C语言几乎唯一的缺点就是,需要手动管理内存。
抛开这点之外,我觉得其他语言都不如C语言。
所以,虽然自动内存管理比较复杂,但我还是给scf编译器框架加了静态的GC算法。
在编程方面,自动内存管理一般叫GC算法,是英文Garbage Collection的缩写。
栈内存的管理比较简单,是由编译器根据函数调用链而自动管理的。
堆内存的管理,在C语言里是由程序员手动管理的。
因为程序员管理错了堆内存而导致的BUG,是C语言最常见、也最难搞的BUG。
所以,后来的编程语言都对内存管理做了简化,例如C++的智能指针。
C++的智能指针,是一种半自动的内存管理机制:
它把一个堆内存的指针放在一个类的成员变量里,利用局部对象离开作用域时的析构函数,来完成堆内存的释放。
所以C++的效率比其他语言快得多,因为局部对象什么时候离开作用域,是可以在编译时就确定的,不需要在运行时做额外的处理。
也就是说,C++的智能指针是静态的GC算法。
在编译时就处理好的算法,是静态的算法。
在运行时才会处理的算法,是动态的算法。
动态的算法依赖于运行时状态,对程序的速度有较大的影响:
- 因为框架在处理对象内存的回收时,用户程序不得不暂停,
- 否则两边发生竞争条件,那就是跟C语言的野指针一样的BUG。
写过C语言的都知道,多线程的野指针是非常难查的BUG,因为程序跑飞了不知道会core在哪里,而且BUG也不是必现的。
为什么程序员怕有主控软件的交通工具?
因为程序员知道多线程+竞争条件+野指针 == 随机crash + 事后找不到第一现场
动态的GC算法,为了避免出现第2种情况,那就只能使用第1种情况。
1、GC算法有必要是动态的吗?
实际上没必要,否则C语言怎么手动管理内存的。
C语言的free()代码肯定是在编译之前就写好了的!
只要写对了free()位置,C语言既不会出BUG,也不会内存泄漏。
所以,编译器只要代替程序员添加free(),就可以自动管理内存了。
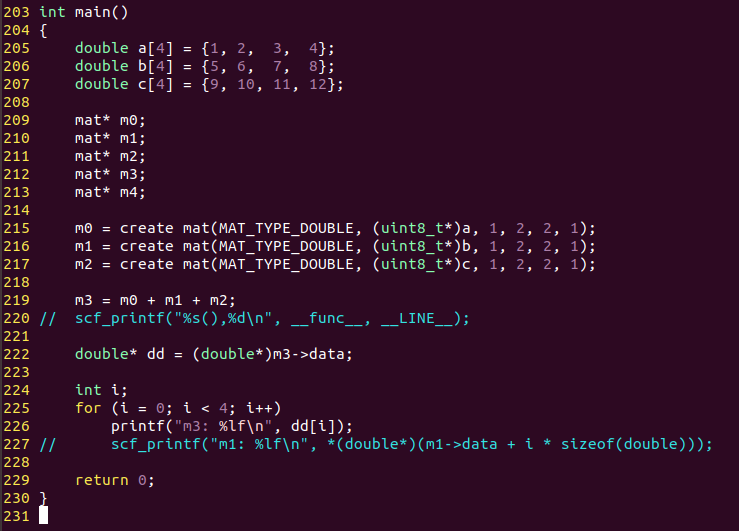
free()的添加位置,当然是在变量离开作用域时。
如上图:
有4个对象变量m0, m1, m2, m3,
main()函数返回时也是它们离开作用域的时候,所以在main函数的结尾自动添加释放代码,程序员就不用手动释放内存了。
2、怎么检测变量什么时候离开作用域?
在编译器的后端:
1)代码的每个基本块都是流程图上的一个节点,
2)基本块之间通过跳转联系起来,
3)基本块内部的代码是顺序运行的。
所以,释放内存的代码需要加在两个基本块之间。
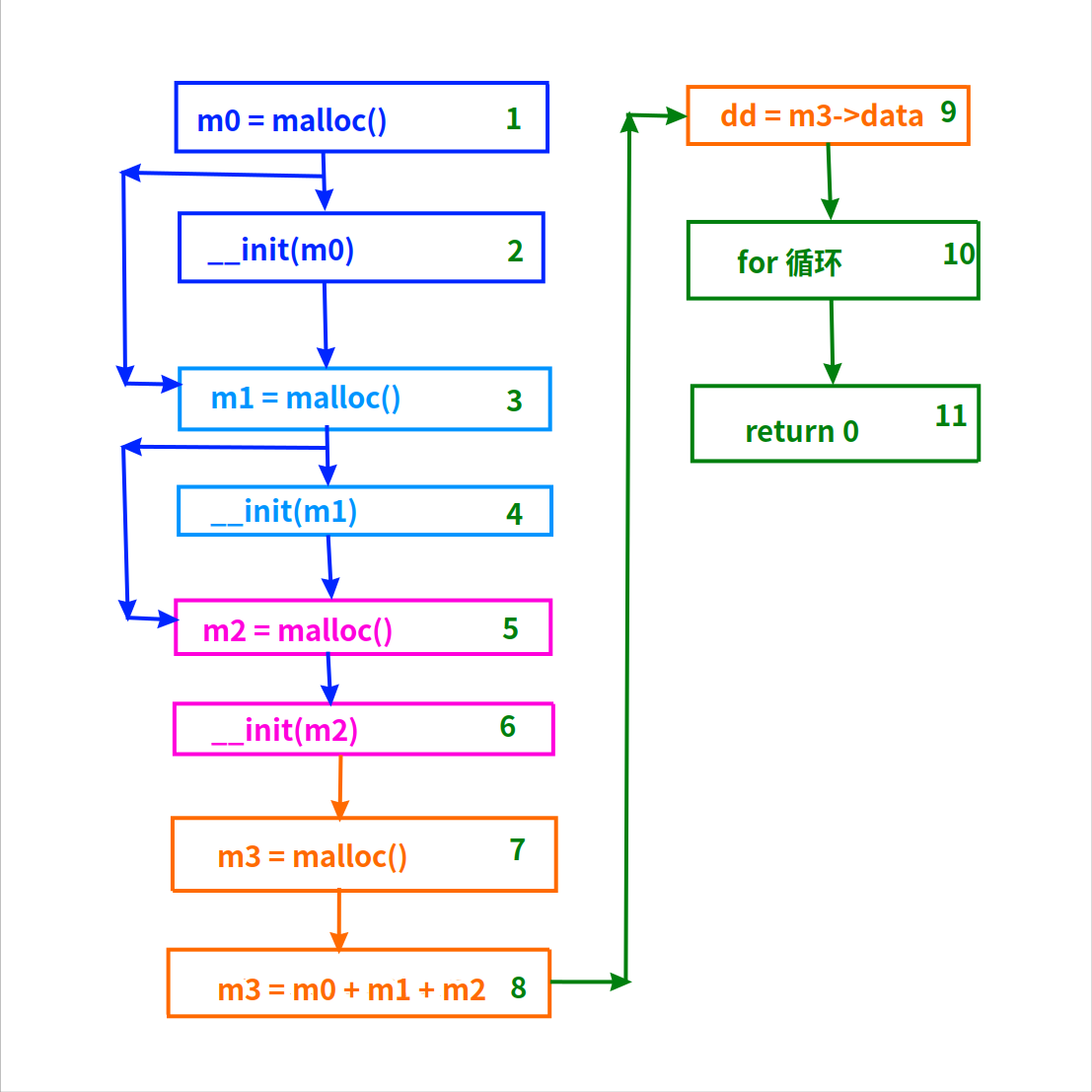
上述main()函数的流程图
上图是前面的main()函数的流程图。
创建一个对象分两步:第一步调用malloc()申请内存,第二步调用构造函数__init()初始化内存。
(为了简化代码,我没有做返回值为NULL的检查)
在第8个基本块 m3 = m0 + m1 + m2 之后,m0, m1, m2 就不再使用了,也就是它们3个离开作用域了。
即使在源代码层面这时m0, m1, m2依然处于main()函数的作用域内,但对后端来说它们已经离开作用域了,因为之后的基本块都不再使用它们了。
所以,对m0, m1, m2的释放代码,应该加在第8和第9号基本块之间。
第9号基本块会把指针 m3->data 赋值给dd,这会让(m3->data)内存的引用计数+1。
对m3的释放代码可以放在第9和第10之间,之后不会再使用m3了:这会让m3->data的引用计数-1。
这时,内存数据有且只有1个引用计数(一开始自带1个),同时有且只有指针dd指向它。
指针dd的释放在for循环之后,即第10和11之间:这里的释放会让引用计数减少到0。
在引用计数为0时,要调用free()函数,把内存还给系统。
GC算法的要点有3个:
1)什么时间调用的malloc(),
2)什么时间有指针的赋值,要把引用计数+1,
3)什么时间离开作用域,也就是后续不再使用对象变量,要把引用计数-1,如果减少之后为0,就调用free().
3、跨函数的指针分析,
有时候,申请的内存并不会在当前函数内释放,而是返回给更上层的主调函数。
这时的GC算法,就需要跨越函数的调用链,进行指针分析。

mat类的构造函数__init()
前面的mat对象的成员指针 m3->data,就是需要跨函数分析的指针。
它是在构造函数里申请的内存,因为是成员变量,所以要在析构函数里释放。
如果是局部变量,就在当前函数内释放:因为局部变量的作用域就是当前函数。
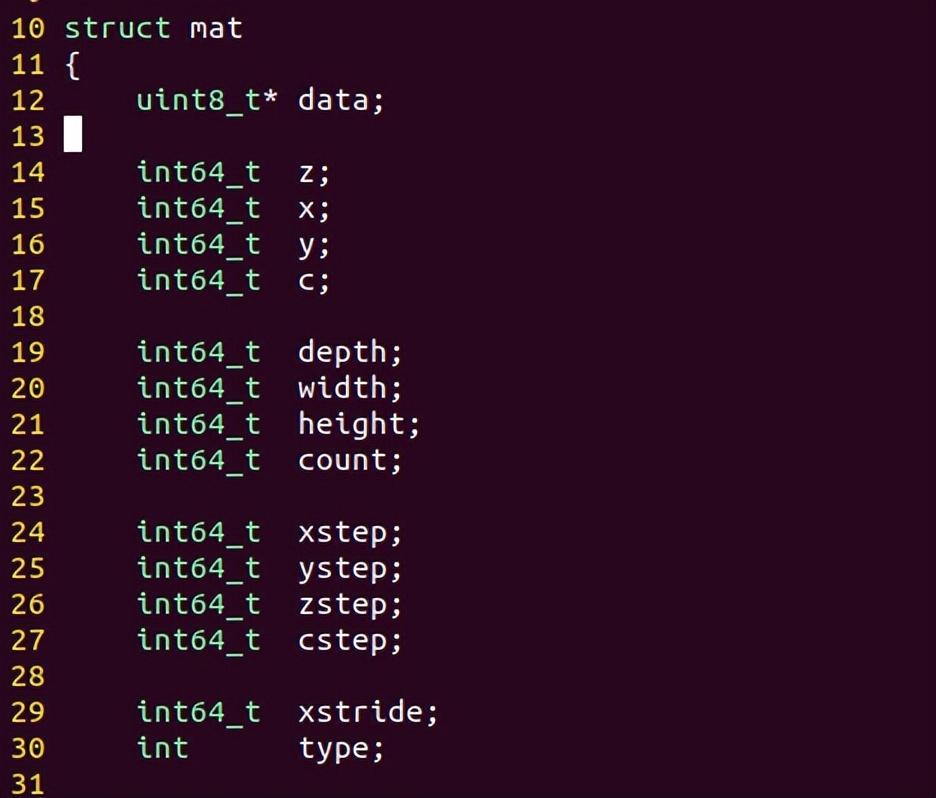
mat类的声明,成员变量部分
成员变量的有效时间,是伴随着当前对象的。
局部变量的有效时间,是伴随着当前函数的。
成员变量在构造函数返回时依然有效,所以要把它是malloc()申请的这个信息,传递到更上层的函数。
这样:
1)在main()里才知道它是malloc()申请的,
2)在 dd = m3->data 时才知道给它指向的内存引用计数+1,
3)在释放m3时,析构函数把引用计数-1之后,引用计数才不为0:内存依然是有效的,这时指针dd依然指向它。
否则,dd就是野指针了!
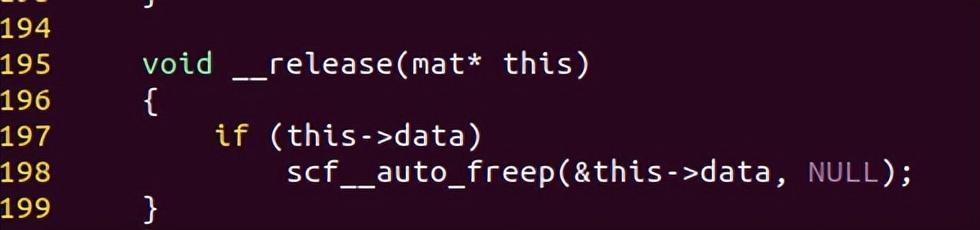
mat类的析构函数__release()
函数调用链,在语义分析时是很容易确定的。
抽象语法树AST上的每一个函数调用,必然有一个主调函数、有一个被调函数。
主调和被调,构成了整个程序的函数调用图:
最顶层的是main()函数,最底层的是malloc()函数。
以malloc为起点、main为终点,做图的宽度优先搜索,就可以获取整个调用链。
然后从离malloc最近的函数开始,一层层的分析就行了。
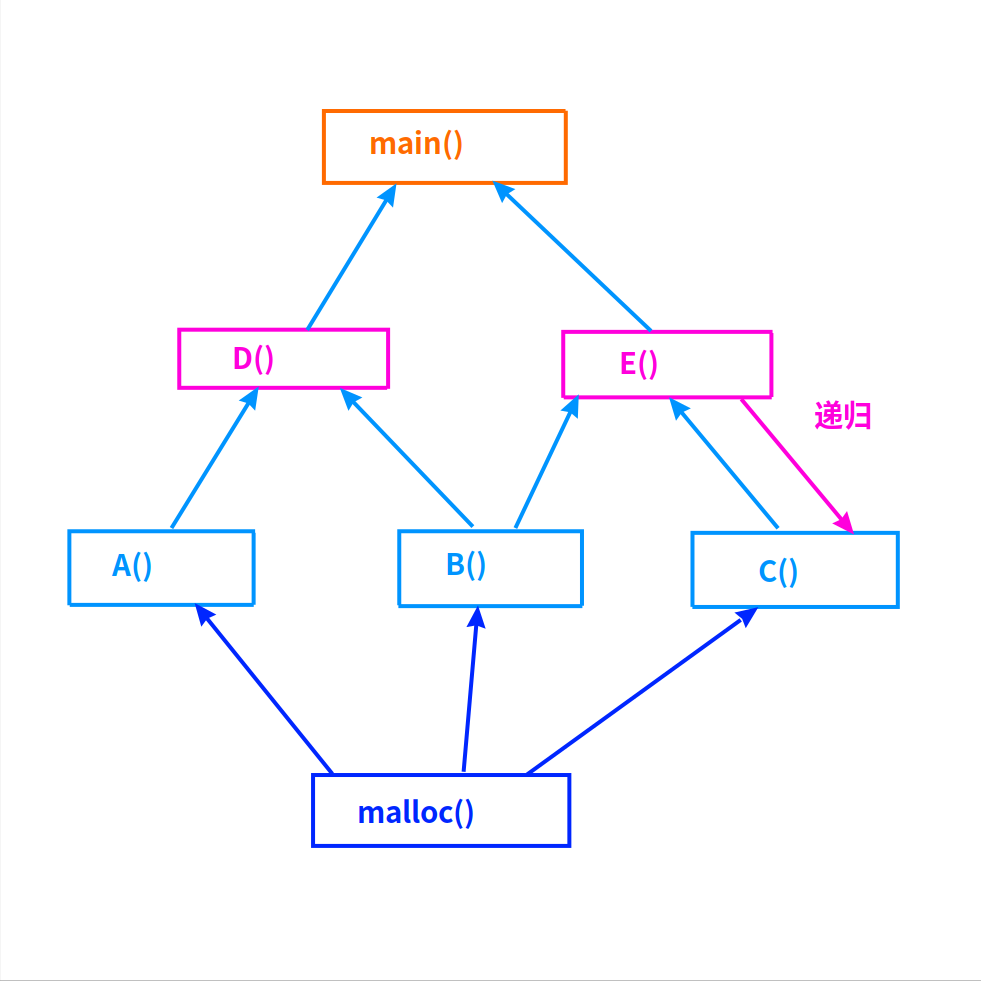
函数调用图
一定是用图的宽度优先搜索(BFS)!
不能用深度优先搜索(DFS),因为一个上层函数可能调用多个下层函数,而这多个下层函数里都malloc了内存。
如上图:
如果是DFS,分析顺序是A->D,这样D调用B而申请的内存就会被漏过去了。
如果是BFS,分析顺序是A->B->C->D->E,这样任何函数申请的内存如果传递给上层,(在分析上层函数时)都不会被漏过去。
4、递归调用的指针分析
上图的C()和E()之间的互相调用构成递归,表现为函数调用图上的回路。
这种情况下,两个函数里申请的内存会互相传递,属于最复杂的一种情况!
在编译器里的处理方法是:
用do while循环检查内存的传递情况,记录传递的变量和计数,直到不再发生变化为止。
最后,就是在合适的位置添加free()代码了:
最后的总是最简单的,the last is the simplest.