导读:在真实世界中,很多数据往往以图的形式出现,例如社交网络、电商购物、蛋白质相互作用关系等,过去几年基于神经网络的图数据分析与挖掘方式因其出色的性能受到了广泛的关注,不仅一跃成为学术界的研究热点同时也在多种应用中大放异彩。这篇文章主要结合相关文献、领域专家的分享以及笔者浅薄经验,所做的粗浅总结和归纳。虽然是知识的搬运但也参杂了个人的主观判断,偏颇以及疏漏难免,还请各位谨慎参考。修修补补停笔恰逢平安夜,也借此契机祝大家新的一年所愿皆所得,平安多喜乐。
1、图神经网络发展综述

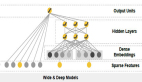
近些年来使用建模分析图结构的研究越来越受到关注,其中基于深度学习的图建模方法的图神经网络(Graph Neural Network, GNN),因其出色的性能成为学术界的研究热点之一。例如下图所示,图神经网络在机器学习相关顶会上的论文数量持续攀升,以图作为标题或者关键词在近两年表征学习顶会ICLR的出现频率是最热门的词语之一。另外今年多个会议的最佳论文奖均有图神经网络的身影,例如数据挖掘顶会KDD今年的最佳博士论文的冠亚军均是颁发给了图机器学习相关的两位青年学者,最佳研究论文以及应用论文也分别是关于超图上的因果学习以及联邦图学习。另一方面,图神经网络在电商搜索、推荐、在线广告、金融风控、交通预估等领域也有诸多的落地应用,各大公司也纷纷着力构建图学习相关平台或者能力。


虽然图神经网络在近五年才开始成为研究热点,但是相关定义在2005就由意大利学者Marco Gori和Franco Scarselli等人提出。在Scarselli论文中典型的图如下图所示。早期阶段的GNN主要是以RNN为主体框架,输入节点邻居信息更新节点状态,将局部转移函数定义为循环递归函数的形式,每个节点以周围邻居节点和相连的边作为来源信息来更新自身的表达。

LeCun的学生Bruna等人2014年提出将CNN应用到图上,通过对卷积算子巧妙的转换,提出了基于频域和基于空域的图卷积网络两种信息聚合方式。基于谱的方法从图信号处理的角度引入滤波器来定义图卷积,其中图卷积操作被解释为从图信号中去除噪声。基于空间的方法则更加契合CNN的范式将图卷积表示为从邻域聚合特征信息。此后几年,虽然也有零星的一些新的模型的提出,但是依旧是较为小众的研究方向。直到2017年图模型三剑客GCN,GAT,GraphSage为代表的一系列研究工作的提出,打通了图数据与卷积神经网络之间的计算壁垒,使得图神经网络逐步成为研究的热点,也奠定了当前基于消息传递机制(message-passing)的图神经网络模型的基本范式(MPNN)。

典型的MPNN架构由几个传播层组成,基于邻居特征的聚合函数对每个节点进行更新。根据聚合函数的不同,可以将MPNN分为:信息聚合(邻居特征的线性组合,权值仅依赖于图的结构,例如GCN)、注意力(线性组合,权值依赖于图结构和特征,例如GAT)和消息传递(广义的非线性函数,例如GraphSAGE),下图从左到右所示。

从推理方式来看,还可以分为直推式(transductive,例如GCN)和归纳式(inductive,例如GraphSage)。直推式的方法会对每个节点学习到唯一确定的表征, 但是这种模式的局限性非常明显,工业界的大多数业务场景中,图中的结构和节点都不可能是固定的,是会变化的,比如,用户集合会不断出现新用户,用户的关注关系集合也是不断增长的,内容平台上的文章更是每天都会大量新增。在这样的场景中,直推式学习需要不停地重新训练,为新的节点学习表征。归纳式的方法则是去学习节点邻居特征“聚合函数”,从而可以适用到更加灵活的场景,例如新节点的表示或者图上的结构发生变化等场景,因此会适用于实际场景中各种图动态变换的场景。
在图神经网络发展的过程中,为了解决图网络计算精度与可拓展问题,一代又一代的新模型被不断提出。虽然图神经网络在图数据表征能力毋庸置疑,但是新的模型设计主要基于经验直觉、启发式方法和实验试错法。Jure Leskovec组2019年的相关工作GIN(Graph Isomorphism Networks)中将GNN与图同构检测的经典启发式算法Weisfeiler Lehman(WL)建立了联系,并且从理论角度证明了GNN的表达能力上限值为1-WL(Jure目前是斯坦福大学计算机学院的副教授,他领导的SNAP实验室目前是图网络领域最为知名的实验室之一,主讲的CS224W《图机器学习》是强烈推荐的学习资料)。然而WL算法对于很多的数据场景表达能力十分有限,例如对于下图中的两个例子。对于(a)中的Circular Skip Link (CSL) Graphs, 1-WL会给两个图中的每个节点标记相同的颜色,换句话说这明显两个结构完全不同的图,利用1-WL测试我们会得到一样的标签。第二例子是如(b)中所示的Decalin molecule,1-WL会给a和b染相同的颜色,给c和d染相同的颜色,使得在链路预测的任务中,(a,d)和(b,d)是无法进行区分的。

WL-test在存在三角或者环状结构的很多数据中都表现得差强人意,但是在生物化学等领域,环状结构十分普遍也是非常重要,同时也决定了分子的相应性质,使得图神经网络在相关场景的适用性被极大的限制。Micheal Bostein等人提出当前图深度学习方法「以节点和边为中心」的思维方式具有极大的局限性,基于此,他们提出了从几何深度学习的角度重新思考图学习的发展以及可能的新范式(Micheal目前是是牛津大学的DeepMind人工智能教授同时也是Twitter图学习研究组的首席科学家也是几何深度学习的推动者之一)。许多学者也纷纷从微分几何、代数拓扑和微分方程等领域出发开启了一系列新工具的研究,提出了等变图神经网络、拓扑图神经网络、子图神经网络等一系列工作并且在诸多问题上取得瞩目的效果。结合图神经网络的发展脉络我们可以做如下图的简单小结。

2、复杂图模型
上一节我们概述了图神经网络的发展历程,提及的相应的图神经网络基本都是设定在无向以及同质图的场景,然而真实世界中的图往往是复杂的,研究人员提出了针对有向图、异构图、动态图、超图、有符号图等场景的图神经网络模型,我们接下来分别对这几种图数据形态以及相关模型进行简单的介绍:

1. 异构图:异构图(Heterogeneous graph)是指节点和边具有多种类别,存在多种模态时的场景。例如,在电商场景,结点可以是商品,店铺,用户等,边类型可以是点击,收藏,成交等。具体而言,在异构图中,每个节点都带有类型信息,每条边也带有类型信息,common GNN模型无法建模相应的异构信息。一方面,不同类型的结点的Embedding维度就没法对齐;另一方面,不同类型的结点的Embedding位于不同的语义空间。最广为使用的异构图学习方法是基于元路径的方法。元路径指定了路径中每个位置的节点类型。在训练过程中,元路径被实例化为节点序列,我们通过链接一个元路径实例两端的节点来捕获两个可能并不直接相连的节点的相似度。这样一来,一个异构图可以被化简为若干个同构图,我们可以在这些同构图上应用图学习算法。此外,还有一些工作提出了基于边的方法处理异构图,它们为不同的邻居节点和边使用不同的采样函数、聚合函数。代表性的工作有HetGNN、HGT等。我们有时还需要处理关系图,这些图中的边可能包含类别以外的信息,或者边的类别数十分巨大,难以使用基于元路径或元关系的方法。对于异构图感兴趣的小伙伴可以去关注北邮石川老师以及王啸老师的系列工作。

2. 动态图:动态图(Dynamic Graph)是指节点以及拓扑结构随时间演化的图数据,在实际场景中也是广泛存在的。比如,学术引用网络会随时间不断扩张,用户与商品的交互图会随用户兴趣而变化,交通网络,交通流量随时间不断变化。动态图上的GNN模型旨在生成给定时间下的节点表示。根据时间粒度的粗细,动态图可分为离散时间动态图(也被称为snapshot based)和连续时间动态图(event-based); 在离散时间动态图中,时间被划分为多个时间片(例如以天/小时划分),每个时间片对应一个静态的图。离散时间动态图的GNN模型通常在每个时间片上单独应用GNN模型,然后利用RNN来聚合节点在不同时间的表征,代表性的工作有DCRNN、STGCN、DGNN、EvolveGCN等。在连续时间动态图中,每条边附有时间戳,表示交互事件发生的时刻。相比于静态图,连续时间动态图中的消息函数还依赖于给定样本的时间戳以及边的时间戳。此外,邻居节点必须与时间有关,例如邻居节点中不能出现时刻之后才出现的节点。从模型角度出发,点过程也常常应用于建模连续的动态图,通过优化邻域生成序列的条件强度函数来生成序列的达到率,这种方式也可以进一步预测事件发生的具体时刻(例如网络中某条链路的消亡时间)。连续动态图上的建模的代表性工作有JODIE、HTNE、MMDNE、Dyrep。

来源:Dyrep
3. 超图:超图(Hypergraph)是一种广义上的图,它的一条边可以连接任意数量的顶点。关于超图的研究初期重要是在计算机视觉场景有相关的应用,近期也受到了图神经网络领域的关注,主要的应用领域和场景是推荐系统,例如图中的一对节点可以通过不同类型的多条边相关联。通过利用不同类型的边,我们可以组织起若干层图,每层代表一种类型的关系。代表性的工作有HGNN、AllSet等。

来源:AllSet
4. 有向图:有向图(Directed graph)指的是节点的连接关系是有方向的,有向边往往比无向边包含更多的信息。例如,在知识图谱中,若头实体是尾实体的父类,则边的方向会提供这种偏序关系的信息。对于有向图的场景,除了简单地在卷积操作中使用不对称的邻接矩阵,还可以分别对边的两个方向建模,获得更好的表征,代表性的工作有 DGP等。

来源:DGP
5. 符号图:符号图(Signed graph)指的图中节点的关系包含正向以及反向等关系,例如社交网络中,互动关系包含积极的关系,例如友谊、协议和支持,以及负面关系,如敌人、分歧和抵制等等,相较于普通图,符号图蕴含更加丰富的节点互动关系。对于符号图的建模首要解决的问题是如何对负向边进行建模,同时如何对两类边的信息进行聚合,SGCN根据平衡理论的假设(朋友的朋友是朋友,敌人的朋友是敌人)定义了相应的平衡路径从而进行相应的建模。除此以外,代表性的工作还有带符号网络的极化嵌入模型POLE、二分符号图神经网络模型SBGNN、基于k组理论的符号图神经网络GS-GNN。

来源:SGCN
6. 异配图:和以上的其他几种类型图的定义稍有不同,异配性是描述图数据特性的一种指标,所谓的异配图(Heterophily graph)指的是图上节点邻居相似度比较低的数据类型。与异配性对应的是同配性也就是说链接的节点通常属于同一类或具有相似的特征(“物以类聚”)。例如,一个人的朋友和自己可能有相似的政治信仰或年龄,一篇论文倾向于引用同一研究领域的论文。然而现实世界的网络并不是完全都符合同配性高的假设,例如蛋白质分子中,不同类型的氨基酸链接一起。图神经网络通过链接关系进行特征的聚合以及传播的机制即是基于数据的同配性的假设使得GNN在异配性比较高的数据上常出现效果不佳的现象。目前,已有很多工作尝试将图神经网络泛化到异配图场景,例如利用结构信息为节点选择邻居的模型Geom-GCN、通过改进图神经网络的消息传递机制来提升其表达能力的H2GNN、通过构造基于中心节点相关度重排序进行信息聚合的指针网络GPNN(如下图所示其中不同颜色代表不同的节点类型)、通过同时结合高频信号以及低频信号处理的FAGCN等。

来源:GPNN
3、图神经网络应用
由于图神经网络能够较好地学习图结构数据的特征,因此在许多图相关的领域有着广泛的应用和探索。这节我们分别从下游任务以及应用的角度进行相应的分类和归纳。
1. 下游任务


节点分类:根据节点的属性(可以是类别型、也可以是数值型)、边的信息、边的属性(如果有的话)、已知的节点预测标签,对未知标签的节点做类别预测。例如OGB的的ogbn-products数据集就是一个无向的商品购买网络,节点代表的是在电商销售的产品,两个产品之间的边表示这些产品被一起购买过,节点的属性通过从产品描述中提取词袋特征,然后进行主成分分析降维生成。相应的任务是预测产品缺失的类别信息。
链接预测:网络中的链路预测(Link Prediction)是指如何通过已知的网络节点以及网络结构等信息预测网络中尚未产生连边的两个节点之间产生链接的可能性。这种预测既包含了对未知链接的预测也包含了对未来链接(future links)的预测。链路预测在推荐系统、生化试验等场景都有广泛的应用,例如在商品推荐中在用户和商品的二部图中,如果用户购买商品,则用户和商品间存在链接,相似的用户可能同样会对该商品有需求,因此,预测用户和商品之间是否可能发生“购买”、“点击”等的链接,从而针对性地为用户推荐商品,可以提高商品的购买率。除此之外,自然语言处理中的知识图谱补全以及智慧交通中的路况预测都可以建模成链接预测的问题。
图分类:图分类其实和节点分类相似,本质就是预测图的标签。根据图的特征(比如图密度、图拓扑信息等)、已知图的标签,对未知标签的图做类别预测,可见于生物信息学、化学信息学,比如训练图神经网络来预测蛋白质结构的性质。
图生成:图生成目标是在给定一组观察到的图的情况下生成新的图,例如在生物信息中基于生成新的分子结构或者是自然语言处理中基于给定的句子来生成语义图或者是知识图谱。
2. 应用领域
我们再对不同的应用场景进行相应的介绍。

推荐系统:移动互联网的发展极大的推动了信息检索的快速发展。推荐系统作为其中最为重要方向,获得了广泛的关注。推荐系统的主要的目的是从历史交互(historical interactions)和边信息(side information)中学习有效的用户(user)和物品(item)表示,从而给用户推荐其更可能倾向的物品(商品、音乐、视频、电影等)。因此很自然的考虑以物品和用户为节点构造二部图,从而可以将图神经网络应用到推荐系统来提升推荐的效果。Pinterest基于GraphSAGE提出了第一个基于GCN的工业级别推荐系统PinSage,支撑了30亿节点,180 亿条边的大规模图片推荐的场景,实际上线后Pinterest的Shop and Look产品浏览量提高了25%, 此外Alibaba,Amazon以及其他很多电子商务平台使用GNN来去构建相应的推荐算法。

除了user-item交互组成的二部图(bipartite graph),推荐系统中社交关系、知识图谱序列中的item转移图都是图数据形式存在,另外一方面,异构数据在推荐系统之中也是广泛存在于电商场景,结点可以是Query,Item,Shop,User等,边类型可以是点击,收藏,成交等。通过利用项目与项目、用户与用户、用户与项目之间的关系以及内容信息,基于多源异构以及多模态图模型,实现更高质量的推荐效果也在被不断的探索。除此之外,基于实际业务中用户行为随时间变化的序列化推荐以及新用户以及商品加入导致节点引发的增量学习的诉求也给GNN模型发展带来了新的挑战和机遇。

自然语言处理:在自然语言处理中的诸多问题和场景都是描述了关联关系,因此可以很自然的建模成为图数据结构。第一个直接的应用场景是知识图谱(knowledge graph,KG)的补全以及推理,例如在Mila的研究人员提出的基于NBFNet将单跳推理问题建模成路径表征学习问题,从而实现知识图谱的归纳推理。图神经网络利用深度神经网络对图数据中的拓扑结构信息和属性特征信息进行整合,进而提供更精细的节点或子结构的特征表示,并能很方便地以解耦或端到端的方式与下游任务结合,满足不同应用场景下的知识图谱对学习实体、关系的属性特征和结构特征的要求。

除此之外,图神经网络在自然语言处理中诸多问题例如文本分类、语义分析、机器翻译、知识图谱补全,命名实体识别以及机器分类等场景上都有相应的应用,更多的内容推荐大家参考吴凌飞博士Graph4NLP的相关教程以及综述。

来源:(https://github.com/graph4ai/graph4nlp)
计算机视觉:计算机视觉是机器学习以及深度学习领域最大的应用场景之一,相较于推荐系统以及自然语言处理领域而言,图神经网络在计算机视觉不算主流。原因在于GNN的优势是关系建模和学习,计算机视觉中的数据格式大多数是规则的图像数据。在CV场景中使用GNN,关键在于graph如何构建:顶点及顶点特征是什么?顶点的连接关系怎么定义?初期的工作主要用于一些直观易于进行图结构抽象的场景。例如用于动态骨骼的动作识别方法ST-GCN中,人体自然骨架自然的可以视为图结构构建空间图。在场景图生成中,对象之间的语义关系有助于理解视觉场景背后的语义含义。给定一幅图像,场景图生成模型检测和识别对象,并预测对象对之间的语义关系。在点云分类和分割中,将点云转换为k-最近邻图或叠加图从而利用图网络进行相关任务的学习。近期,图形神经网络在计算机视觉中应用的方向也在不断增加。一些研究人员在通用计算机视觉任务例如物体检测进行相关探索以及尝试。例如华为提出一种基于图表示的新型通用视觉架构ViG中研究人员将输入图像分成许多小块,构建相应的节点图,实验结果表明相比于矩阵或网格,图结构能更灵活表示物体部件之间的关系,进而达到更理想的效果。

来源:Vision GNN@NeurIPS 2022
智能交通:交通的智能管理是现代城市的一个热点问题。准确预测交通网络中的交通速度、交通量或道路密度,在路线规划和流量控制中至关重要。由于交通流具有高度的非线性和复杂性特点,传统机器学习方法难以同时学习空间和时间的依赖关系。网络出行平台以及物流服务的蓬勃发展为智能交通提供了丰富的数据场景,如何利用神经网络来自动学习交通数据中的时空关联性从而实现更好的交通流量分析以及管理成为研究的热点。由于城市交通(如下图所示)天然就是以不规则的网格形式存在,将图神经网络用于智能交通管理是非常自然的探索。

来源:Traffic4Cast@NeurIPS 2022
例如经典的时空网络STGCN则是在每个时刻对每张交通流量图使用GCN捕捉空间特征,对于每个节点在时间维度通过卷积捕捉时序特征,这两种操作交叉混合并行,实现时空两个维度的特征的端到端学习。也有相应的工作通过利用多源信息构造不同视角的节点关联图进行信息的聚合实现更加准确的预测效果。除了流量预测以外,图神经网络也被用在信号灯管理,交通事件检测,车辆轨迹预测,道路拥塞预测等多个方面。近几年在KDD以及NeurIPS等顶会的相关比赛也均设有相应的交通预测的赛题,winner solution基本都有图神经的身影。由于同时存在时空动态性,不夸张的说智能交通领域的相关应用诉求是时空图神经网络发展最为重要的推手。

金融风控:随着市场经济的发展以及行业数字化的进程,大量传统业务迁移到线上的同时,各类线上新产品和服务也与日俱增,海量的数据以及复杂的关联关系,给金融交易以及相关审计带来极大的挑战。银行信贷管理以及上市公司的风险管理等对于金融市场的秩序维护有着重要的作用。新兴的支付宝、paypal等全球支付管理系统的推广,为其保驾护航的支付风控体系在保护用户资金安全,防止盗卡盗号,减少平台损失方面起着至关重要的作用。而传统的算法不足以解决具有关联信息的图网络数据的分析,得益于图神经网络对图数据的处理能力,一系列金融风控各个场景的实践应运而生。例如交易流程中贷前贷中贷后的的风险评估,虚拟账号/水军/欺诈检测等。虽然图深度学习技术应用在风控领域已经证明是有效且必要的,但发展时间较短,整体进程还处在发展初期阶段,由于行业数据的私密性,主要的技术创新还是以相应的公司为主导其中蚂蚁金服以及亚马逊较为突出。例如蚂蚁金服提出的GeniePath算法骗保识别问题,定义为一个账户的二分类问题,其提出的首个利用图卷积进行恶意账户识别的GEM算法主要使用于账户登录/注册场景。数据的私密性以及场景的多样性,这也造成业内没有统一的标准进行模型的对比验证。最近信也科技联合浙江大学发布的联合发布大规模动态图数据集DGraph提供了一个真实场景的大规模数据用于欺诈等异常检测等场景的验证,其中节点表示信也科技服务的金融借贷用户,有向边表示紧急联系人关系,每个节点包含脱敏后的属性特征,以及表示是否为金融诈骗用户的标签。虽然存在数据壁垒等问题,金融风控场景中普遍存在的数据不均,标签难获取,以及对模型可解释性的诉求也给图神经网络的发展带来了新的思考和机遇。

药物发现:药物开发是一个周期长、费用高且风险高的大工程,从最初的药物设计、分子筛选,到后期的安全测试、临床试验,新药研发周期大约需要花费10-15年,平均每一款药的研发成本将近30亿美金,在此过程中,1/3的时间和费用都花费在药物发现的阶段。特别是面对COVID-19等流行病的爆发,如何有效地利用深度学习模型,快速发现可能的、多样化的候选分子,加快新药的开发进程,引发众多研究人员的思考和参与。

药物研发中涉及的分子化合物、蛋白质等等物质天然是以图结构存在。以分子为例,图的边可以是分子中原子之间的键或蛋白质中氨基酸残基之间的相互作用。而在更大的范围内,图可以代表更复杂的结构(例如蛋白质,mRNA或代谢物)之间的相互作用。在细胞网络中,结点可以表示细胞、肿瘤以及淋巴,边表示他们之间的空间邻近关系。因此将图神经网络于分子特性预测,高通量筛选,新型药物设计,蛋白质工程和药物再利用等方面,具有广阔的应用前景。例如麻省理工学院CSIAL的研究人员及其合作者发表在Cell(2020)的工作利用图神经网络以预测分子是否具有抗生素特性上。 同组人员今年提出基于图生成方法搭建基于抗原的条件生成模型来设计和特定抗原高度匹配的抗体等一系列工作。Mila实验室也是将图学习应用于药物发现的先行者,并且最近也基于相应的探索开源了基于PyTorch的药物发现机器学习平台TorchDrug。除此之外,各大科技公司近年也在AI制药方面进行布局和探索,并有相应的突出成果,腾讯 AI Lab「云深」平台发布业内首个药物AI大型分布外研究框架 DrugOOD,以推动药化场景中的分布偏移(distribution shift) 问题研究,助力药物研发行业发展。百度创始人李彦宏发起创立的百图生科,致力于将先进AI技术与前沿生物技术相结合,构建独特的靶点挖掘及药物设计。

芯片设计:芯片是数字时代的灵魂所在,也是信息产业的三要素之一。图结构数据贯穿在芯片设计的多个阶段,例如在逻辑综合(Logic Synthesis)阶段,数字电路通过与非图进行表示,在物理设计(Physical Design)阶段,根据逻辑综合生成的电路网表生成相关约束,工程师按照一定的密度和拥塞限制的要求,完成芯片的布局布线。

随着电路规模和复杂性的不断增长,电子设计自动化(EDA)工具的设计效率和精度已成为一个至关重要的问题,这吸引了研究人员采用深度学习技术来辅助电路设计过程。如果能够在芯片设计的早期阶段预测电路质量和实用性,那么芯片迭代的效率可以得到提升,同时设计成本也将降低。例如,在物理设计阶段预测电路的拥塞可以帮助检测其缺陷并避免产生缺陷芯片,如果可以在逻辑合成阶段进行此类预测,则可以进一步节省芯片的设计生产周期。谷歌与斯坦福大学团队将GNN成功用于硬件设计,结合强化学习,如对Google TPU芯片块的功耗、面积和性能的优化。针对芯片网表表征中的多种异构信息,华为与北京大学提出的Circuit GNN,通过集成拓扑和几何信息得以构图,实现针对cell和net属性预测的多种EDA任务性能的提升。


除了以几个领域外,图神经网络也被探索应用于其他诸多问题,如程序验证、社会影响预测、脑网络、事件检测、模型仿真、组合优化问题求解。可以看出来,在科学和生活的多个领域,数据都是可以表示成图结构。通过对结构信息以及图属性信息的有效捕捉,图神经网络在各种图任务上达到了较高的精度,成为解决图相关问题的有效手段,我们相信在未来很多的领域以及场景都可以看到图神经网络的身影。
4、图神经网络的可拓展性
在前面的内容我们介绍了图模型的一些基本范式以及相应的应用场景,我们可以看到图神经网络作为一种新的深度学习架构,在社交网络、推荐系统、生物医学发现等不同领域都大放异彩。然而实际的应用中,图模型的扩展性以及可用性还是有诸多的理论和工程挑战。首先是内存限制。GCN在设计之初其卷积操作是在全图上进行,即每层的卷积操作都会遍历全图,在实际应用中,需要的内存和时间的开销都是不可接受的。另外,在传统的机器学习框架中,模型的损失函数可以分解为单个样本的损失之和,因此可以使用mini batch和随机优化来处理比GPU内存大得多的训练集。然而,GNN的训练中,与样本独立的机器学习标准数据集不同,网络数据的关系结构会在样本之间产生统计依赖性。直接通过随机采样进行Mini-Batch训练往往会导致模型效果大打折扣。然而,要确保子图保留完整图的语义以及为训练GNN提供可靠的梯度并不是一件简单的事情。其次是硬件限制。相对于图像数据以及文本数据图本质上是一种稀疏结构,因此需要利用其稀疏性来进行高效和可扩展的计算,但是目前的相应深度学习处理器以及相关硬件的设计都旨在处理矩阵上的密集运算。这节我们主要对图模型的可拓展性进行一些总结。参照剑桥大学在读博士生 Chaitanya K. Joshi的总结相关工作可以归纳为数据预处理、高效的模型架构、新的学习范式以及硬件加速四个方面(如下图所示)。

其中数据预处理一般是通过对原始数据进行采样或者简化的方式实现大规模图数据的计算(下面我们会再进一步展开)。新的架构的则是从一些特定任务或者数据的角度出发,提出了一些新的更为高效简洁的架构。例如LightGCN省去了相邻节点间的内积部分从而实现运行速度的加速。一些工作也发现在节点特征上运行 MLP 后利用标签传播方法也可以取得不错的效果。除此之外,我们也可以通过一些轻量化的学习范式例如知识蒸馏或者量化感知训练,来提高 GNN 的性能和降低延迟。指的提的一点是,上述提及的几种图神经网络加速训练的方式都是相互解耦的,这意味在实际场景中都是可以同时采取多种方法配合使用。

来源:G-CRD@TNNLS
相较于模型的优化以及新的学习范式等方式,数据预处理是更为通用以及适用性更强的方法,也是目前相对而言,我们这边稍微展开进行分析和介绍。整体而言,数据预处理的方式都是通过一些采样或者图简化的方式减小原图的规模从而可以满足内存的限制。
1、基于采样的数据处理
基于采样的方法可以分为三小类,Node-Wise Sampling,Layer-Wise Sampling和Graph-Wise Sampling。

Node-Wise Sampling:由GraphSage首次提出,是一种比较通用有效以及应用得最多的方式。一层 GraphSAGE 从 1-hop 邻居聚合信息,叠加 k 层 GraphSAGE 就可以使得感受野增大为 k- hop 邻居诱导的子图,同时对邻居做均匀采样,可以控制聚合操作的速度,更少的邻居意味着更少的计算。不过需要注意的是随着层数的在增加,采样到的邻居数量也会指数增加最后仍然会等价于k-hop跳邻居诱导的子图上做消息聚合,时间复杂度并没有实质性的改进。

Lay-Wise sampling:由Fast GCN首次提出,与 GraphSAGE 不同,它直接限制了节点的邻居采样范围,通过重要性采样(importance sampling)的方式,从所有节点中采样在一个小批次内 GraphSAGE 的每个样本节点的邻居集合是独立的,而 Fast GCN 的所有样本节点共享同一个邻居集合,所以能够把计算复杂度直接控制到线性级别,但是需要注意的是当我们待处理的图是大而稀疏的时候,该方法采样得到的相邻层的样本可能根本没有关联,导致无法学习。

Graph-wise Sampling:与邻居采样的方法不同,图采样技巧是从原图上采样子图,例如Cluster GCN 使用聚类的思想,把图划分为小块进行训练以实现图采样。图聚类算法(例如METIS)让相似的节点分在一起,使得类内的节点分布和原图的节点分布有偏差。为了解决图采样带来的问题,Cluster GCN 在训练时同时抽取多个类别作为一个批次参与训练,对节点分布进行平衡。不过基于基于结构的采样方法信息损失较大, 大多数据上效果比full-batch的GNN差距大,每个epoch都需要进行采样,时间开销并不小。

2、基于图简化
除了采样,通过一些图简化的方式(Graph reduction)缩小原图的规模的同时保留关键的属性以便后续的处理和分析也是可行的方向。图简化主要包含图稀疏化(Graph Sparsification):减少图中边的数量和图粗化(Graph coarsening):减少图中顶点的数量。

其中图粗化(graph coarsening)通过”捏点”的方式把一些subgraph聚合成一个super-node从而实现原图规模的化简对于是一个合适的框架。将图粗化用于GNN加速训练的算法首次在KDD 2021年的工作提出,流程如下图所示:

首先使用图粗化算法(例如谱聚类粗化)把原图进行粗化,并在粗化后的图G′ 上进行模型训练,从而实现图神经网络训练所需的参数的降低,以及减少训练消耗时间和运行内存开销。该方法通用简单并且具有线性的训练时间和空间。作者的理论分析也表明,在谱聚类(spectral clustering)粗化后的图上做的 APPNP 训练,等价于在原图上做受限的 APPNP 训练。但是,和图采样方法一样,基于图粗化的方式也是需要对数据进行预处理,时间开销和实验效果和粗化算法的选择有关。
同样的上述介绍的几种基于采样或者简化的图模型扩展方法同样也是方法都是相互解耦的,这意味着可以同时采取多种方法配合使用,如Cluster GCN + GraphSAGE。从本质上来说,在k-hop邻居诱导的子图上进行消息的聚合是指数级的运算,在不损失信息的情况下难以将基于节点采样的算法时间复杂度控制在线性级;而进行预处理将原图降采样是一个不错的解决思路,因为如果能将整个图都放入内存进行运算,GCN的时间复杂度就是线性的,但是预处理的成本是不能忽略的。天下没有免费的午餐,对于图神经网络的训练加速其实还是在信息损失和预处理开销上做权衡,需要根据实际情况采用不同的方法进行分析。
另外图本质上是一种稀疏对象,因此在设计高效以及可拓展性的问题上应该更多从数据稀疏性的角度来进行思考。但是这说起来容易做起来难,因为现代 GPU 旨在处理矩阵上的密集运算。虽然针对稀疏矩阵的定制硬件加速器可以显著提高 GNN 的及时性和可扩展性,但是相关的工作还是处于发展的初期。另外面向图计算通信策略的设计也是最近备受关注的方向。例如VLDB2022以及Webconf 2022的Best research paper以及Best student paper award均颁给了图模型加速处理的系统或者算法。其中SANCUS@VLDB2022提出了一套的分布式训练框架(SANCUS),以减少通讯量为目标,采用去中心化的机制对图神经网络的分布式训练进行加速。文章不仅在理论上证明SANCUS的收敛速度接近于全图训练,而且通过在大量真实场景图上的实验验证了SANCUS的训练效率和精度。PASCA@Webconf2022的工作尝试将消息传递的框架中的消息聚合操作和更新操作分离,定义前处理-训练-后处理的新范式从而实现分布式场景下的通信开销。

来源:PASCA@Webconf2022
5、图神经网络设计及学习空间
得益于计算资源的快速增长,以及深度神经网络强大的表征能力,深度学习成为知识挖掘的重要工具。图是一种通用的、功能强大的数据结构,它以简洁的形式表示实体及其关系,在自然科学和社会科学的应用中无处不在。但是,现实世界中图数据不管是结构、内容和任务上都千差万,在某个任务上性能最佳的 GNN 网络以及架构设计可能对于另一个任务并不适用。对于一个给定的数据集和预测任务,如何能快速获得到一个效果还不错的模型不管对于研究人员或者是应用算法工程师都是非常有意义的一件事情。对于一个给定的数据集和预测任务,怎样的神经网络架构是有效的?我们是否可以构建一种系统,从而自动地预测出好的 GNN 设计?带着这些思考, Jure Leskovec组2020年在他们的发表的图神经网络设计空间的工作中根据从三个层次上定义了GNN的设计空间,这个工作也是为后续的图自动机器以及图模型的迁移学习奠定了基础。

在给定某项任务、某个数据集的情况下我们首先可以通过:
(1)层内设计:单独某个GNN层的设计。
(2)层间设计:如何将GNN层连接起来。
(3)学习配置:如何进行机器学习的设置参数。
三个方向构建相应的GNN设计空间,接着,通过对模型进行排序来量化它们在特定任务上的性能差异,从而可以了解给定数据下的最优模型设计。另外,对于新的任务以及数据,我们也可以通过简单地计算新数据集与任务空间中已有收集的相似度,快速地识别出最相近的任务,并将其最佳模型迁移到新的数据集上进行训练。通过这种方式,对于之前从未使用过的数据集上也可以较为快速的得到较优的模型。当然不管是图上的自动机器学习以及图模型的可迁移性,不管是学术研究或者是工业应用中都是非常重要的问题,最近2年也是有非常多相关的一些探索和思考,这边我们就不再展开,更多关于图自动机器学习的工作建议大家可以关注学界清华朱文武老师组相关的综述以及他们开源的自动学习工具包AutoGL以及业界第四范式的相关工作。

来源:AutoGL
前面提到的模型设计空间主要集中模型结构层面,但是还有另一个非常重要的维度是模型的表征或者学习空间也是非常有必要进行补充。图机器学习作为图数据上进行表征学习的一种手段目标不是通过学习原始数据预测某个观察结果,而是学习数据的底层结构(underlying structure),从而可以更好对原始数据进行相应的特征学习与表达,在下游任务上取得更好的效果。

当前的大多数表征学习都是在欧几里德空间中进行的,因为欧几里德空间是自然的概括我们的直觉友好的视觉空间同时具有很好的计算以及运算优势。但是众所周知,图是非欧几里得结构的,例如复杂网络领域的研究表明,现实的网络数据(社交网络,商品网络,电信网络,疾病网络,语义网络等)中大量存在着无标度性质(scale-free),意味着现实中普遍存在着树状(tree-like)/层次结构。利用欧式空间作为表征学习的先验空间进行相应的建模必然会引起相应的误差(distortion)。因此基于不同的曲率空间的表征学习最近也引起了大家的关注。曲率是一个衡量空间弯曲程度的量,曲率越接近零,空间越平坦。在科幻小说《三体》中,人类正是利用空间曲率的变化建造出曲率飞船。如下图所示, 欧氏空间各处均匀且平坦,具备各向同性及平移不变性,因此适合建模网格数据。具有正曲率的球面空间距离度量等价于角度度量,具备旋转不变性,因此适合建模环状数据或者稠密均匀的图数据结构。而负曲率的双曲空间距离度量等价于幂律分布,适合建模无尺度网络或者树状结构。

由于现实的网络数据中大量存在着无标度性质(scale-free),意味着现实中普遍存在着树状(tree-like)/层次结构。其中,双曲空间在传统网络科学领域被视作树状/层次结构的连续表达形式,因此也更加适合用于实际数据的建模,最近也是涌现出很多优秀的工作。另外相较于欧式空间,双曲空间的容积随着半径指数级增长,因此具有更大的嵌入空间。与欧式空间不同的是,双曲空间有多个模型可以刻画,我们下面以Poincare Ball(庞加莱球)为例子简单介绍一下。

庞加莱盘是通过将嵌入空间限制在单位球内的一种双曲模型。在庞加莱球的双曲模型中,上面所有明暗相间的三角形都是相同大小的,而在我们欧式的角度去看,靠近边缘区域的三角形相对较小。换一种理解的方式,如果以欧式的角度看,把上面圆的中心当作原点,随着半径的增加,三角形的个数是越来越多的
我们可以想象一下,使用双曲空间建模就像“吹起一个气球”。假设一个干瘪的气球表面上有十亿个节点,这会是非常致密的状态。随着气球逐渐充气变大,气球表面越来越“弯曲”,节点之间就分的越开。阿里妈妈技术团队将曲率空间(Curvlearn)用于基于淘宝搜索广告场景,系统全量上线后,存储消耗量降低 80%,用户侧请求匹配精准度相对提升15%。除了推荐系统外,双曲图模型在多种不同的场景上都展现了优异的效果,对相关内容感兴趣的同学也可以参考我们今年在ECML-PKDD上双曲图表征学习的相关教程(主页传送门:https://hyperbolicgraphlearning.github.io/ )或者弗吉亚理工和亚马逊等学者在WebConf的双曲神经网络相关教程。
6、图神经网络训练系统、框架、基准平台
图神经网络算法将深度神经网络的运算(如卷积、梯度计算)与迭代图传播结合在一起: 每个顶点的特征都是由其邻居顶点的特征结合一组深度神经网络来计算。但是,现有的深度学习框架不能扩展和执行图传播模型,因此缺乏高效训练图神经网络的能力。另外现实世界中的图数据规模庞大,并且顶点之间具有复杂的依赖性,例如Facebook的社交网络图包含超过20亿个顶点和1万亿条边,这种规模的图在训练时可能会产生100 TB的数据,不同于传统的图算法,平衡的图分区不仅依赖于分区内的顶点数量,还依赖于分区内顶点邻居的数量,多层图神经网络模型中不同顶点多阶邻居的数量可能相差极大,并且这些分区之间需要频繁的数据交换,如何对图数据进行合理的分区来保证分布式训练的性能是对于分布式系统的重大挑战。另外图数据是非常稀疏的,从而这会导致分布式处理中的频繁的跨节点访问,产生大量的消息传递开销。 所以如何针对图的特殊性质减少系统开销是提高系统性能的一大挑战。工欲善其事,必先利其器。 为了支持图神经网络在大规模图上的应用,以及对更复杂图神经网络结构的探索,开发针对图神经网络的训练系统是十分有必要的。首先要提的是最为知名的两个开源框架PyG (PyTorch Geometric)和DGL (Deep Graph Library),前者是主要由斯坦福大学以及多特蒙德工业大学联合开发的基于PyTorch的图神经网络库,含了很多 GNN 相关论文中的方法实现和常用数据集,并且提供了简单易用的接口,后者则是由纽约大学以及亚马逊研究院联合主导开发的图学习框架,作为最早的学术以及工业界开源框架,两者都拥有活跃的社区支持。

除此之外很多公司根据自身业务特点,也纷纷建设自有的图神经网络框架以及数据库例如:NeuGraph、EnGN、PSGraph、AliGraph、Roc、AGL、PGL、Galileo、TuGraph、Angle Graph等。其中AliGraph由阿里巴巴计算平台和达摩院智能计算实验室开发的采样建模训练一体化的图神经网络平台。PGL (paddle graph learning)是由百度开发的基于PaddlePaddle的相应图学习框架。Angle Graph是腾讯TEG数据平台推出的大规模高性能图计算平台。
我们再聊聊基准平台的问题。在深度机器学习的核心研究或应用领域中,基准数据集以及平台都有助于识别和量化哪些类型的架构,原理或机制是通用的,并且可以推广到实际任务和大型数据集。例如神经网络模型的最新革命都是由大规模基准图像数据集的ImageNet触发的。相对于网格或者序列数据,图数据模型发展相对而言还处于自由生长的阶段。首先,数据集往往规模太小,与现实场景不符,这意味着我们很难可靠和严格地评估算法。其次,评估算法的方案不统一。基本上,每个研究工作论文都使用了自己的「训练集/测试集」数据划分方式和性能评测指标。这意味着我们很难进行跨论文跨架构的性能比较。此外,不同的研究员往往在划分数据集时采用传统的随机划分方法。为了解决图学习社区,数据、任务数据划分方式以及评估方案不一致的问题,斯坦福大学的Jure Leskovec团队2020年推出了图神经网络基准平台奠基性的工作Open Graph Benchmark(OGB)。

OGB包含一些可以现成使用的用于图上的关键任务(节点分类、链接预测、图分类等)的数据集,同时也包含了通用的代码库,以及性能评测指标的实现代码,可以进行快速的模型评估和比较。此外,OGB还设有模型性能排行榜(leaderboard),可以方便大家快速的跟进相应的研究进展。另外,2021年,OGB联合KDD CUP 与举办了第一届 OGB-LSC(OGB Large-Scale Challenge)比赛,提供来自真实世界的超大规模图数据,来完成图学习领域的节点分类、边预测和图回归三大任务,吸引了包括微软、Deepmind、Facebook、阿里巴巴、百度、字节跳动、斯坦福、MIT、北京大学等众多顶尖高校和科技公司参与。今年在NeurIPS2022的竞赛track中,根据KDD杯的经验,更新了相应的数据集并组织了第二届OGB-LSC竞赛,获奖方案目前已经公开
(快速熟悉一个领域的好方法是阅读级实验室刚毕业同学的博士论文,SNAP实验室的Rex YING以及尤佳轩必须是要拥有姓名, 分别于2016年以及2017年开始在Jure Leskovec的指导下开始进行图学习相关的研究,诸多成果也是成为了图学习发展历程路标性工作也分别在各自博士论文《Towards Expressive and Scalable Deep Representation Learning for Graphs》和《Empowering Deep Learning with Graphs》也是进性了相应的梳理。)
7、总结和展望
经过十几年的发展以及最近各行业内产业落地的应用以及实验室中理论的不断迭代,图神经网络在理论上和实践上都被证实是对图结构数据处理的一种有效方法和框架。图作为一种通用简洁以及强大的数据结构,不仅可以作为图模型的输入输出来进行非欧结构数据的挖掘和学习,也可以作为一种先验结构应用于欧式数据(文本以及图片)的模型应用中。 从长远来看,我们相信图数据+神经网络将会从一个新兴研究领域转变为用于机器学习研究和应用的标准数据 + 模型范式赋能更多的行业与场景。

(不能免俗做个展望)尽管 GNN 近年来在诸多领域取得了巨大的成功,但是随着应用场景的扩展以及实际动态变化以及未知的开放环境,除了前文中提及过的诸多问题以及挑战之外仍然有许多的方向值得进一步的探索:
图神经网络新场景以及新范式:在现实世界中,大到星球引力小到分子交互,几乎万物可以看做以某种关系连接起来,继而都可以视作一个图。从社交网络分析到推荐系统以及自然科学,我们看到了图神经网络在各个领域的相关应用探索以及从应用问题中引发的模型发展,例如智能交通中的时空交互,金融风控场景中的类别不平衡,生物化学领域中的分析结构区分问题等,因此如何在不同场景中自适应地学习与场景有关的特征依旧是重要的方向。除此之外,一方面目前GNN的主要是基于消息传递范式,利用信息传递,信息聚合,信息更新三个步骤,如何让信息传递,聚合,更新变得更加合理和高效对于GNN是目前较为重要的工作;另一方面基于消息传递框架以及同配性假设引起的信息过平滑问题以及信息瓶颈也会制约其在更加复杂的数据以及场景下的效果。整体而言,大多数GNN总是在借鉴计算机视觉以及自然语言处理中的一些思路,但是如何打破借鉴的规则,基于图数据的归纳性偏好设计更加强大的模型,给图神经网络注入专属于它的灵魂,也会是领域研究人员持续思考和努力的方向。
图结构学习:图神经网络和传统神经网络的主要区别就是以图的结构为指导,通过聚合邻居信息来学习节点表示。其中的应用实际有个潜在的假设:图结构是正确的,即图上连接都是真实可信的。例如,社交图中的边暗示了真实的朋友关系。但是,实际上图的结构并不是那么的可靠,噪音连接和偶发连接都是普遍存在的。错误的图结构加上GNN的扩散过程,会极大的降低节点表示及下游任务的表现(garbage in,garbage out)。因此如何更好的进行图结构的学习以及不同数据场景如何构建更加可信的图结构是一个重要的方向。
可信图神经网络:由于信息传递机制和图数据non-IID的特点,GNNs对于对抗攻击性十分的脆弱,很容易被节点特征和图结构上的对抗性扰动影响。例如,诈骗犯可以通过创造和一些特定高信用用户的交易来逃过基于GNNs的诈骗检测。所以研发鲁棒的图神经网络对于一些安全风险较高的领域是十分有必要的。另一方面,随着全社会对隐私保护日益重视的背景下,图神经网络的公平性以及对于数据隐私保护也是最近研究的热点。例如,阿里达摩院2022年针对图数据的联邦学习开源平台FederatedScope-GNN,今年也是获得了KDD 2022的最佳应用论文。另外,如何让训练好的图模型遗忘掉特定数据训练效果/特定参数, 以达到保护模型中隐含数据的目的的遗忘学习(Graph unlearning)也是一个值得讨论的方向。
可解释性:深度学习模型虽然实现了诸多任务上传统方法望尘莫及的性能,但是模型的复杂性导致其可解释性往往较为局限。然而,在生物信息学健康以及金融风控等众多高敏感度领域中,在评估计算模型和以及更好地理解潜在机制时,可解释性非常重要。因此,设计具有可解释性或者可以更好地可视化复杂关系的模型/架构最近也是引起了较多的关注。目前已有的工作主要还是较多参考借鉴于文本和图像中对于可以解释性的处理方式。例如基于梯度变化或者输入扰动的方法(e.g GNNExplainer)。近期,一些研究人员尝试利用因果筛选的方对可解释性衡量框架进行探索,从而更好地引出基于不变学习的内在可解释性的图神经网路,也为图模型的可解释性提供了一些新的思路。
分布外泛化:一般的学习问题都是在一个训练集上完成模型训练,而后模型需要在一个新的测试集上给出结果,当测试数据分布与训练分布呈现明显不同时,模型的泛化误差则很难被控制。目前大多数的图神经网络(GNN)方法没有考虑训练图和测试图之间的不可知偏差,从而导致GNN在分布外(OOD)图上的泛化性能变差。然而现实中的许多场景要求模型与开放动态的环境进行交互,模型在训练阶段需要考虑未来新出现的实体或来自未知分布的样本,例如推荐系统中新出现的用户/商品,在线广告系统中新平台的用户画像/行为特征,动态网络中新出现的节点或连边关系等。因此如何利用有限的观测数据,学习一个稳定的GNN模型,能够泛化到未知或者数据有限的新环境也是一个重要的研究方向。
图数据预训练以及通用模型:预训练范式在计算机视觉以及自然语言处理的领域取得革命性成功,在诸多任务中证明了其强大的能力。虽然GNN已经具备了一些相对成熟的模型以及成功的应用,但是当前仍囿于面向特定任务使用大量标注数据训练模型的深度学习,当任务改变或标签不足时往往效果就会差强人意。因此也自然引发大家对于在图数据场景进行通用模型的探索和思考。预训练的关键在于丰富的大量训练数据, 可迁移的知识,强大的骨干模型以及有效的训练方法。相较于计算机视觉以及自然语言处理中较为明确的语义信息,因为不同的图数据结构千差万别,图中什么知识是可迁移的仍然是一个较为开放的问题。另外,目前深层以及通用的GNN模型虽有研究但仍未带来革命性的提升。幸运的是,图机器学习社区已经积累了大规模的图数据,并且已经发展出诸如图重构的自监督训练方法。随着后续深层GNN、表达能力更强的GNN以及图自监督新范式等研究的进一步探索,相信最终实现泛用性强的通用模型。
软硬件协同:随着图学习的应用和研究发展的推进, GNN肯定会更深入地集成到 PyTorch,TensorFlow,Mindpsore等标准框架和平台中。进一步提高图模型的可拓展性,更加硬件亲和的算法框架以及软件协同的硬件加速方案是大势所趋。虽然面向图神经网络应用的专用加速结构慢慢涌现,为图神经网络定制计算硬件单元和片上存储层次,优化计算和访存行为的专属芯片已有一些成功,但是这些技术仍然处理早期的阶段,面临巨大的挑战以及相应也是提供了诸多的机遇。