arXiv论文“Unifying Voxel-based Representation with Transformer for 3D Object Detection“,22年6月,香港中文大学、香港大学、旷视科技(纪念孙剑博士)和思谋科技等。

本文提出一个统一的多模态3-D目标检测框架,称为UVTR。该方法旨在统一体素空间的多模态表示,实现准确、稳健的单模态或跨模态3-D检测。为此,首先设计模态特定空间来表示体素特征空间的不同输入。在不进行高度信息(height)压缩的情况下保留体素空间,减轻语义歧义并实现空间交互。基于这种统一方式,提出跨模态交互,充分利用不同传感器的固有特性,包括知识迁移和模态融合。通过这种方式,可以很好地利用点云的几何-觉察表达式和图像中上下文丰富的特征,获得更好的性能和鲁棒性。
transformer解码器用于从具备可学习位置的统一空间中高效采样特征,这有助于目标级交互。一般来说,UVTR代表在统一框架中表示不同模态的早期尝试,在单模态和多模态输入方面优于以往的工作,在nuScenes测试集上取得了领先的性能,激光雷达、相机和多模态输出的NDS分别为69.7%、55.1%和71.1%。
代码:https://github.com/dvlab-research/UVTR.
如图所示:
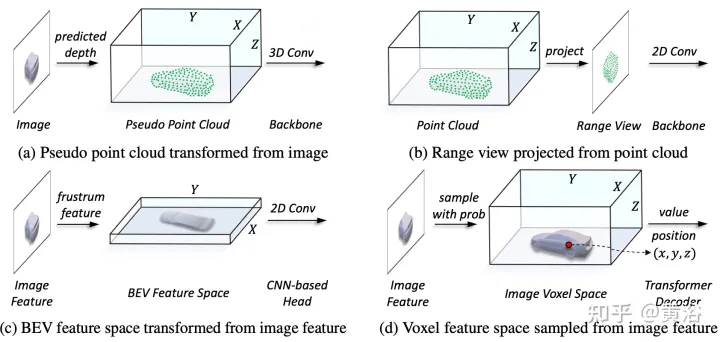
在表征统一过程中,可以大致分为输入级流和特征级流的表示。对于第一种方法,多模态数据在网络开始时对齐。特别是,图(a)中的伪点云是从预测深度辅助的图像转换而来的,而图(b)中的距离视图图像是从点云投影而来的。由于伪点云的深度不准确和距离视图图像中的3-D几何塌陷,数据的空间结构受到破坏,从而导致较差的结果。对于特征级方法,典型的方法是将图像特征转换为截锥(frustum),然后压缩到BEV空间,如图(c)所示。然而,由于其类似射线的轨迹,每个位置的高度信息(height)压缩聚合了各种目标的特征,因此引入了语义多义。同时,他隐式方式很难支持3-D空间中的显式特征交互,并限制进一步的知识迁移。因此,需要一种更统一的表示法弥合模态的差距,并促进多方面的交互。
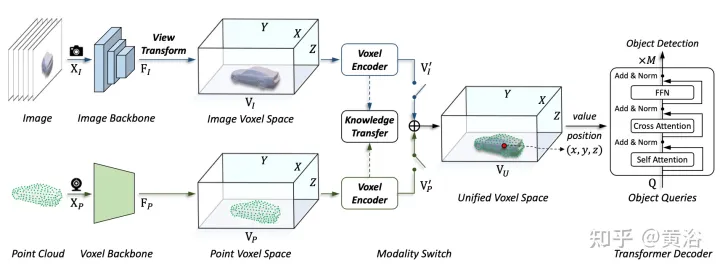
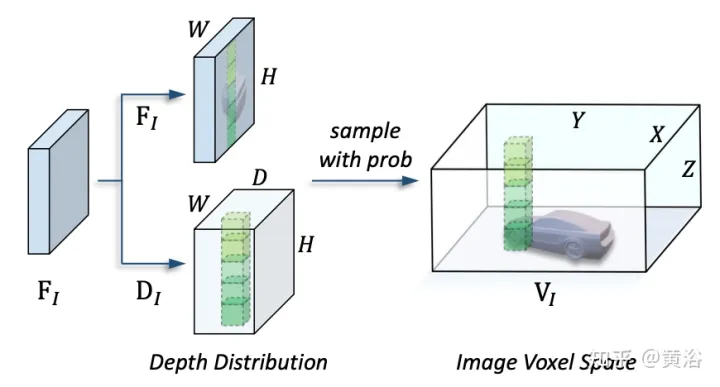
本文提出的框架,将基于体素的表示与transformer统一起来。特别是,在基于体素的显式空间中图像和点云的特征表征和交互。对于图像,根据预测的深度和几何约束,从图像平面采样特征来构建体素空间,如图(d)所示。对于点云,准确的位置自然允许特征与体素相关联。然后,引入体素编码器进行空间交互,建立相邻特征之间的关系。这样,跨模态交互自然地与每个体素空间的特征进行。对于目标级交互,采用可变形transformer作为解码器,对统一体素空间中每个位置(x、y、z)的目标查询特定特征进行采样,如图(d)所示。同时,3-D查询位置的引入有效地缓解了BEV空间中高度信息(height)压缩带来的语义多义。
如图是多模态输入的UVTR架构:给定单帧或多帧图像和点云,首先在单个主干进行处理,并将其转换为特定于模态的空间VI和VP,其中视图转换用于图像。在体素编码器中,特征在空间上相互作用,并且 知识迁移在训练期间易于支持。根据不同的设置,通过模态开关选择单模态或多模态特征。最后,从具备可学习位置的统一空间VU中采样特征,利用transformer解码器进行预测。
如图是视图变换的细节:
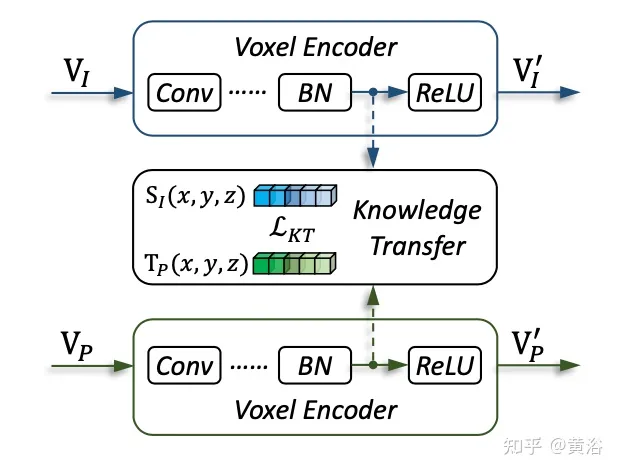
如图是知识迁移的细节:
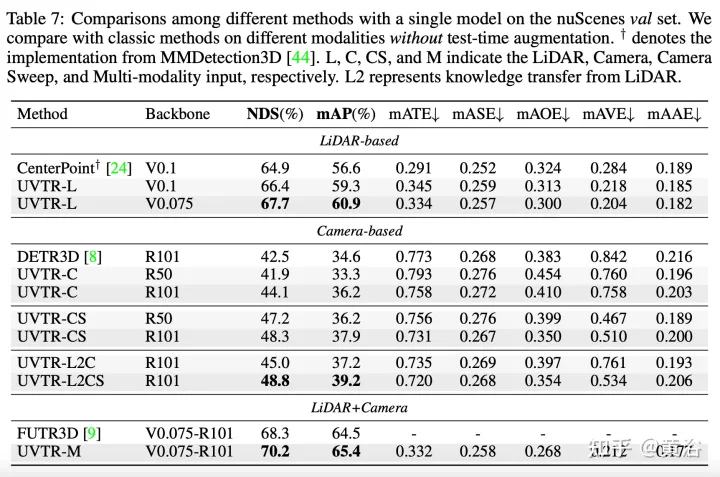
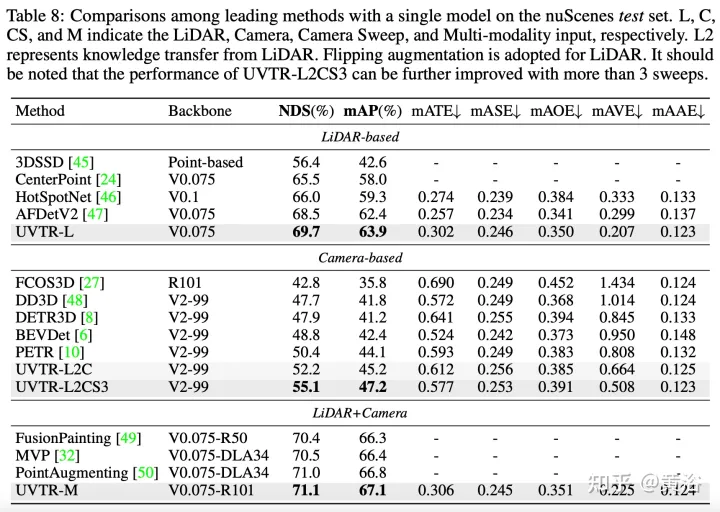
实验结果如下: