












协程(coroutine),是为了把epoll异步事件变成同步的一种编程模式。
它的出现也就近几年的事,是随着go语言而提出的一种编程模式。
因为异步事件编程的可读性比较差,然后就有了协程。
协程,也被称为用户态的进程。
协程的调度,跟Linux内核对进程的调度是类似的。
1,不管是协程、进程、线程,它们都有一个要运行的函数,以及相关的上下文。
函数是它们要运行的代码,上下文是它们的运行状态。
pthread库对线程函数的定义是void* (*run)(void*),它是一个参数和返回值都是void*的函数指针:
这么定义的线程函数,可以给它传递任何类型的参数,也可以从它获取任何类型的返回值。
这个函数,就是线程要运行的函数。
如果是进程的话,main()函数就是它要运行的进程函数。
任何不使用fork()系统调用的进程,都是从main()函数开始运行的。
fork()系统调用之后的(父)子进程,会运行fork()返回之后的代码,例如:
协程也跟进程、线程类似,也有一个要运行的函数。
另外,无论进程、线程、协程都有一个运行的状态上下文:
这个上下文里最重要的数据,就是栈!
Linux内核的进程的内存布局
函数的局部变量是分配在栈上的,函数调用的返回地址也是在栈上的,各种寄存器也是保存在栈上的。
对于一个正在运行的函数来说,栈必须是独立的,不能与其他函数共享:因为运行着的函数会随时修改栈上的数据。
不管是线程、进程、协程,都是这样。
同一个进程内的不同线程之间虽然会共享全局变量和堆内存,但栈是不能共享的。
在Linux上,线程和进程除了共享全局变量和堆之外,基本上是一回事。
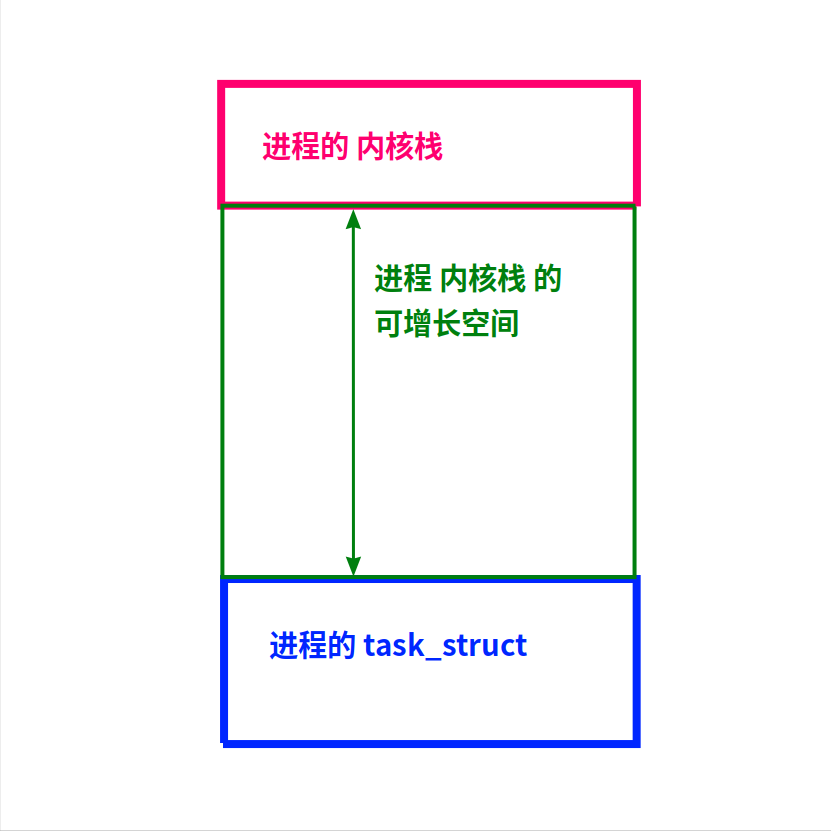
在Linux内核里,它们都用上图的数据结构描述:
1)最早是4096字节(1个内存页),后来扩展到8k字节(2个页)。
2)这8k内存的低地址是进程的描述结构,也就是main()函数运行时需要的信息。
这8k内存的高地址,是进程在内核里运行时(例如执行系统调用时)的(内核)栈。
这两部分加起来,就是进程的上下文。
所以,在给Linux内核写模块时,代码里不能使用很大的局部变量,以免把进程的描述结构给覆盖了!
这样的代码是不能写在内核里的,因为局部变量的内存是分配在栈上的,而内核给每个进程配备的栈都很小(8k)。
这一个buf数组就占了4k,那函数调用稍微复杂一点,就可能把低地址的进程结构给覆盖了。
Linux内核在调度进程的时候,就是不断地切换上图的数据结构,从而让多个进程可以交替运行。
因为调度间隔远小于人眼能察觉的时间间隔,所以即使在单核CPU上,在人看来也是多进程同时运行的。
2,协程的实现
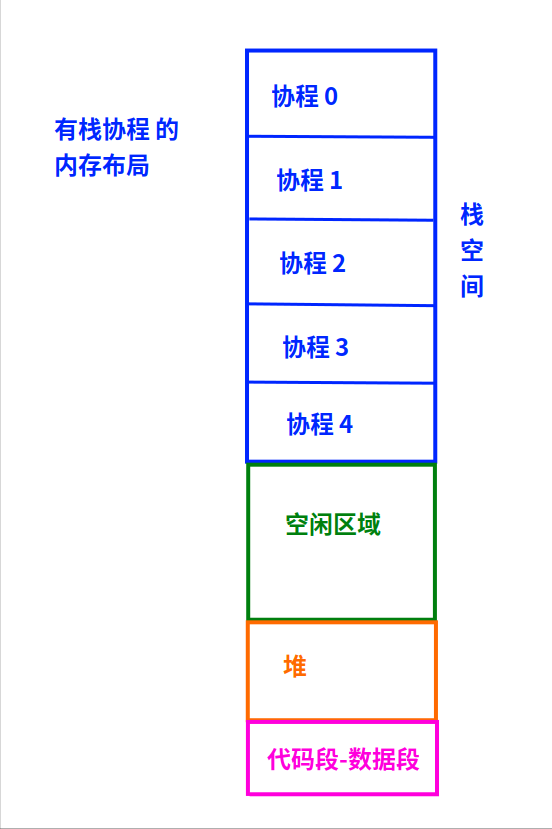
多个协程要想在用户态交替运行,也必须为每个协程配备不同的栈。
多个协程都隶属于同一个进程,而进程栈的位置是被操作系统提前分配好了的。
所以,为每个协程配备栈的时候,每个栈的内存范围必须在进程栈的范围内。
有栈协程的内存布局
如上图:
你说要在“进程”的栈上给协程提前开多大的空间?
每个协程的栈又要预留多大?
预留小了,协程函数的局部变量把协程的描述结构覆盖了的事,也会发生的。
预留大了,同一个进程所能支持的总协程数就会减少。
而且,程序员的用户态代码一般都比内核代码更粗放。
写个用户态代码,还不让我这么开缓冲区 char buf[1024*1024],能行吗?
没有哪个程序员愿意,写个用户代码还像写内核驱动一样战战兢兢的。
所以,有栈协程的劣势非常明显!
1)首先,每个进程支持的协程个数是有限的,而不是无限的。
大多数情况下,虽然用户代码要开的协程个数也不至于突破上限,但毕竟它是个有限集,不是个可数集。
这对用户代码的限制还是比较大的。
有这么个限制,在创建协程的时候就要每次都检查是否成功。
代码就是这样的:
而不是这样的:
否则代码就不完善,因为没有处理异常情况。
2)万一协程函数里有复杂的递归,协程的栈溢出了,那么就可能覆盖多个协程的数据,导致程序挂了。
可以预见,这种挂的位置几乎肯定不是第一现场!
这种BUG查起来,还是非常麻烦的。
不挂在第一现场的内存BUG,都是C语言里很难查的BUG,它很大可能是随机的
然后,就有了无栈协程。
3,无栈协程
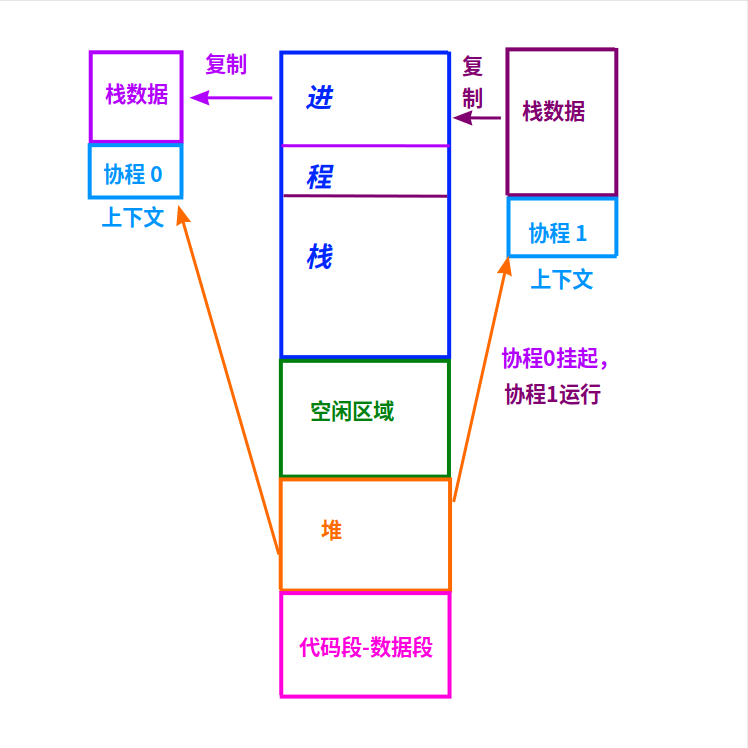
无栈协程的实现也很简单,只要在切换协程之前,把当前协程的栈数据保存到堆上就可以了。
每个协程的上下文都是用malloc()申请的堆内存,在上下文里预留一个空间,在切换协程时把(当前协程的)栈数据保存到这个预留空间里。
当协程再次被调度运行时,把上次的栈数据从(协程的)上下文里复制到进程栈上,协程就可以再次运行了。
无栈协程的内存布局
如上图,协程0挂起,协程1被调度运行:
1)先把进程栈上的数据复制到协程0的上下文里。
这时进程栈上的数据,全是协程0的栈数据。
协程的上下文是malloc()申请的堆内存,如果栈数据太大的话,是可以用realloc()再次分配更大的内存的。
这就打破了协程栈的大小固定的缺陷。
每个协程可以使用的栈大小,只受制于进程的栈的大小。
2)当协程的栈不再受到限制之后,可以创建的协程数量也只受制于进程的堆的大小。
只有整个进程的堆内存被耗尽之后,协程的创建和运行才会没法进行。
我在scf编译器框架里附带的那个协程的实现,就是无栈协程
它在scf/coroutine目录。
2021年的5月份我就想到了这些问题,并且给了解决的代码,在github和gitee的scf代码都有。
2022年以来,我没往github上更新代码,目前gitee上的scf是最新的。
























