













一、前情提示
上一篇文章《MQ保证读写消息不丢失,这个你都不会就等着被开除吧...》,我们初步介绍了之前制定的那些消息中间件数据不丢失的技术方案遗留的问题。
一个最大的问题,就是生产者投递出去的消息,可能会丢失。
丢失的原因有很多,比如消息在网络传输到一半的时候因为网络故障就丢了,或者是消息投递到MQ的内存时,MQ突发故障宕机导致消息就丢失了。
针对这种生产者投递数据丢失的问题,RabbitMQ实际上是提供了一些机制的。
比如,有一种重量级的机制,就是事务消息机制。采用类事务的机制把消息投递到MQ,可以保证消息不丢失,但是性能极差,经过测试性能会呈现几百倍的下降。
所以说现在一般是不会用这种过于重量级的机制,而是会用轻量级的confirm机制。
但是我们这篇文章还不能直接讲解生产者保证消息不丢失的confirm机制,因为这种confirm机制实际上是采用了类似消费者的ack机制来实现的。
所以,要深入理解confirm机制,我们得先从这篇文章开始,深入的分析一下消费者手动ack机制保证消息不丢失的底层原理。
二、ack机制回顾
其实手动ack机制非常的简单,必须要消费者确保自己处理完毕了一个消息,才能手动发送ack给MQ,MQ收到ack之后才会删除这个消息。
如果消费者还没发送ack,自己就宕机了,此时MQ感知到他的宕机,就会重新投递这条消息给其他的消费者实例。
通过这种机制保证消费者实例宕机的时候,数据是不会丢失的。
三、ack机制实现原理:delivery tag
如果你写好了一个消费者服务的代码,让他开始从RabbitMQ消费数据,这时这个消费者服务实例就会自己注册到RabbitMQ。
所以,RabbitMQ其实是知道有哪些消费者服务实例存在的。
大家看看下面的图,直观的感受一下:
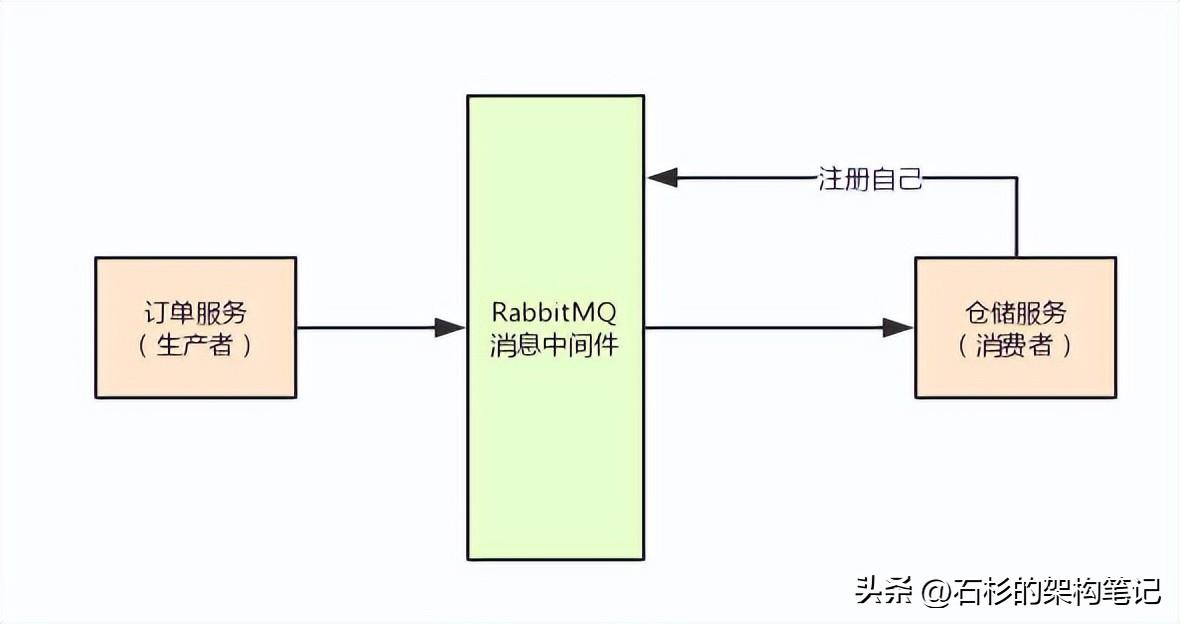
接着,RabbitMQ就会通过自己内部的一个“basic.delivery”方法来投递消息到仓储服务里去,让他消费消息。
投递的时候,会给这次消息的投递带上一个重要的东西,就是“delivery tag”,你可以认为是本次消息投递的一个唯一标识。
这个所谓的唯一标识,有点类似于一个ID,比如说消息本次投递到一个仓储服务实例的唯一ID。通过这个唯一ID,我们就可以定位一次消息投递。
所以这个delivery tag机制不要看很简单,实际上他是后面要说的很多机制的核心基础。
而且这里要给大家强调另外一个概念,就是每个消费者从RabbitMQ获取消息的时候,都是通过一个channel的概念来进行的。
大家回看一下下面的消费者代码片段,我们必须是先对指定机器上部署的RabbitMQ建立连接,然后通过这个连接获取一个channel。
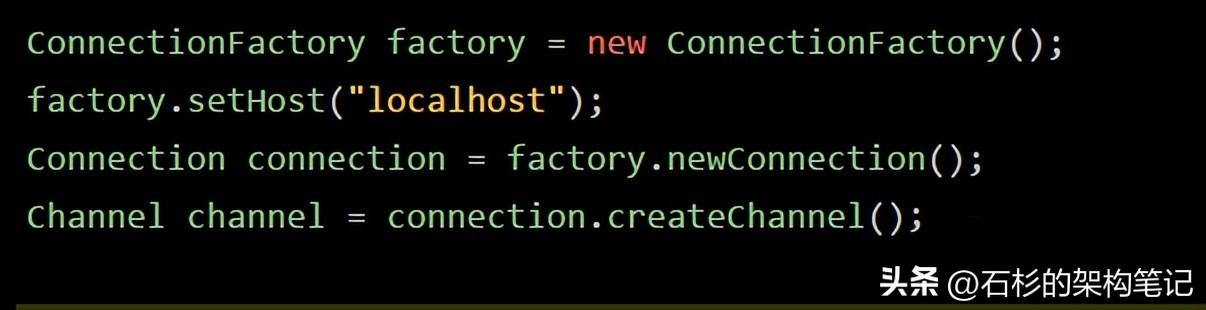
而且如果大家还有点印象的话,我们在仓储服务里对消息的消费、ack等操作,全部都是基于这个channel来进行的,channel又有点类似于是我们跟RabbitMQ进行通信的这么一个句柄,比如看看下面的代码:
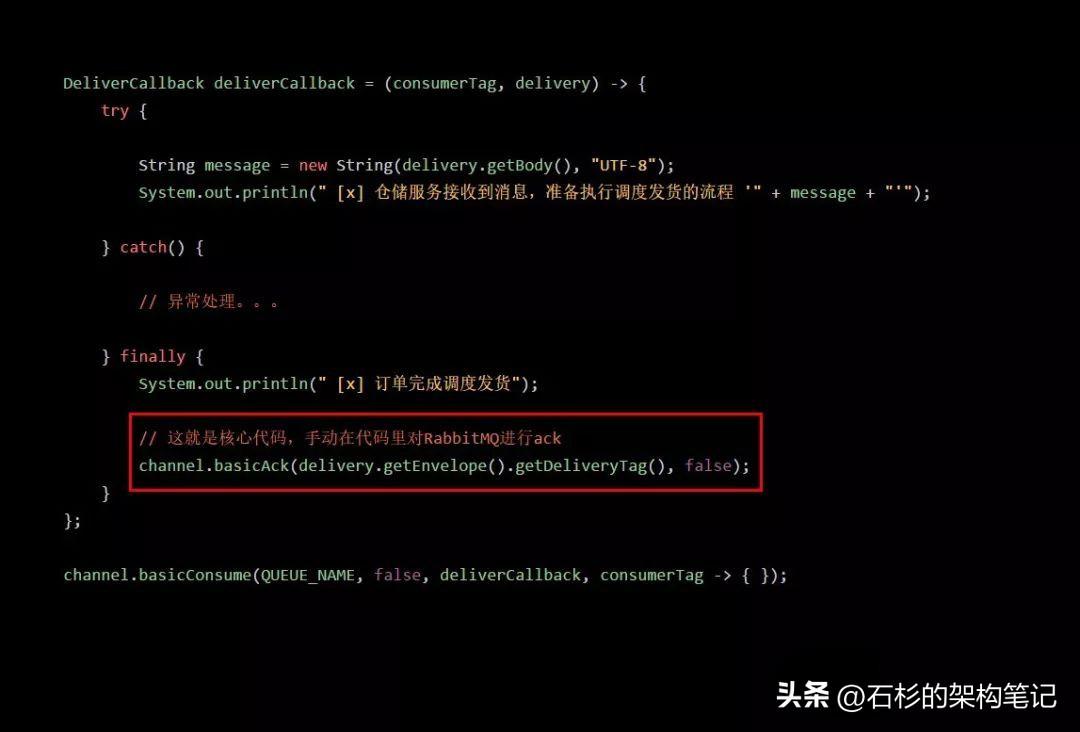
另外这里提一句:之前写那篇文章讲解手动ack保证数据不丢失的时候,有很多人提出疑问:为什么上面代码里直接是try finally,如果代码有异常,那还是会直接执行finally里的手动ack?其实很简单,自己加上catch就可以了。
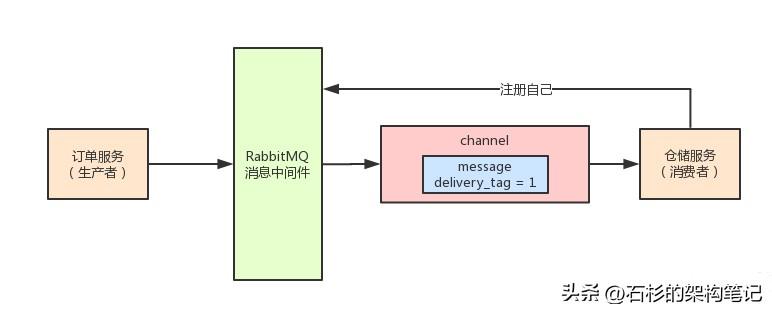
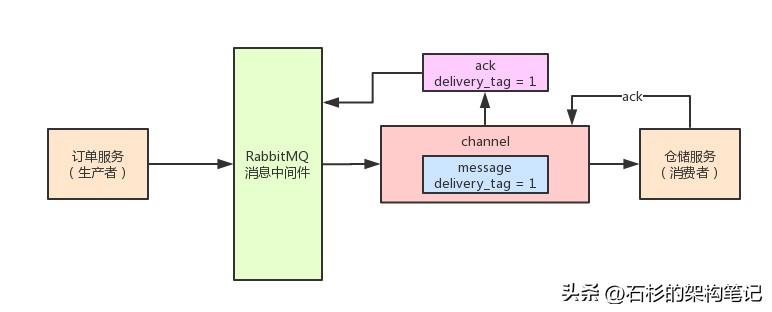
好的,咱们继续。你大概可以认为这个channel就是进行数据传输的一个管道吧。对于每个channel而言,一个“delivery tag”就可以唯一的标识一次消息投递,这个delivery tag大致而言就是一个不断增长的数字。
大家来看看下面的图,相信会很好理解的:
如果采用手动ack机制,实际上仓储服务每次消费了一条消息,处理完毕完成调度发货之后,就会发送一个ack消息给RabbitMQ服务器,这个ack消息是会带上自己本次消息的delivery tag的。
咱们看看下面的ack代码,是不是带上了一个delivery tag?
然后,RabbitMQ根据哪个channel的哪个delivery tag,不就可以唯一定位一次消息投递了?
接下来就可以对那条消息删除,标识为已经处理完毕。
这里大家必须注意的一点,就是delivery tag仅仅在一个channel内部是唯一标识消息投递的。
所以说,你ack一条消息的时候,必须是通过接受这条消息的同一个channel来进行。
大家看看下面的图,直观的感受一下。
其实这里还有一个很重要的点,就是我们可以设置一个参数,然后就批量的发送ack消息给RabbitMQ,这样可以提升整体的性能和吞吐量。
比如下面那行代码,把第二个参数设置为true就可以了。
看到这里,大家应该对这个ack机制的底层原理有了稍微进一步的认识了。起码是知道delivery tag是啥东西了,他是实现ack的一个底层机制。
然后,我们再来简单回顾一下自动ack、手动ack的区别。
实际上默认用自动ack,是非常简单的。RabbitMQ只要投递一个消息出去给仓储服务,那么他立马就把这个消息给标记为删除,因为他是不管仓储服务到底接收到没有,处理完没有的。
所以这种情况下,性能很好,但是数据容易丢失。
如果手动ack,那么就是必须等仓储服务完成商品调度发货以后,才会手动发送ack给RabbitMQ,此时RabbitMQ才会认为消息处理完毕,然后才会标记消息为删除。
这样在发送ack之前,仓储服务宕机,RabbitMQ会重发消息给另外一个仓储服务实例,保证数据不丢。
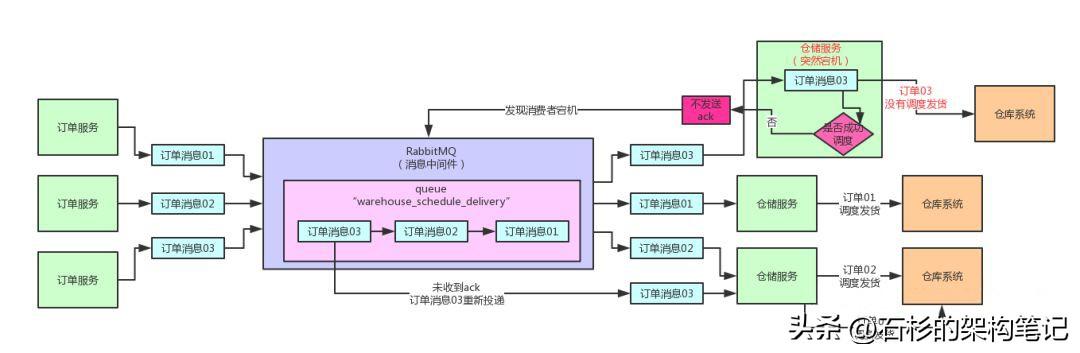
四、RabbitMQ如何感知到仓储服务实例宕机
之前就有同学提出过这个问题,但是其实要搞清楚这个问题,其实不需要深入的探索底层,只要自己大致的思考和推测一下就可以了。
如果你的仓储服务实例接收到了消息,但是没有来得及调度发货,没有发送ack,此时他宕机了。
我们想一想就知道,RabbitMQ之前既然收到了仓储服务实例的注册,因此他们之间必然是建立有某种联系的。
一旦某个仓储服务实例宕机,那么RabbitMQ就必然会感知到他的宕机,而且对发送给他的还没ack的消息,都发送给其他仓储服务实例。
所以这个问题以后有机会我们可以深入聊一聊,在这里,大家其实先建立起来这种认识即可。
我们再回头看看下面的架构图:
五、仓储服务处理失败时的消息重发
首先,我们来看看下面一段代码:
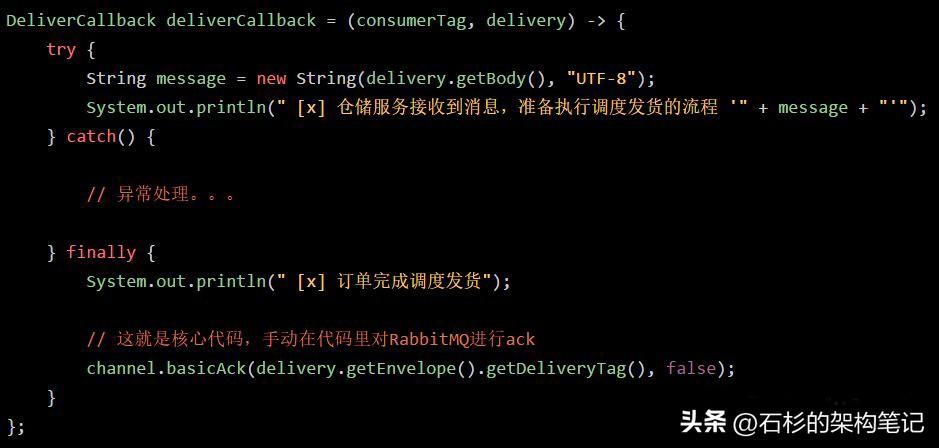
假如说某个仓储服务实例处理某个消息失败了,此时会进入catch代码块,那么此时我们怎么办呢?难道还是直接ack消息吗?
当然不是了,你要是还是ack,那会导致消息被删除,但是实际没有完成调度发货。
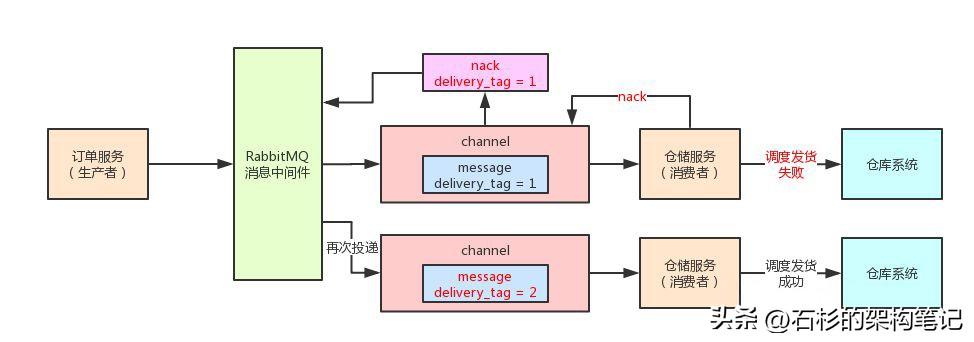
这样的话,数据不是还是丢失了吗?因此,合理的方式是使用nack操作。
就是通知RabbitMQ自己没处理成功消息,然后让RabbitMQ将这个消息再次投递给其他的仓储服务实例尝试去完成调度发货的任务。
我们只要在catch代码块里加入下面的代码即可:
注意上面第二个参数是true,意思就是让RabbitMQ把这条消息重新投递给其他的仓储服务实例,因为自己没处理成功。
你要是设置为false的话,就会导致RabbitMQ知道你处理失败,但是还是删除这条消息,这是不对的。
同样,我们还是来一张图,大家一起来感受一下:
六、阶段总结
这篇文章对之前的ack机制做了进一步的分析,包括底层的delivery tag机制,以及消息处理失败时的消息重发。
通过ack机制、消息重发等这套机制的落地实现,就可以保证一个消费者服务自身突然宕机、消息处理失败等场景下,都不会丢失数据。























