译者 | 朱先忠
审校 | 孙淑娟
OpenAI新推出的聊天GPT棒极了
我是一名研究人员,每天都使用人工智能技术工作。可以说,在我的位置上,每个人都像盯着冰淇淋筒的狗狗一样兴奋。
原因如下:
对于那些不知道我在说什么的人来说,只需知道ChatGPT是一个人工智能聊天机器人,它可以帮助你做几乎所有的事情。它可以编码,可以写文章,也可以帮助你装饰你的家庭,甚至还可以制作食谱(如果你是意大利人,那么我不建议你这样做),还有其他很多的事情让它为你代劳。
我们可以说,这将会在未来引发伦理(而不仅仅是伦理)问题。我的母亲是一名高中教师,她很害怕她的学生会使用ChatGPT在考试中作弊。当然,这只是这项功能强大的技术“导致问题”的众多例子之一。
但问题是使用,而不是产品。如果我们严格谈论技术方面(坦率地说,也是我更感兴趣的方面,因为我是一个经“认证”的书呆子),那真是不可思议。
现在,许多开发人员已经使用并测试过这款聊天机器人来尝试开发他们的代码和AI想法。当然,这款聊天机器人的使用严格取决于你的背景。例如,如果你是一名Web开发人员,你会要求ChatGPT使用HTML构建一个网站。如果您是一名测试人员,您可以请求ChatGPT帮助您查找特定系统中的错误。
就我个人来说,我是一名研究人员。特别是,我所做的工作是用人工智能建立一些替代模型。比如说,你想对“A”进行研究,但要实现“A”任务你需要大量的资金、人力和计算时间。这种替代模型背后的想法就是,借助人工智能的数据驱动方法来取代传统的实现方案。
现在,让我们暂时彻底改变这一话题。
假设我是一名企业家,我在美国各地拥有很多酒店。如果对某家酒店进行了一定的评论,我想知道该评论对该酒店来说是好还是坏。我该怎么做?我有三个选择:
1. 我雇佣一个每天阅读数百万条评论并对其进行分类的人,那么我可能会被捕,因为这显然是对人权的侵犯。
2. 我雇佣一个每天阅读数百条评论并对其进行分类的人。几个月后,我能够用这些信息构建一个数据集。然后,我从这个数据集中训练出一个机器学习模型。
3. 我会自动生成好的和坏的评论。然后,由我自己从中构建了一个数据集,最后我从该数据集中训练出一个机器学习模型。
闲言少叙,让我们跳过第一个选择方案。
第二个选项是在ChatGPT诞生之前要做的事情。显然,你不能提前知道评论是好是坏;所以,如果你想使用此信息建立一个数据集,那么你需要雇佣人员,等到数据集准备好才能行动。
如今,我们有了ChatGPT,就可以简单地要求它来为我们生成好的和坏的评论!这将需要几分钟(而不是几个月)的时间,它将允许我们构建机器学习算法来自动分类我们的客户评论!
恭喜你,这是你的第一个代理模型。
请记住,我们不会训练ChatGPT或进行任何微调。对于这样的任务,此模型是例外的,在这种情况下不需要进行微调。现在,ChatGPT模型的训练当然不是开源的(就像模型本身一样)。我们所知道的只是OpenAI官方博客中的简短描述。他们解释说,该模型是由人工智能训练师和强化学习监督算法训练的。
仅OpenAI的ChatGPT不是开源的这一事实就引发了一些非常棘手和有趣的伦理问题。这样一个强大的模型应该是开源的——这样每个人(包括坏人)都可以使用它,还是应该不是开源的?所以,没有人可以真正信任它?
现在,让我概括一下上面的总体步骤:
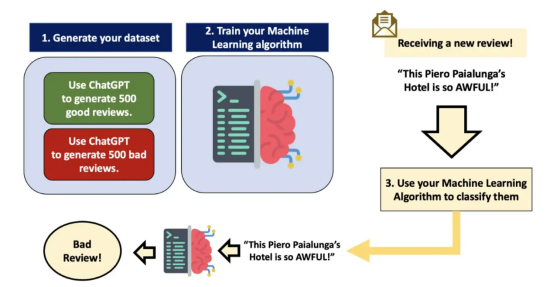
你从上图中看到的小脑壳就是代理模型。正如我们稍后将看到的,这将是一个随机的森林。但我曾经说过本文是一篇实战性的文章,所以让我们深入研究吧!(太激动了!!!)
对不起,我喜欢剧透。
一、生成数据集
第一步是使用OpenAI公司的Python API生成模拟。
为此,需要考虑的几件事有:
1.OpenAI库是天才为非天才用户创造的。因此,如果要安装它,只需执行以下操作:
2.当然,如果你想发送大量请求,你必须为优质服务提供支付。假设我们不想这样做,我们只需要等待大约30分钟就可以获得虚拟评论信息的数据集。同样,如果我们手动执行此操作,那么这与等待数月的时间(和成本)相比微不足道。此外,您还必须登录OpenAI官方网站并获得OpenAI库对应的密钥。
3.我们将自动输入这是一个好的评价还是一个差的评价,以相同的句子开头:“This hotel was terrible.”表示差评,“This hotel was great.”表示好评。总之,ChatGPT将为我们完成审查工作。当然,除了前四个单词(无论如何我们都不会在评论中包含),其余的评论都会有所不同。
让我举一个差评的例子:
接下来,我再举一个好评的例子:
现在,我们给出生成整个数据集所需的代码。

然后,我们使用Pandas库来把一切内容存储到一个数据框架DataFrame中。
为此,首先导入库并构建数据框架df:
接下来,填充数据框架结构df:
最后,导出数据框架df:
二、开始进行机器学习
现在,我们需要建立和训练一种机器学习算法。
当我们处理文本时,首先需要做的是使用矢量器(vectorizer)。矢量器负责实现将文本转换为矢量的任务。
例如:
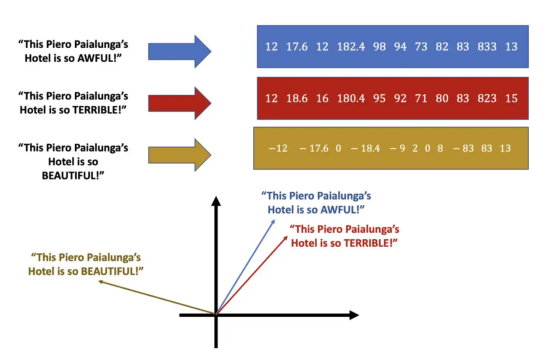
正如你所看到的,相似的文本对应着相似的向量(我知道,“相似”是一个棘手的概念,但你知道我的意思就行)。并且,不同的文本具有不相似的向量。
矢量化步骤有很多种方法。有些方式比其他方式更复杂;有些方法比其他方法更有效;有些方法需要机器学习,有些方法则不需要。
为了实现本文中这个项目的目的(因为我不是NLP机器学习工程师),我们将使用一个相当简单的叫做TfIDF矢量器的工具,该工具在SkLearn框架上可现成地使用。
让我们从导入库开始:
然后,导入我们刚刚使用ChatGPT生成的数据集,并进行一些预处理工作:
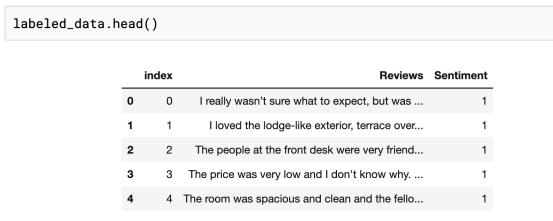
数据集头部的数据如下:
好极了!现在,让我们做一个矢量化的事情:
正如我之前介绍过的,我们将使用的机器学习模型称为随机森林。什么是随机森林?简言之,它是一个决策树的集合。那么,什么是决策树呢?
决策树是一种机器学习算法,它能够在给定具体的符合对应理论条件的情况下,优化数据集特征的所有可能分割的树搜索,直到找到一种基于该分割来区分出什么是1和什么是0的方法为止。
很抱歉,这样的解释可能还太令人困惑;但是,仅用4行文字来给出通俗解释的话,这的确是一项艰巨的任务。有一篇文章花了很多时间来解释这个问题,而且做得相当出色了。在此,我强烈推荐您看一看。
现在,让我们继续干活:
1. 定义我们的随机森林:
2. 将我们的数据集拆分为训练和测试两部分:
3. 开始训练模型:
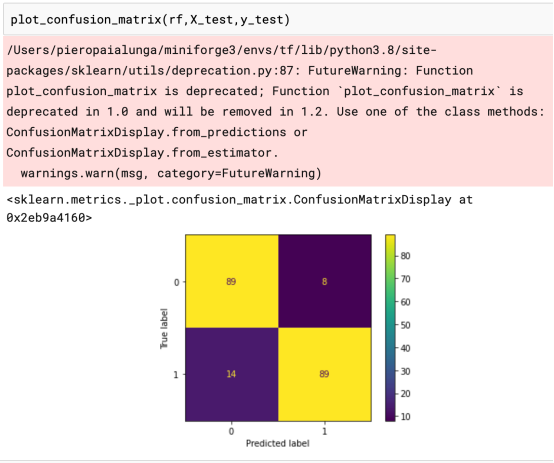
训练输出结果给人留下非常深刻的印象,特别是在没有提供超参数微调的情况下。
三、情感分析
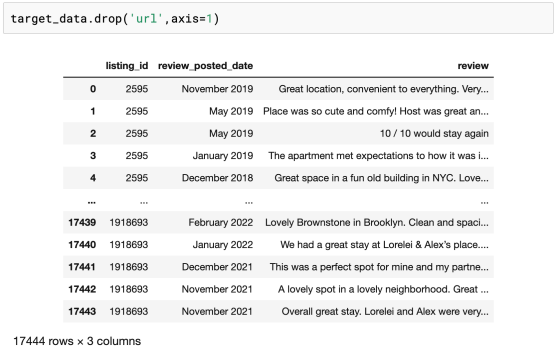
到目前为止,我们已经有了一个经过训练的模型;因此,可以在新的、未标记的数据集上使用此模型了。为此,我使用了自己在网上找到的一组纽约市酒店评论来进行测试。当然,你也可以使用自己的评论,甚至也可以编写一份评论,看看这个模型是如何工作的。
本文中我提供的这个数据集是开源的(遵循CC0协议),非常小(2MB),可以在Kaggle上下载。
现在,让我们对评论栏目(或文本)进行预处理:
然后,打印我们的预测结果:
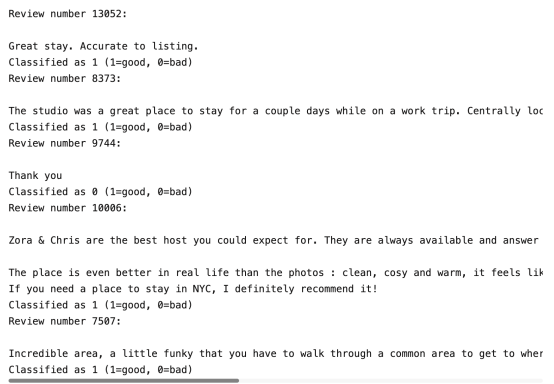
正如我们所看到的,所有上面这5条被分类为1的随机评论实际上也的确都很好!
现在,让我们再展示一个更直观的上述数据的统计计数结果示意图:
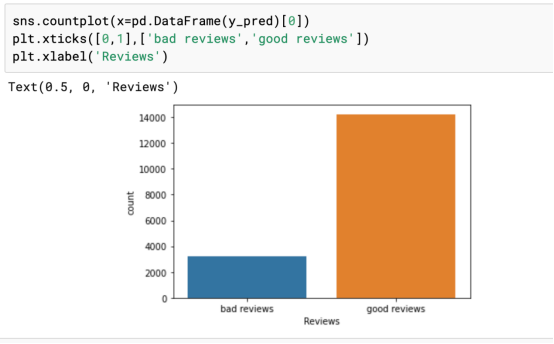
四、其他一些问题
本文中,我们具体做了哪些工作?
首先,我们肯定ChatGPT是非常棒的。
然后,我们使用ChatGPT为代理模型构建了一个数据集。更具体地说,我们使用ChatGPT来组建酒店的好评和差评数据。
接下来,我们使用我们构建的标记数据集来训练机器学习模型。本文示例中,我们所使用的模型是随机森林分类器(Random Forest Classifier)。
最后,我们在一个新的数据集上测试了我们的训练模型,并得到了令人满意的结果。
那么,上述案例中还有改进的余地吗?当然还有很多,例如:
1. 我们可以获得OpenAI高级服务,并生成超过1000条评论。
2. 我们可以通过提供不同的输入来提高我们的查询技能,也许还可以使用其他语言而不仅仅是英语。
3. 我们还可以通过进行一些超参数调整来进一步改进机器学习模型。
现在,我不由得想起了以下一些问题。
关于如何以及谁将使用OpenAI公司的ChatGPT呢?这方面自然存在很多担忧。虽然我不是一名律师(更不用说是一名伦理学人工智能专家),但我可以想象这个工具在许多方面和许多不同层面上是多么危险。
我强烈反对那些对ChatGPT的性能印象不深刻的人,因为我觉得它非常令人惊讶,而且我很高兴看到这项技术会如何发展。不过,我希望本文中介绍的这个玩具例子也能在我的读者中引起一些共鸣。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Hands-on Sentiment Analysis on Hotels Reviews Using Artificial Intelligence and Open AI’s ChatGPT, with Python,作者:Piero Paialunga