arXiv论文“Wayformer: Motion Forecasting via Simple & Efficient Attention Networks“,2022年7月上传,是谷歌Waymo的工作。

自动驾驶的运动预测是一项具有挑战性的任务,因为复杂的驾驶场景会导致静态和动态输入的各种混合形式。如何最好地表示和融合有关道路几何形状、车道连通性、时变交通信号灯状态以及智体的动态集及其交互的历史信息,并将其转换为有效的编码,这是一个尚未解决的问题。为了对这组多样输入特征进行建模,有许多方法设计具有不同特定模态模块集的同样复杂系统。这导致系统难以扩展、规模化或以严格方式在质量和效率之间权衡。
本文的Wayformer,是一系列简单且同类的基于注意运动预测架构。Wayformer提供了一种紧凑的模型描述,由基于注意的场景编码器和解码器组成。在场景编码器中,研究了输入模式的前融合、后融合和分层融合的选择。对于每种融合类型,探索通过分解注意或潜在query注意来权衡效率和质量的策略。前融合结构简单,不仅模态不可知,而且在Waymo开放运动数据集(WOMD)和Argoverse排行榜上都实现了最先进的结果。
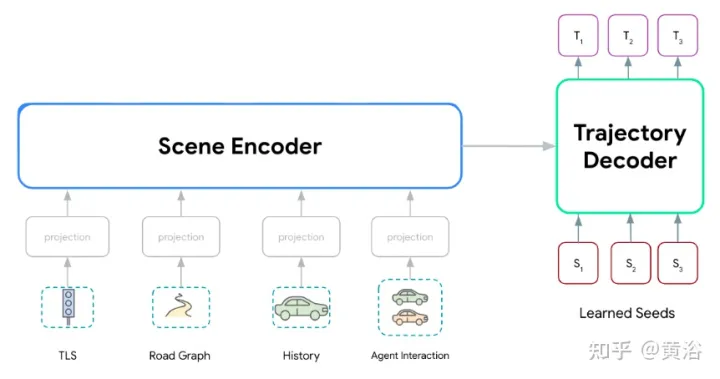
驾驶场景由多模态数据组成,例如道路信息、红绿灯状态、智体历史和交互。对于模态,有一个上下文第4维,表示每个建模智体的“一组上下文目标”(即其他道路用户的表示)。
智体历史包含一系列过去的智体状态以及当前状态。对于每个时间步,考虑定义智体状态的特征,例如x、y、速度、加速度、边框等,还有一个上下文维度。
交互张量表示智体之间的关系。对于每个建模的智体,考虑建模智体周围的固定数量最邻近上下文。这些上下文智体表示影响建模智体行为的智体。
道路图包含智体周围的道路特征。道路图线段表示为多段线,由其端点指定并用类型信息注释的线段集合,可近似道路形状。采用最接近建模智体的道路图线段。请注意,道路特征没有时间维度,可加入时间维度1。
对于每个智体,交通灯信息包含最接近该智体的交通信号状态。每个交通信号点具有描述信号位置和置信度的特征。
Wayformer模型系列,由两个主要组件组成:场景编码器和解码器。场景编码器主要由一个或多个注意编码器组成,用于总结驾驶场景。解码器是一个或多个标准transformer交叉注意模块,其输入学习的初始query,然后与场景编码交叉注意生成轨迹。
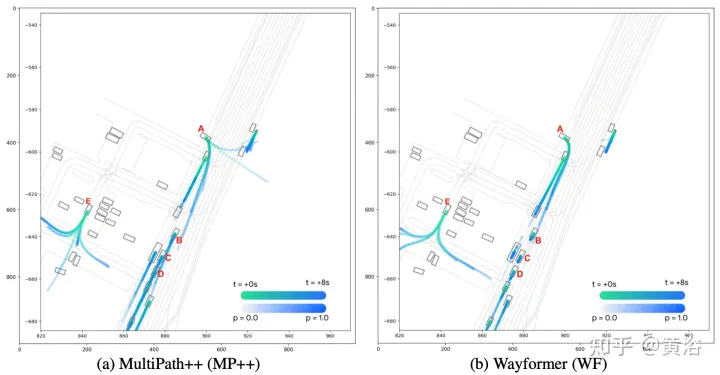
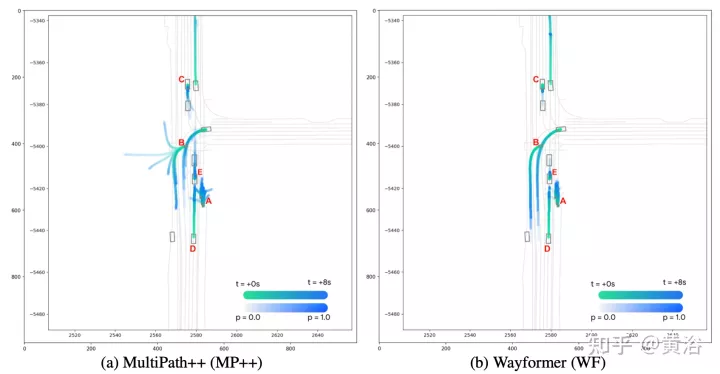
如图显示Wayformer模型处理多模态输入产生场景编码:该场景编码用作解码器的上下文,生成覆盖输出空间多模态的k条可能轨迹。
场景编码器的输入多样性使这种集成变成一项不平凡的任务。模态可能不会以相同的抽象级别或尺度来表示:{像素pixels vs 目标 objects}。因此,某些模态可能需要比其他模态更多的计算。模态之间计算分解是取决于应用的,对于工程师来说非常重要。这里提出三个融合层次来简化这个过程:{后,前,分级},如图所示:
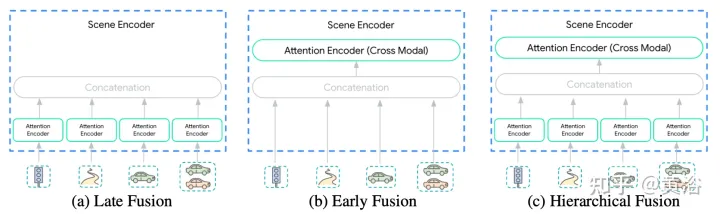
后融合是运动预测模型最常用的方法,其中每个模态都有自己的专用编码器。将这些编码器的宽度设置相等,避免在输出中引入额外的投影层。此外,在所有编码器中共享相同深度,探索空间缩小到可管理的范围。只允许在轨迹解码器的交叉注意层跨模态传输信息。
前融合不是将自注意编码器专用于每个模态,而是减少特定模态的参数到投影层。图中场景编码器由单个自注意编码器(“跨模态编码器”)组成,网络在跨模态分配重要性时具有最大的灵活性,同时具有最小的归纳偏差。
分层融合作为前两个极端之间的折衷,体量以层次化的方式在模态特定的自注意编码器和跨模态编码器之间分解。正如在后融合所做的那样,宽度和深度在注意编码器和跨模态编码器中共享。这有效地将场景编码器的深度在模态特定编码器和跨模态编码器之间分摊。
由于以下两个因素,Transformer网络不能很好地扩展到大型多维序列:
- (a)自注意对输入序列长度是二次方。
- (b) 位置前馈网络是昂贵的子网络。
下面讨论加速方法,(S为空间维度,T为时域维度),其框架如图所示:
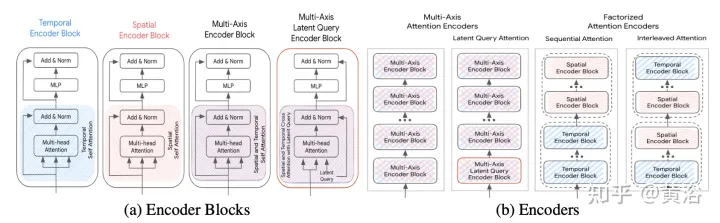
多轴注意(Multi-Axis Attention):这是指默认的transformer设置,同时在空间和时间维度上应用自注意,预计是计算成本最高的。具有多轴注意的前、后和分层融合的计算复杂度为O(Sm2×T2)。
分解注意 (Factorized attention):自注意的计算复杂度是输入序列长度的二次方。这在多维序列中变得更加明显,因为每个额外维度都会通过乘法因子增加输入的大小。例如,一些输入模态有时间和空间维度,因此计算成本规模为O(Sm2×T2)。为了缓解这种情况,考虑沿两个维度分解注意。该方法利用输入序列的多维结构,通过在每个维度单独应用自注意,将自注意子网络的成本从O(S2×T2)降低到O(S2)+O(T2)。
虽然与多轴注意相比,分解注意有可能减少计算量,但将自注意应用到每个维度的顺序时引入复杂性。这里比较两种分解注意范式:
- 顺序注意(sequential attention):一个N层编码器由N/2个时间编码器块和另一个N/2个空间编码器块组成。
- 交错注意(Interleaved attention):N层编码器由时间和空间编码器块交替N/2次组成。
潜查询注意(Latent query attention):解决大输入序列计算成本的另一种方法是在第一个编码器块中使用潜查询,其中输入映射到潜空间。这些潜变量由一系列编码器块做进一步处理,这些编码器块接收然后返回该潜空间。这样可以完全自由地设置潜空间分辨率,减少每个块中自注意分量和位置前馈网络的计算成本。将缩减量(R=Lout/Lin)设置为输入序列长度的百分比。在后融合和分层融合中,所有注意编码器的折减因子R保持不变。
Wayformer预测器输出高斯混合,表示智体可能采取的轨迹。为了生成预测,用Transformer解码器,输入一组k个学习的初始query(Si)并与编码器的场景嵌入做交叉注意,为高斯混合的每个分量生成嵌入。
给定混合中一个特定成分的嵌入,一个线性投影层产生该成分的非规范对数似然,估计整个混合似然。为了生成轨迹,用另一个线性层投影,输出4个时间序列,对应于每个时间步预测高斯的均值和对数标准偏差。
在训练期间,将损失分解为各自分类和回归损失。假设k个预测高斯,训练混合似然,最大化真实轨迹的对数概率。
如果预测器输出具有多个模式的混合高斯,则很难进行推理,基准测度通常会限制所考虑的轨迹数。因此,在评估过程中,应用轨迹聚合,减少所考虑的模态数量,同时仍保持原始输出混合的多样性。
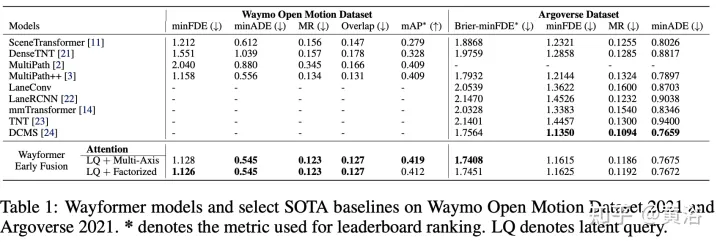
实验结果如下:
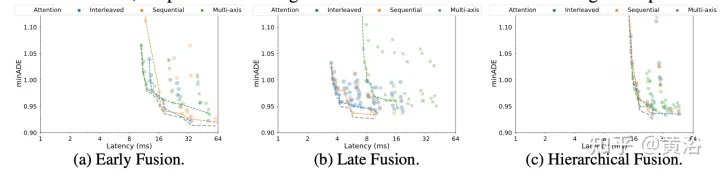
分解注意
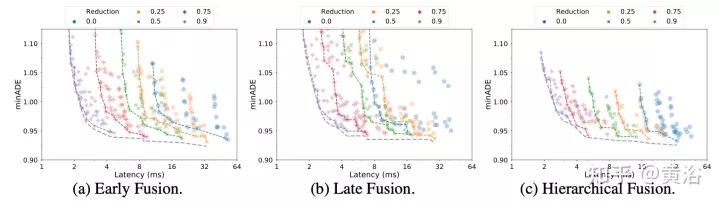
潜查询