorical
df["Car"].memory_usage(index=False, deep=False)
#8000000
df["Car"] = df["Car"].astype('category')
df["Car"].memory_usage(index=False, deep=False)
#1000364
或者在文件读取过程中直接指定数据类型。
dtypes = {
'CID' : 'int32',
'Name' : 'object',
'Age' : 'int8',
...
}
dates=["Date Columns Here"]
df = pd.read_csv(dtype=dtypes, parse_dates=dates)
查询过滤
常规过滤方法:
%timeit df_filtered = df[df["Car"] == "Mercedes"]
#61.8 ms ± 2.55 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
对于分类特征,我们可以使用pandas的group_by和get_group方法。
%timeit df.groupby("Car").get_group("Mercedes")
#92.1 ms ± 4.38 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
df_grouped = df.groupby("Car")
%timeit df_grouped.get_group("Mercedes")
#14.8 ms ± 167 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
分组的操作比正常应用程序花费的时间要长。如果要对分类特征进行很多过滤操作,例如在本例中,如果我们从头进行分组,并且只看get_group部分的执行时间,我们将看到该过程实际上比常规方法更快。也就是说,对于重复的过滤操作,我们可以首选此方法(get_group)。
计数
Value_counts方法比groupby和following size方法更快。
%timeit df["Car"].value_counts()
#49.1 ms ± 378 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
"""
Toyota 111601
Porsche 111504
Jaguar 111313
Fiat 111239
Nissan 110960
Bmw 110906
Audi 110642
Mercedes 110389
Name: Car, dtype: int64
"""
%timeit df.groupby("Car").size()
#64.5 ms ± 37.9 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
"""
Car
Audi 110642
Bmw 110906
Fiat 111239
Jaguar 111313
Mercedes 110389
Nissan 110960
Porsche 111504
Toyota 111601
dtype: int64
"""
迭代
在大容量数据集上迭代需要很长时间。所以有必要在这方面选择最快的方法。我们可以使用Pandas的iterrows和itertuples方法,让我们将它们与常规的for循环实现进行比较。
def foo_loop(df):
total = 0
for i in range(len(df)):
total += df.iloc[i]['Salary']
return total
%timeit foo_loop(df)
#34.6 s ± 593 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
def foo_iterrows(df):
total = 0
for index, row in df.iterrows():
total += row['Salary']
return total
%timeit foo_iterrows(df)
#22.7 s ± 761 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
def foo_itertuples(df):
total = 0
for row in df.itertuples():
total += row[12]
return total
%timeit foo_itertuples(df)
#1.22 s ± 14.8 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Iterrows方法比for循环更快,但itertuples方法是最快的。
另外就是Apply方法允许我们对DF中的序列执行任何函数。
def foo(val):
if val > 50000:
return "High"
elif val <= 50000 and val > 10000:
return "Mid Level"
else:
return "Low"
df["Salary_Category"] = df["Salary"].apply(foo)
print(df["Salary_Category"])
"""
0 High
1 High
2 Mid Level
3 High
4 Low
...
999995 High
999996 Low
999997 High
999998 High
999999 Mid Level
Name: Salary_Category, Length: 1000000, dtype: object
"""
%timeit df["Salary_Category"] = df["Salary"].apply(foo)
#112 ms ± 50.6 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
def boo():
liste = []
for i in range(len(df)):
val = foo(df.loc[i,"Salary"])
liste.append(val)
df["Salary_Category"] = liste
%timeit boo()
#5.73 s ± 130 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
而map方法允许我们根据给定的函数替换一个Series中的每个值。
print(df["Salary_Category"].map({'High': "H", "Mid Level": "M", "Low": "L"}))
"""
0 H
1 H
2 M
3 H
4 L
..
999995 H
999996 L
999997 H
999998 H
999999 M
Name: Salary_Category, Length: 1000000, dtype: object
"""
print(df["Salary_Category"].map("Salary Category is {}".format))
"""
0 Salary Category is High
1 Salary Category is High
2 Salary Category is Mid Level
3 Salary Category is High
4 Salary Category is Low
...
999995 Salary Category is High
999996 Salary Category is Low
999997 Salary Category is High
999998 Salary Category is High
999999 Salary Category is Mid Level
Name: Salary_Category, Length: 1000000, dtype: object
"""
df["Salary_Category"] = df["Salary"].map(foo)
print(df["Salary_Category"])
"""
0 High
1 High
2 Mid Level
3 High
4 Low
...
999995 High
999996 Low
999997 High
999998 High
999999 Mid Level
Name: Salary_Category, Length: 1000000, dtype: object
让我们比较一下标对salary 列进行标准化工时每一中迭代方法的时间吧。
min_salary = df["Salary"].min()
max_salary = df["Salary"].max()
def normalize_for_loc(df, min_salary, max_salary):
normalized_salary = np.zeros(len(df, ))
for i in range(df.shape[0]):
normalized_salary[i] = (df.loc[i, "Salary"] - min_salary) / (max_salary - min_salary)
df["Normalized_Salary"] = normalized_salary
return df
%timeit normalize_for_loc(df, min_salary, max_salary)
#5.45 s ± 15.1 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
def normalize_for_iloc(df, min_salary, max_salary):
normalized_salary = np.zeros(len(df, ))
for i in range(df.shape[0]):
normalized_salary[i] = (df.iloc[i, 11] - min_salary) / (max_salary - min_salary)
df["Normalized_Salary"] = normalized_salary
return df
%timeit normalize_for_iloc(df, min_salary, max_salary)
#13.8 s ± 29.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
def normalize_for_iloc(df, min_salary, max_salary):
normalized_salary = np.zeros(len(df, ))
for i in range(df.shape[0]):
normalized_salary[i] = (df.iloc[i]["Salary"] - min_salary) / (max_salary - min_salary)
df["Normalized_Salary"] = normalized_salary
return df
%timeit normalize_for_iloc(df, min_salary, max_salary)
#34.8 s ± 108 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
def normalize_for_iterrows(df, min_salary, max_salary):
normalized_salary = np.zeros(len(df, ))
i = 0
for index, row in df.iterrows():
normalized_salary[i] = (row["Salary"] - min_salary) / (max_salary - min_salary)
i += 1
df["Normalized_Salary"] = normalized_salary
return df
%timeit normalize_for_iterrows(df, min_salary, max_salary)
#21.7 s ± 53.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
def normalize_for_itertuples(df, min_salary, max_salary):
normalized_salary = list()
for row in df.itertuples():
normalized_salary.append((row[12] - min_salary) / (max_salary - min_salary))
df["Normalized_Salary"] = normalized_salary
return df
%timeit normalize_for_itertuples(df, min_salary, max_salary)
#1.34 s ± 4.29 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
def normalize_map(df, min_salary, max_salary):
df["Normalized_Salary"] = df["Salary"].map(lambda x: (x - min_salary) / (max_salary - min_salary))
return df
%timeit normalize_map(df, min_salary, max_salary)
#178 ms ± 970 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
def normalize_apply(df, min_salary, max_salary):
df["Normalized_Salary"] = df["Salary"].apply(lambda x: (x - min_salary) / (max_salary - min_salary))
return df
%timeit normalize_apply(df, min_salary, max_salary)
#182 ms ± 1.83 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
def normalize_vectorization(df, min_salary, max_salary):
df["Normalized_Salary"] = (df["Salary"] - min_salary) / (max_salary - min_salary)
return df
%timeit normalize_vectorization(df, min_salary, max_salary)
#1.58 ms ± 7.87 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
可以看到:
loc比iloc快。
- 如果你要使用iloc,那么最好使用这样df.iloc[i, 11]的格式。
- Itertuples比loc更好,iterrows确差不多。
- Map和apply是第二种更快的选择。
- 向量化的操作是最快的。
向量化
向量化操作需要定义一个向量化函数,该函数接受嵌套的对象序列或numpy数组作为输入,并返回单个numpy数组或numpy数组的元组。
def foo(val, min_salary, max_salary):
return (val - min_salary) / (max_salary - min_salary)
foo_vectorized = np.vectorize(foo)
%timeit df["Normalized_Salary"] = foo_vectorized(df["Salary"], min_salary, max_salary)
#154 ms ± 310 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
#conditional
%timeit df["Old"] = (df["Age"] > 80)
#140 µs ± 11.8 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
#isin
%timeit df["Old"] = df["Age"].isin(range(80,100))
#17.4 ms ± 466 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
#bins with digitize
%timeit df["Age_Bins"] = np.digitize(df["Age"].values, bins=[0, 18, 36, 54, 72, 100])
#12 ms ± 107 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
print(df["Age_Bins"])
"""
0 3
1 5
2 4
3 3
4 5
..
999995 4
999996 2
999997 3
999998 1
999999 1
Name: Age_Bins, Length: 1000000, dtype: int64
"""
索引
使用.at方法比使用.loc方法更快。
%timeit df.loc[987987, "Name"]
#5.05 µs ± 33.3 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
%timeit df.at[987987, "Name"]
#2.39 µs ± 23.3 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
Swifter
Swifter是一个Python包,它可以比常规的apply方法更有效地将任何函数应用到DF。
!pip install swifter
import swifter
#apply
%timeit df["Normalized_Salary"] = df["Salary"].apply(lambda x: (x - min_salary) / (max_salary - min_salary))
#192 ms ± 9.08 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
#swifter.apply
%timeit df["Normalized_Salary"] = df["Salary"].swifter.apply(lambda x: (x - min_salary) / (max_salary - min_salary))
#83.5 ms ± 478 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
总结
如果可以使用向量化,那么任何操作都应该优先使用它。对于迭代操作可以优先使用itertuples、apply或map等方法。还有一些单独的Python包,如dask、vaex、koalas等,它们都是构建在pandas之上或承担类似的功能,也可以进行尝试。



















