大部分数据团队在进行实时业务建设的初期,都会出现烟囱式开发、一个任务搞定全部数据加工环节等问题,缺乏实时数据的管理和实时数仓分层建设的规范意识。随着实时场景的进一步丰富,出现了实时数据复用、业务方自助进行实时取数等需求,因此要求数据团队要像管理离线数据一样对实时数据进行有规范的实时数仓管理。
本文将从一个实际业务场景和一个模拟数仓构建的案例来说明如何利用 EasyData 实时开发平台来建设实时数仓。
1、实际业务场景
1.1 背景介绍
业务方是某移动 APP 的运营团队,需求是要实时监控各类运营活动的 ABtest 的实验效果,以便业务方根据实验效果随时调整运营投放策略、投放目标用户和投放比例。
1.2 业务数据分层
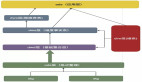
通常业务方的实时数据流转链路包含实时数据采集、实时数据加工处理、实时数据落库查询等步骤,在此用户的ABtest 场景中,数据加工链路如下图所示:

第一步:用户的日志数据经过实时采集写入 ODS 层的 Kafka 中。ODS 层数据为原始未加工的业务数据,保存在 Kafka,7 天后自动清理。
第二步:ODS 层数据经过 Flink 任务处理写入 DWD 层 Kafka 中。DWD 层数据为经过清洗的数据。
第三步:DWD 层数据经过 Flink 任务处理写入 DWS 层 KUDU 数据库中落库。DWS 层数据为经过聚合、过滤等加工步骤,可以向业务方提供的数据。
第四步:业务方在需要时通过 Impala 查询 KUDU 数据库中的数据生成报表。
通过以上实时数据加工链路,业务方可实现实时报表展示,时效性较离线加工链路大大提高,可以满足业务方要求数据实时更新的需求。
1.3 业务痛点
在这个业务场景中 ODS 层、DWD 层的 Kafka 数据在其他加工链路中也需要被复用,但在其他链路加工过程中,同样的 Topic 需要不断重复在不同任务中进行 Flink Table 的定义,每次定义用户均需要使用 DDL 语句定义字段、表配置等,重复工作很多,同时在任务中进行表定义时,数据管理者无法感知哪些数据已被使用,也无法判断是否有可以优化的数据流转链路。
1.4 产品方案
EasyData 实时开发模块中为用户提供了实时流表登记和管理的功能,辅助用户进行实时数仓的建设。实时流表是 EasyData 实时开发模块中的特有概念。流表的内容为 Kafka,Rocketmq 等没有明确 schema 的消息中间件的元数据。在平台通过登记流表并在任务中直接引用流表的方式即可将这部分元数据进行复用。
同时在流表管理模块中,用户可以查看流表的定义。此外,按照业务方的数仓规范中的表命名规范登记流表后,可以根据流表的表名判断流表的分层归属。在接下来的规划中,数仓流表模块将支持数据血缘查看、数据预览、使用数据模型建表等功能,基于流表元数据进行更完整更易用的实时数仓管理。
在下方模拟案例介绍中,将为大家讲解如何定义和使用流表,以及如何通过登记流表进行数仓建设。
2、案例场景介绍
业务目标:统计某 APP 实时访问的 DAU,需要统计的值包括总 DAU,各设备类型 DAU(iPhone、华为、OPPO、其他)。
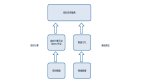
业务数据链路:

第一步:通过 CDC 任务采集用户访问数据数据实时变更至 Kafka(对应案例步骤第一步)
第二步:将 ODS 层 Kafka 数据通过 Flink 任务进行清洗和聚合,写入 MySQL 落库(对应案例步骤第二、三步)
第三步:将 MySQL 数据通过 BI 报表展示(对应案例最终结果)
3、案例操作步骤
3.1 准备阶段:准备模拟数据
3.1.1 数据源准备
需准备用于实践的 MySQL 数据源和 Kafka 数据源。
3.1.2 数据表准备
(1)准备 DS 层源端表:DAU_DS
此表用于记录用户访问数据。表结构与样例数据如下:

(2)准备 DWD 层结果表:DAU_FINAL
此表用于统计最终结果。表结构如下:

注意:由于模拟案例最终希望直接展示不同用户的计算结果,故需要向同一张已提前制作好对应 BI 报表的表内写数据,每人更新一行数据。正常业务场景下根据业务需求决定结果表结构和数量。
3.2 第一步:创建 CDC 任务
3.2.1 创建 CDC 任务
任务名称可自行命名,任务保存位置可选择根目录或创建以自己名字命名的目录。任务环境和任务类别为任务标签信息,选择测试和默认标签即可,不影响任务实际运行。

3.2.2 编辑 CDC 任务
源端配置:
表:DAU_DS
传输起始位点:
若只想消费新增数据,请选择最新数据,最终结果报表中将仅有体验当日的数据。
若想先消费历史存量数据,之后再消费最新数据,请选择全量初始化,最终结果报表中将有历史数据。

目标端配置:
类型:kafka
数据源:poc_kafka
Topic:自行命名,可通过目标 Topic 生成规则生成,也可在目标 Topic 中手动修改,建议修改目标 Topic 名称为自己的名称,方便下一步新建流表时使用。此处选择不存在的 Topic,在任务运行后对应 Topic 将被自动创建。
序列化方式:canal-json

3.2.3 保存并一键发布任务
点击页面上方的 保存 和 一键发布 按钮,填写任意提交描述,将任务发布至实时运维列表。

成功发布后可点击 运维 按钮前往任务运维页面。
3.2.4 启动任务
在运维页面找到对应任务后点击 启动 按钮启动任务。

任务成功启动,任务状态变为运行中时,创建 CDC 任务步骤操作完成。
3.3 第二步:创建 ODS 层流表
点击实时开发页面左侧目录第四项流表,打开流表管理页面。点击页面右上角创建表按钮,开始创建流表。

表名:自行命名
topic:填写上一步 CDC 任务的目标 Topic 名称
序列化方式:canal-json

填写完以上信息后可开始进行字段自动解析。
字段信息获取方式选择自动解析,之后点击获取数据,获取到数据样例后点击解析,即可解析出流表的字段信息。
Tip:若 CDC 任务正常运行但此处未获取到样例数据,可能是因为数据暂未写入,稍等一分钟后重新尝试。

字段信息确认无误后即可保存流表。
保存流表成功,即为此步骤操作完成。
3.4 第三步:创建 SQL 任务
3.4.1 创建 SQL 任务
引擎请选择 FLINK-1.14。其他类似创建 CDC 任务步骤。
3.4.2 编辑 SQL 代码
代码逻辑为:将同一天的用户方式数据按日期聚合,并统计当天的DAU总数以及各设备类型的DAU。
在代码中引用流表时,直接使用 [库].[表] 二元组的写法即可使用对应的流表。
注意以下内容在拷贝代码后需自行更改:
Kafka消费者组id配置,需要更改配置中的流表名称为自己的流表名称
Kafka流表名称,需要更改为上一步中自己登记的流表名称
插入结果表的submitter字段值,需要更改为自己的名字
具体要修改的内容请见代码中的标注。
3.4.3 发布 SQL 任务并启动任务
保存并发布 SQL 任务,并启动任务。操作方法与 CDC 任务的发布和启动相同。
SQL 任务成功启动且状态变为运行中,则此步骤操作完成。
3.4.4 创建 BI 报表并展示数据结果
在有数 BI 中创建对应报表,查看最终的统计结果即可。刷新报表数据即可看到报表数据实时更新后的结果。预期效果如下:
(1)折线图:

(2)报表