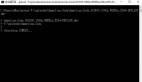
import gopup as gp
df = gp.weibo_index(word="疫情", time_type="1hour")
print(df)
1.
2.
3.
Output:
疫情
index
2022-12-1718:15:00185442022-12-1718:20:00149272022-12-1718:25:00130042022-12-1718:30:00131452022-12-1718:35:00134852022-12-1718:40:00140912022-12-1718:45:00142652022-12-1718:50:00141152022-12-1718:55:00153132022-12-1719:00:00143462022-12-1719:05:00144572022-12-1719:10:00134952022-12-1719:15:0014133
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
https://github.com/justinzm/gopup
GeneralNewsExtractor
该项目基于《基于文本及符号密度的网页正文提取方法》论文,使用 Python 实现的正文抽取器,可以用来提取 HTML 中正文的内容、作者、标题。
>>> from gne import GeneralNewsExtractor
>>> html = '''经过渲染的网页 HTML 代码'''
>>> extractor = GeneralNewsExtractor()
>>> result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
>>> print(result)
from DecryptLogin import login
# the instanced Login class object
lg = login.Login()
# use the provided api function to login in the target website (e.g., twitter)
infos_return, session = lg.twitter(username='Your Username', password='Your Password')
from fake_useragent import UserAgent
ua = UserAgent()
ua.ie
# Mozilla/5.0(Windows; U; MSIE 9.0; Windows NT 9.0; en-US);
ua.msie
# Mozilla/5.0(compatible; MSIE 10.0; Macintosh; Intel Mac OS X 10_7_3; Trident/6.0)'ua['Internet Explorer']# Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; GTB7.4; InfoPath.2; SV1; .NET CLR 3.3.69573; WOW64; en-US)ua.opera# Opera/9.80 (X11; Linux i686; U; ru) Presto/2.8.131 Version/11.11ua.chrome# Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2'
ua.google
# Mozilla/5.0(Macintosh; Intel Mac OS X 10_7_4) AppleWebKit/537.13(KHTML,like Gecko) Chrome/24.0.1290.1 Safari/537.13
ua['google chrome']
# Mozilla/5.0(X11; CrOS i686 2268.111.0) AppleWebKit/536.11(KHTML,like Gecko) Chrome/20.0.1132.57 Safari/536.11
ua.firefox
# Mozilla/5.0(Windows NT 6.2; Win64; x64; rv:16.0.1) Gecko/20121011 Firefox/16.0.1
ua.ff
# Mozilla/5.0(X11; Ubuntu; Linux i686; rv:15.0) Gecko/20100101 Firefox/15.0.1
ua.safari
# Mozilla/5.0(iPad; CPU OS 6_0 like Mac OS X) AppleWebKit/536.26(KHTML,like Gecko) Version/6.0 Mobile/10A5355d Safari/8536.25
# and the best one, get a random browser user-agent string
ua.random
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
https://github.com/fake-useragent/fake-useragent
Web 相关
Python Web 有太多优秀且老牌的库了,比如 Django,Flask 就不说了,大家都知道,我们介绍几个小众但是好用的。
import click
@click.command()
@click.option("--count", default=1, help="Number of greetings.")
@click.option("--name", prompt="Your name", help="The person to greet.")
def hello(count, name):"""Simple program that greets NAME for a total of COUNT times."""
for _ in range(count):
click.echo(f"Hello, {name}!")
if __name__ =='__main__':
hello()