













近日,阿里云机器学习PAI关于大模型稀疏训练的论文《Parameter-Efficient Sparsity for Large Language Models Fine-Tuning》被人工智能顶会IJCAI 2022接收。
论文提出了一种参数高效的稀疏训练算法PST,通过分析权重的重要性指标,得出了其拥有两个特性:低秩性和结构性。根据这一结论,PST算法引入了两组小矩阵来计算权重的重要性,相比于原本需要与权重一样大的矩阵来保存和更新重要性指标,稀疏训练需要更新的参数量大大减少。对比常用的稀疏训练算法,PST算法可以在仅更新1.5%的参数的情况下,达到相近的稀疏模型精度。
背景
近几年各大公司和研究机构提出了各式各样的大模型,这些大模型拥有的参数从百亿级别到万亿级别不等,甚至于已经出现十万亿级别的超大模型。这些模型需要耗费大量的硬件资源进行训练和部署,从而导致它们面对着难以落地应用的困境。因此,如何减少大模型训练和部署所需的资源成为了一个急需解决的问题。
模型压缩技术可以有效的减少模型部署所需的资源,其中稀疏通过移除部分权重,使得模型中的计算可以从稠密计算转换为稀疏计算,从而达到减少内存占用,加快计算速度的效果。同时,稀疏相比于其他模型压缩方法(结构化剪枝/量化),可以在保证模型精度的情况下达到更高的压缩率,更加合适拥有大量参数的大模型。
挑战
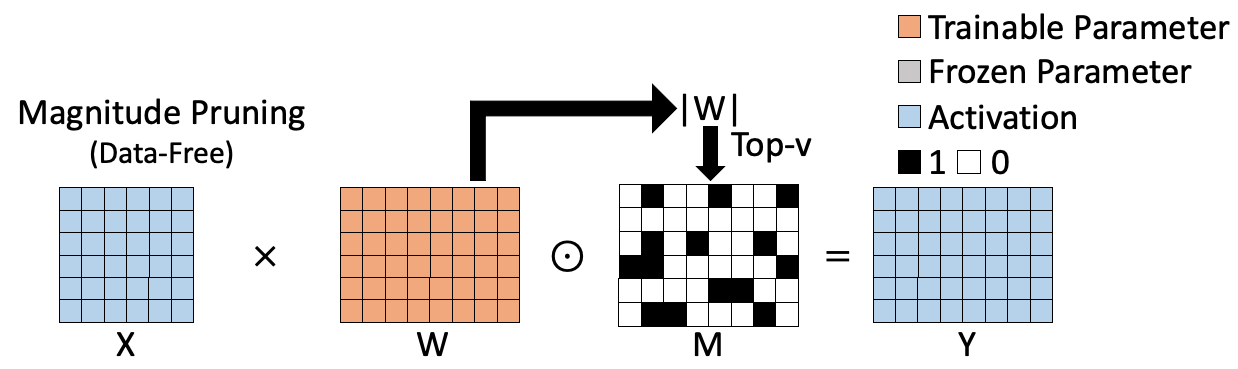
现有的稀疏训练手段可以分为两类,一类是基于权重的data-free稀疏算法;一类是基于数据的data-driven稀疏算法。基于权重的稀疏算法如下图所示,如magnitude pruning[1],通过计算权重的L1范数来评估权重的重要性,并基于此生成对应稀疏结果。基于权重的稀疏算法计算高效,无需训练数据参与,但是计算出来的重要性指标不够准确,从而影响最终稀疏模型的精度。
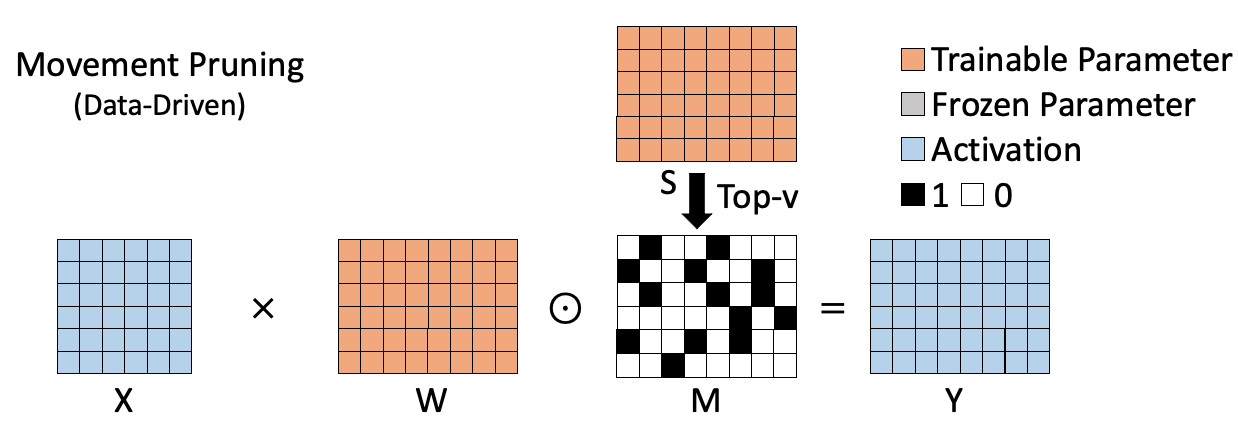
基于数据的稀疏算法如下图所示,如movement pruning[2],通过计算权重和对应梯度的乘积作为衡量权重重要性的指标。这类方法考虑到了权重在具体数据集上的作用,因此能够更加准确的评估权重的重要性。但是由于需要计算并保存各个权重的重要性,因此这类方法往往需要额外的空间来存储重要性指标(图中S)。同时相较于基于权重的稀疏方法,往往计算过程更加复杂。这些缺点随着模型的规模变大,会变得更加明显。
综上所述,之前的稀疏算法要么高效但是不够准确(基于权重的算法),要么准确但是不够高效(基于数据的算法)。因此我们期望提出一种高效的稀疏算法,能够准确且高效的对大模型进行稀疏训练。
破局
基于数据的稀疏算法的问题是它们一般会引入额外的与权重相同大小的参数来学习权重的重要性,这让我们开始思考如何减少引入的额外参数来计算权重的重要性。首先,为了能够最大化利用已有信息来计算权重的重要性,我们将权重的重要性指标设计成如下公式:
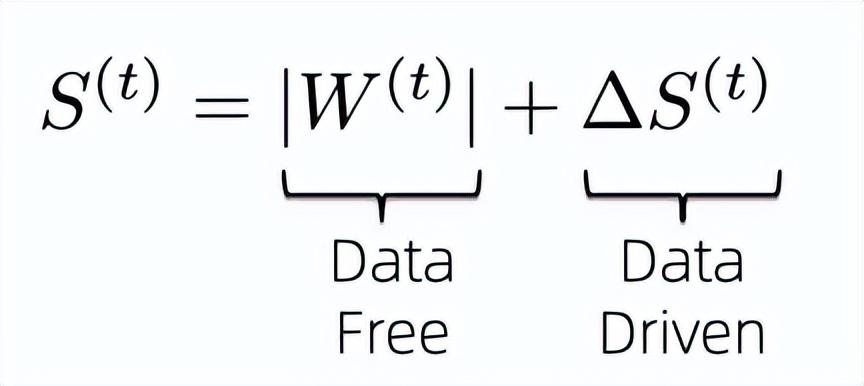
即我们结合了data-free和data-driven的指标来共同决定最终模型权重的重要性。已知前面data-free的重要性指标无需额外的参数来保存且计算高效,因此我们需要解决的就是如何压缩后面那项data-driven重要性指标所引入的额外训练参数。
基于之前的稀疏算法,data-driven重要性指标可以设计成
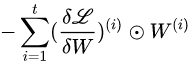
,因此我们开始分析通过该公式计算出来的重要性指标的冗余性。首先,基于之前的工作已知,权重和对应的梯度均具有明显的低秩性[3,4],因此我们可以推导出该重要性指标也具有低秩性,从而我们可以引入两个低秩小矩阵来表示原始与权重一样大的重要性指标矩阵。
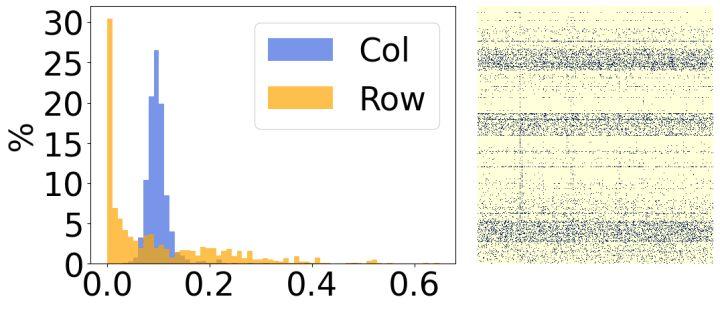
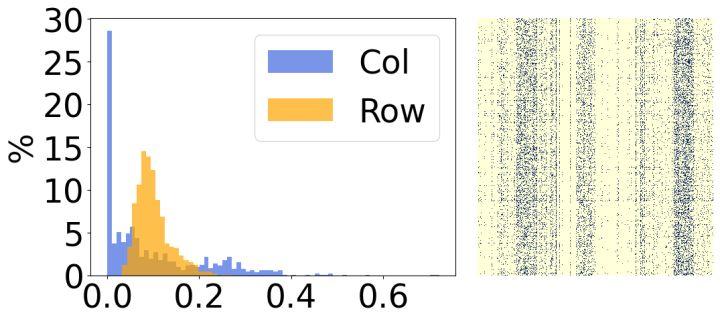
其次,我们分析了模型稀疏后的结果,发现它们具有明显的结构性特征。如上图所示,每张图的右边是最终稀疏权重的可视化结果,左边是统计每一行/列对应稀疏率的直方图。可以看出,左边图有30%的行中的大部分权重都被移除了,反之,右边图有30%的列中的大部分权重都被移除了。基于这样的现象,我们引入了两个小结构化矩阵来评估权重每一行/列的重要性。
基于上述的分析,我们发现data-driven的重要性指标存在低秩性和结构性,因此我们可以将其转换成如下表示形式:
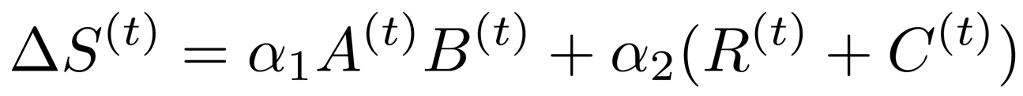
其中A和B表示低秩性,R和C表示结构性。通过这样的分析,原本和权重一样大的重要性指标矩阵就被分解成了4个小矩阵,从而大大减少了参与稀疏训练的训练参数。同时,为了进一步减少训练参数,我们基于之前的方法将权重的更新也分解成了两个小矩阵U和V,因此最后的重要性指标公式变成如下形式:
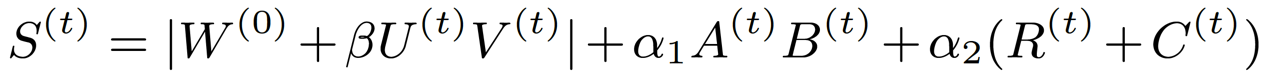
对应算法框架图如下所示:
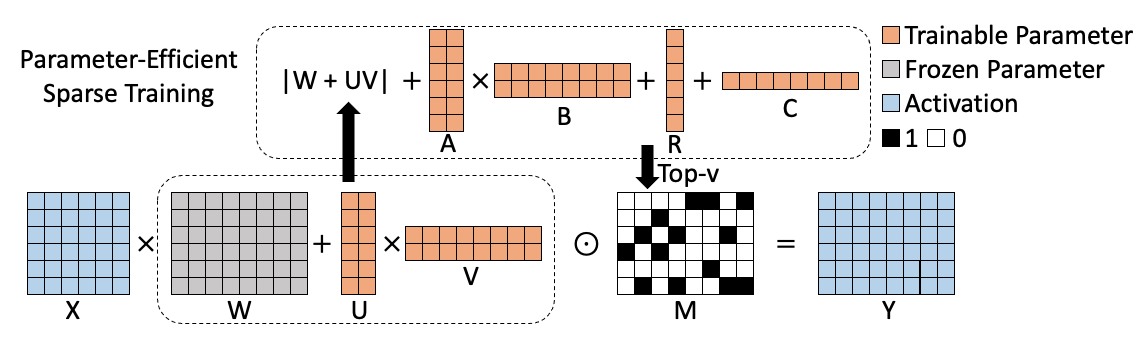
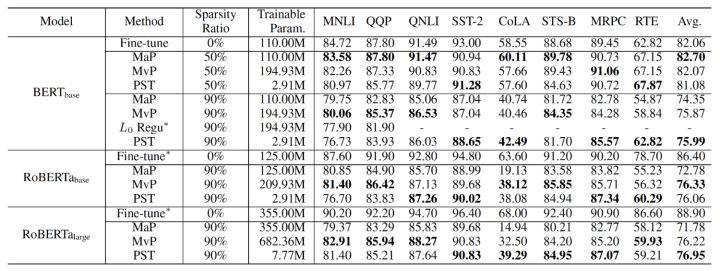
最终PST算法实验结果如下,我们在NLU(BERT、RoBERTa)和NLG(GPT-2)任务上与magnitude pruning和movement pruning进行比较,在90%的稀疏率下,PST可以在大部分数据集上达到与之前算法相当的模型精度,但是仅需1.5%的训练参数。

PST技术已经集成在阿里云机器学习PAI的模型压缩库,以及Alicemind平台大模型稀疏训练功能中。为阿里巴巴集团内部落地使用大模型带来了性能加速,在百亿大模型PLUG上,PST相比于原本的稀疏训练可以在模型精度不下降的情况下,加速2.5倍,内存占用减少10倍。目前,阿里云机器学习PAI已经被广泛应用于各行各业,提供AI开发全链路服务,实现企业自主可控的AI方案,全面提升机器学习工程效率。
论文名字:Parameter-Efficient Sparsity for Large Language Models Fine-Tuning
论文作者:Yuchao Li , Fuli Luo , Chuanqi Tan , Mengdi Wang , Songfang Huang , Shen Li , Junjie Bai
论文pdf链接:https://arxiv.org/pdf/2205.11005.pdf





























