1、背景介绍
图数据是NoSQL非关系型数据类型的一种,通过应用图形理论来存储表示实体之间的关系信息,如社交网络中人与人之间的关系、知识图谱中实体间的连接关系等。图数据库的独特设计,很好的弥补了关系数据库不适用于存储图形数据、查询逻辑复杂、查询速度缓慢的缺点。因此,图数据库已广泛应用于社交网络、精准推荐、金融风控、知识图谱等领域。
数据导入功能作为大批量图数据应用的第一个且比较关键的环节,在开展图应用过程中非常重要。经过调研,市场上比较主流的图数据库有Neo4j,NebulaGraph,TigerGraph,JanusGraph,HugeGraph,DGraph等多个国内外厂商。本文主要选取Neo4j,NebulaGraph,JanusGraph三种图数据库作为研究对象,深入对比分析各自在数据导入方面的特点,最后介绍下我们在数据导入技术方面的解决方案。
1.1 NebulaGraph图数据库
NebulaGraph是一款开源的分布式原生图数据库,采用shared-nothing分布式架构设计,擅长处理千亿节点万亿条边的超大规模数据集,并且提供毫秒级查询。它采用计算和存储分离的架构模式,基于RocksDB作为本地存储引擎自研了高性能的KVStore,采用Raft协议保证分布式系统的多副本强一致性和高可用性。
NebulaGraph在数据导入方面提供了多种工具组件操作,如Importer、Console、Studio、Exchange等,其中Console是控制端使用命令行方式导入,适用于操作少量手工测试数据;Studio组件可以通过浏览器导入本地机器上多个csv文件,只限制使用csv类型;Importer工具可以导入单机多个csv文件,一般数据量限制在亿级以内使用;Exchange组件基于Spark分布式集群,可以从csv、Hive、Neo4j、MySQL等多种数据源导入大批量数据集,支持十亿级以上数据;Spark-connector组件使用需要有一定的软件研发能力,撰写少量代码。
每种工具的使用复杂度和导入速度可从下面的坐标图看出:

1.2 JanusGraph图数据库
JanusGraph是一款开源的分布式图数据库,基于Apache TinkerPop3框架开发,采用Gremlin查询语言,具备完善的工具链组件,助力用户轻松构建基于图数据库之上的应用和产品。JanusGraph在存储层设计中,支持分布式存储、数据多副本、横向扩容,内置多种后端存储引擎,并且可通过插件方式集成第三方存储来扩展后端存储引擎,如Cassandra、HBase、BerkeleyDB等数据中间件。
JanusGraph图数据库提供如下几种数据导入方式:
☑ Api数据导入:该方案通过提交java api插入数据请求,可用于数据量较小的情况下使用;
☑ 基于Gremlin Server的批量数据导入:该方案通过gremlin语句提交插入请求,需搭建Gremlin Server服务,要有一定的研发能力;
☑ 基于Bulk Loader组件导入:官方提供批量导入方式,需要Hadoop/Spark集群环境,支持json、csv、xml、kryo等类型,可用于大批量数据导入。
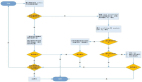
JanusGraph数据导入流程如下图所示:

1.3 Neo4jGraph图数据库
Neo4j是一款由Java开发的半开源图数据库,采用Cypher查询语言,支持快速数据库操作和直观的图数据展示,且操作速度不会随数据量增大而明显降低。Neo4J采用原生图存储设计,在存储节点时使用了"index-free" adjacency模型,每个节点都有指向其邻居节点的指针,可在O(1)的时间内找到邻居节点,提供快速、高效的图遍历。
Neo4j支持以下几种数据导入方式:
☑ 基于Cypher语法中的Load-csv方式:官方提供的ETL工具,仅支持csv文件,导入速度慢,需掌握 Cypher 语言,适用于小批量数据;
☑ Neo4j-import导入工具:官方自带的大数据量导入工具,支持并行可扩展的大规模csv文件导入,适用于初始化数据在千万级以上的数据;
☑ BatchInserter导入工具:一种API数据导入方案,只能在Java中使用,导入速度很快,适用于千万级以上大批量数据操作。
Neo4j图数据库架构设计图如下:

综合比较以上多种图数据库的数据导入能力情况,我们选取NebulaGraph国产图数据库的Exchange组件作为重点研究对象,它是一款Apache Spark应用,基于Apache 2.0协议开放源代码,支持多种不同格式、不同来源的数据,如:csv、json、hdfs、hive、MySQL、kafka、Neo4j等,我们将从代码架构优化、依赖集群调优、存储层结构优化等多个方面对组件的导入能力做优化。
2、数据导入优化技术点
经过调查对比研究,当前图数据导入功能存在导入效率不高、数据源形式限制严格、工具操作复杂等问题,我们将以Exchange组件为基础,从导入流程框架优化、Spark集群调优策略、存储层RocksDb组件优化等不同维度研究提升数据导入效率,从而最大限度的缩短大批量数据导入时间,丰富导入数据源形式,节省使用人员的时间成本。
数据导入组件技术流程设计如下:

2.1 Exchange组件优化
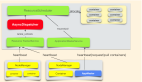
Exchange是基于Spark组件编写的一款应用,主要功能是将集群中多种不同格式的批式数据和流式数据批量导入到图数据库中。
我们通过设计并优化“Reader-Processor-Writer”三层数据导入模型,并引入并发编程模型多线程处理不同点和不同边的数据处理过程,其中Reader层读取不同来源的批数据并生成分布式数据集 DataFrame,Processor层负责读取DataFrame中的批数据,通过提取图数据的结构特点,根据配置文件中设定的映射关系按列名获取对应值,在读取到指定批处理的数据后,Writer层负责将获取到的批数据一次性写入到图数据库中。在整个处理流程中,部分参数设定对处理速率影响较大,如batch(指定单批次写入图数据库的最大点边数量)、partition(指定 Spark分片数量)、rate.limit(指定导入数据时令牌桶令牌数量限制)等,如何根据机器资源环境合理的设置相应的参数非常重要。
在数据导入流程中,以充分利用spark分布式引擎资源为目的,根据服务器资源使用情况、数据插入速率和响应时间等因素,通过设计集群动态参数自适应策略,动态调整batch单次批量插入数据量,以及spark集群partition分区数,合理的分区数能减少任务调度时间及数据倾斜问题,快速并行处理RDD数据集,最大程度利用集群性能,提升数据转换效率。同时,设计RateLimiter限流机制,采用令牌桶算法控制图数据库单次gql数据插入量,保证在处理大批量数据时图数据库能正常平稳运行。另外,利用断点续传能力,把上一阶段未转换完的数据(网络中断等原因),通过保存断点方式继续转换,提升数据转换稳定性。
大批量图数据导入流程架构图设计如下:

2.2 Spark集群优化
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎,Exchange是基于Spark编写的一款应用,它基于Spark的分布式环境将集群中的数据批量迁移到图数据库中,如何充分利用好分布式集群资源,是提高Exchange数据导入效率的一个关键点。
我们在编写好Exchange组件代码程序后,按照Spark约定使用spark-submit命令提交运行,Spark支持local、standalone、mesos、yarn四种运行模式,生产环境推荐使用yarn集群模式运行,我们使用此模式进行任务运行及调试。
通过一系列的调优对比测试,结合官网等资料说明,总体来讲要充分压榨使用集群资源,在资源限制内尽量多的调配内存消耗和增加并发。在应用运行调优过程中,需根据当前Spark集群配置来设置调优各个参数,以减少任务调度时间及数据倾斜问题,最大化提升数据运行效率。
➪ 个别重要参数简要说明如下:num-executors 根据集群服务器台数来参考设置,executor-cores根据每台机器CPU核数来设置,driver-memory和execute-memeory根据总的内存来设置,其中num-executors * execute-memory不能超过集群可用内存等。
2.3 Storage存储层优化
图存储的主要数据是点和边,Nebula图数据库将点和边的信息存储为key,同时将点和边的属性信息存储在value中,以便更高效地使用属性过滤。Nebula在Storage层使用RocksDB作为存储组件,RocksDB是一个可插拔式的持久化存储系统,基于LSM架构,支持高效的读写吞吐,具备和分布式存储系统类似的术语操作定义,如 WAL,Compact,Transaction等。
作为分布式存储引擎的一个存储媒介,在方案设计时为了保证数据一致性,RocksDB整个写入链路会先写WAL,再写memtale,其中WAL保证了数据的高可用性,在宕机时可根据WAL恢复数据。
在存储层的参数配置上,RocksDB中部分比较重要的参数介绍如下:rocksdb_block_cache,设置默认块缓存大小,用来缓存解压后的数据,建议设置为节点有效负载内存的1/3左右;max_background_jobs,设置后台工作子线程数,加快压缩效率,建议设置为节点机器的有效可用核数;max_subcompactions,设置压缩线程数。
上述参数可结合数据导入配置中batch等参数一起调试使用,进而选择与当前环境资源比较匹配的一个理想参数配置。
存储层数据写入流程图如下:

3、总结
上面是我们在大批量图数据导入功能总结的一些优化经验,经过多种策略调优设计,测试报告显示在同等资源下亿级数据量优化前后导入性能提升了12.66%。软件优化是一项无止境的系统工程,除了上面我们提到的这些调优策略之外,还有很多其它的处理手段我们没有发现,希望大家能继续探索研究,多多交流。