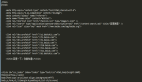
def get_data(data):
data_list =[]
comment_data_list = data["data"]["replies"]
for i in comment_data_list:
data_list.append([i['rpid'], i['like'], i['member']['uname'], i['member']['level_info']['current_level'], i['content']['message']])
return data_list
def save_data(data_type, data):
if not os.path.exists(data_type + r'_data.csv'):
with open(data_type + r"_data.csv","a+", encoding='utf-8')as f:
f.write("rpid,点赞数量,用户,等级,评论内容\n")
for i in data:
rpid = i[0]
like_count = i[1]
user = i[2].replace(',',',')
level = i[3]
content = i[4].replace(',',',')
row ='{},{},{},{},{}'.format(rpid,like_count,user,level,content)
f.write(row)
f.write('\n')
else:
with open(data_type + r"_data.csv","a+", encoding='utf-8')as f:
for i in data:
rpid = i[0]
like_count = i[1]
user = i[2].replace(',',',')
level = i[3]
content = i[4].replace(',',',')
row ='{},{},{},{},{}'.format(rpid,like_count,user,level,content)
f.write(row)
f.write('\n')
for i in range(1000):
url ="https://api.bilibili.com/x/v2/reply/main?jsnotallow=jsonp&next={}&type=1&oid=972516426&mode=3&plat=1&_=1632192192097".format(str(i))
print(url)
d = requests.get(url)
data = d.json()
if not data['data']['replies']:
break
m_data = get_data(data)
save_data("main", m_data)
for j in m_data:
reply_url ="https://api.bilibili.com/x/v2/reply/reply?jsnotallow=jsonp&pn=1&type=1&oid=972516426&ps=10&root={}&_=1632192668665".format(str(j[0]))
print(reply_url)
r = requests.get(reply_url)
r_data = r.json()
if not r_data['data']['replies']:
break
reply_data = get_data(r_data)
save_data("reply", reply_data)time.sleep(5)time.sleep(5)
pie_data = df_new.等级.value_counts().sort_index(ascending=False)
pie_data.tolist()
c2 =(
Pie().add("",[list(z) for z in zip([str(i) for i in range(6,1,-1)], pie_data.tolist())],
radius=["40%","75%"],).set_global_opts(
title_opts=opts.TitleOpts(title="等级分布"),
legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"),).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}")).render_notebook())