继 BERT 之后,研究者们注意到了大规模预训练模型的潜力,不同的预训练任务、模型架构、训练策略等被提出。但 BERT 类模型通常存在两大缺点:一是过分依赖有标签数据;二是存在过拟合现象。
具体而言,现在的语言模型都倾向于两段式框架,即预训练 + 下游任务微调,但是在针对下游任务的微调过程中又需要大量的样本,否则效果很差,然而标注数据的成本高昂。还有就是标注数据有限,模型只能拟合训练数据分布,但数据较少的话容易造成过拟合,致使模型的泛化能力下降。
作为大模型的开路先锋,大型预训练语言模型,特别是 GPT-3 已经显示出令人惊讶的 ICL(In-Context Learning)能力。与微调需要额外的参数更新不同,ICL 只需要一些演示「输入 - 标签」对,模型就可以预测标签甚至是没见过的输入标签。在许多下游任务中,一个大型 GPT 模型可以获得相当好的性能,甚至超过了一些经过监督微调的小型模型。
为何 ICL 的表现如此优秀,在来自 OpenAI 的一篇长达 70 多页的论文《Language Models are Few-Shot Learners》中,他们对 ICL 进行了探索,其目的是让 GPT-3 使用更少的领域数据、且不经过微调去解决问题。
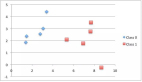
如下图所示,ICL 包含三种分类:Few-shot learning,允许输入数条示例和一则任务说明;One-shot learning,只允许输入一条示例和一则任务说明;Zero-shot learning,不允许输入任何示例,只允许输入一则任务说明。结果显示 ICL 不需要进行反向传播,仅需要把少量标注样本放在输入文本的上下文中即可诱导 GPT-3 输出答案。

GPT-3 in-context learning
实验证明在 Few-shot 下 GPT-3 有很好的表现:

为什么 GPT 可以在 In-Context 中学习?
尽管 ICL 在性能上取得了巨大的成功,但其工作机制仍然是一个有待研究的开放性问题。为了更好地理解 ICL 是如何工作的,我们接下来介绍一篇来自北大、清华等机构的研究是如何解释的。

- 论文地址:https://arxiv.org/pdf/2212.10559v2.pdf
- 项目地址:https://github.com/microsoft/LMOps
用网友的话来总结,即:「这项工作表明,GPT 自然地学会了使用内部优化来执行某些运行。该研究同时提供了经验性证据来证明 In-Context Learning 和显式微调在多个层面上表现相似。」
为了更好地理解 ICL 是如何工作的,该研究将语言模型解释为元优化器,ICL 解释为一个元优化过程,并将 ICL 理解为一种隐式微调,试图在基于 GPT 的 ICL 和微调之间建立联系。从理论上讲,该研究发现 Transformer 的注意力具有基于梯度下降的对偶优化形式。
在此基础上,该研究提出了一个新的视角来解释 ICL:GPT 首先根据演示示例生成元梯度,然后将这些元梯度应用于原始 GPT 以构建 ICL 模型。
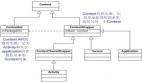
如图 1 所示,ICL 和显式微调共享基于梯度下降的对偶优化形式。唯一的区别是 ICL 通过前向计算产生元梯度,而微调通过反向传播计算梯度。因此,将 ICL 理解为某种隐式微调是合理的。

ICR 执行隐式微调
该研究首先定性分析了松弛线性注意力(relaxed linear attention)形式下的 Transformer 注意力,以找出它与基于梯度下降优化之间的对偶形式。然后,该研究将 ICL 与显式微调进行比较,并在这两种优化形式之间建立联系。基于这些理论发现,他们建议将 ICL 理解为一种隐式微调。
首先该研究将 Transforme 注意力看作元优化,将 ICL 解释为一个元优化过程:(1)一个基于 Transformer 的预训练语言模型作为元优化器;(2)通过前向计算根据实例生成元梯度;(3)通过注意力,将元梯度应用于原始语言模型,构建 ICL。
接下来是 ICL 与微调的比较。通过一系列设置后,该研究发现 ICL 与微调有许多共同特性。他们从以下四个方面来组织这些共性:两者都执行梯度下降;相同的训练信息;训练例子的因果顺序相同;都是围绕注意力展开。
考虑到 ICL 和微调之间的所有这些共同属性,该研究认为将 ICL 理解为一种隐式微调是合理的。在本文的其余部分,该研究从多个方面根据经验比较 ICL 和微调,以提供支持这种理解的定量结果。
实验结果
该研究进行了一系列实验来全面比较 ICL 的行为和基于实际任务的显式微调,在六个分类任务上,他们比较了预训练 GPT 在 ICL 和微调设置中关于预测、注意力输出和注意力得分的情况。正如预期的那样,ICL 在预测、表示和注意力级别等方面都与显式微调高度相似。这些结果有力地证明了这一合理性:ICL 执行隐式微调。
此外,受元优化理解的启发,该研究通过类比基于动量的梯度下降算法设计了一种基于动量的注意力。它始终优于 vanilla attention 的性能。
表 2 显示了在六个分类数据集上 ZSL( Zero-Shot Learning )、ICL 和微调(FT)设置中的验证精度。与 ZSL 相比,ICL 和微调都取得了相当大的改进,这意味着所做的优化都有助于这些下游任务。此外,该研究发现 ICL 在 Few-shot 场景中比微调更好。

表 3 中显示了 6 个数据集上 2 个 GPT 模型的 Rec2FTP 分数。平均而言,ICL 可以从 ZSL 中正确地预测 87.64% 的微调能够纠正的示例。这些结果表明在预测层面,ICL 可以覆盖大多数正确的微调行为。
表 3 还显示了 6 个数据集上 2 个 GPT 模型的示例与层的平均 SimAOU 分数。为了比较,该研究还提供了一个基线指标(Random SimAOU),用来计算 ICL 更新和随机生成更新之间的相似性。从表中可以看出,ICL 更新更类似于微调更新而非随机更新,这意味着在表示层面上,ICL 倾向于按照微调改变的方向来改变注意力结果。
最后,表 3 还显示了 6 个数据集上 2 个 GPT 模型的示例与层的平均 SimAM 分数。作为 SimAM 的基线指标,ZSL SimAM 计算 ICL 注意力权重和 ZSL 注意力权重之间的相似性。通过比较这两个指标,该研究发现,与 ZSL 相比,ICL 更倾向于生成类似于微调的注意力权重。同样在注意力行为层面,该研究证明 ICL 的行为类似于微调。

为了更彻底地探究 ICL 和微调之间的相似性,该研究比较了不同层的 SimAOU 和 SimAM 分数。通过从每个数据集中随机抽取 50 个验证示例,分别绘制了如下图 2 和图 3 所示的 SimAOU 和 SimAM 箱形图。
从图中可以发现,SimAOU 和 SimAM 在较低层出现波动,并且往往在较高层更加稳定。这种现象说明了 ICL 进行的元优化具有前向累积效应,随着累积的增加,ICL 的行为更类似于较高层的微调。


总结
总结而言,本文旨在解释基于 GPT 的 ICL 工作机制。从理论上讲,该研究找出了 ICL 的对偶形式,并建议将 ICL 理解为元优化过程。此外,该研究在 ICL 和特定微调设置之间建立了联系,发现将 ICL 视为一种隐式微调是合理的。为了支持对 ICL 执行隐式微调的理解,该研究综合比较了 ICL 和基于实际任务的微调的行为。结果证明,ICL 类似于显式微调。
此外,受元优化的启发,该研究设计了一种基于动量的注意力,以实现一致的性能改进。作者希望该研究能够帮助更多的人深入了解 ICL 应用和模型设计。