背景
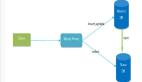
在分布式系统架构中,业务的流量都是端到端的。每个请求都会经过很多层处理,比如从入口网关再到 Web Server 再到服务之间的调用,再到服务访问缓存或 DB 等存储。
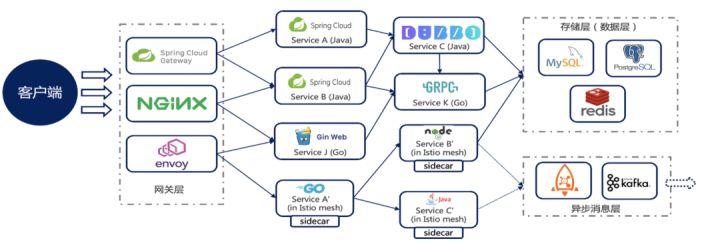
对于我们的系统来说,数据库是非常重要的一块。因此无论是在稳定性的治理上,还是在开发提效等场景下,数据库相关的治理能力都是我们系统所需具备的能力。下面总结了微服务访问数据库层时,在数据库治理中的常见的一些场景与能力。
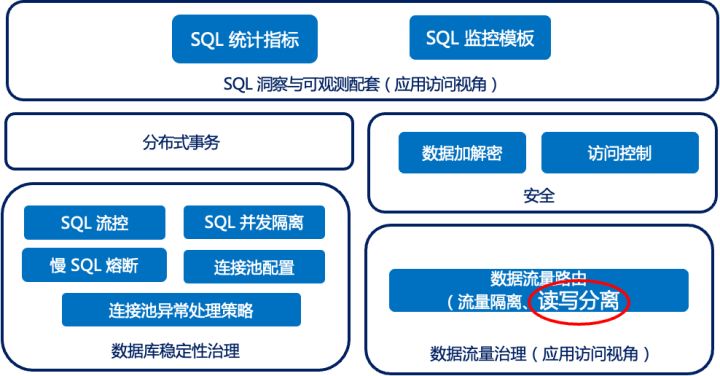
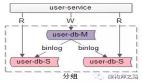
OpenSergo 领域中关于数据库治理的概览
本文将介绍 MSE 服务治理最近推出数据库治理利器:无侵入实现数据库访问的读写分离能力。
什么是读写分离?
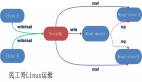
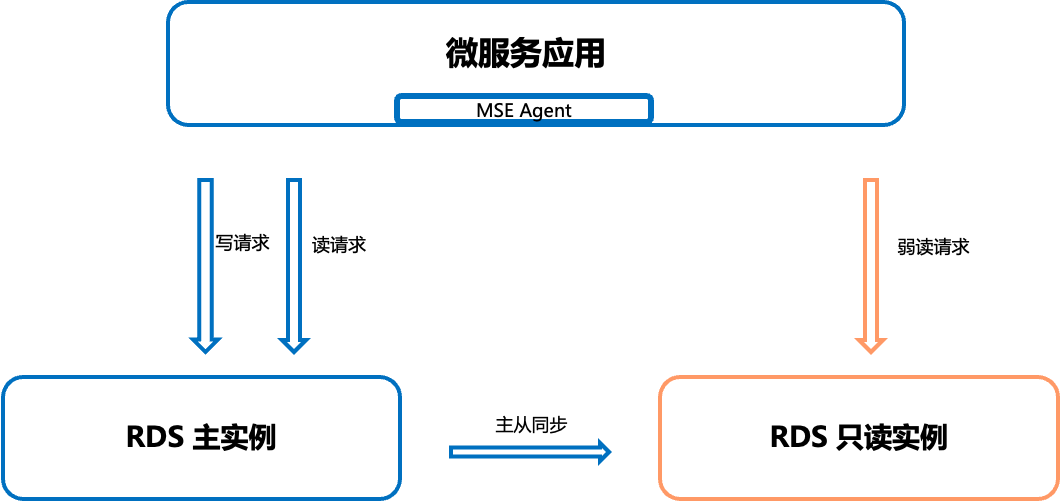
读写分离也就是将数据库拆分为主库和从库,即主库负责处理事务性的增删改操作,从库负责处理查询操作的数据库架构。
为什么要读写分离?
稳定性
一个大客户的请求过来,查询数据库返回上万条几百 M 的数据,数据库的 CPU 直接打满。不知道大家是否遇到过类似的问题。
性能
在业务处理过程中,如果对数据库的读操作远多于写操作,同时业务上对于数据查询结果的实时性要求不高(例如可以容忍秒级的延迟),那么在做系统性能优化时就可以考虑引入读写分离的方案,只读库可以承担主库的压力,有效提升微服务应用的性能。
规模增长
随着业务增长,到了一定规模之后再扩容,但很多都卡在扩容这一步,极大的限制了应对市场变化的速度,其中数据库的扩容是最难的,目前常见的数据库扩容方式有以下几种方式:
- 垂直升级
- 分库分表
- 读写分离
垂直升级需要中断服务且高可用方面不及其它几种方式,分库分表在分区键的选择上会是个难点,SQL 使用上会有诸多限制,同时对业务的改造也是非常大的工作量。相对来说读写分离是对业务的侵入最低也最容易实现扩容方案。根据经验大多数应用的读写比都在 5:1 以上,有些场景甚至大量的高于 10:1,在对数据库有少量写请求,但有大量读请求的应用场景下,单个实例可能无法承受读取压力,甚至对业务产生影响。
综上所述数据库读写分离方案可以满足阿里云上大多数公司的稳定性治理、性能提升以及数据库扩容的需求。
读写分离常见方案
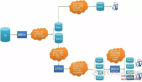
目前业界流行的读写分离方案,通常都是基于上述主从模式的数据库架构。读写分离的实现方案多数是通过引入 odp、mycat 等数据访问代理产品,通过其读写分离功能来帮助实现读写分离。引入数据访问代理的好处是源程序不需要做任何改动就可以实现读写分离,坏处是由于多了一层中间件做中转代理,性能上会有所下降,数据访问代理也容易成为性能瓶颈。
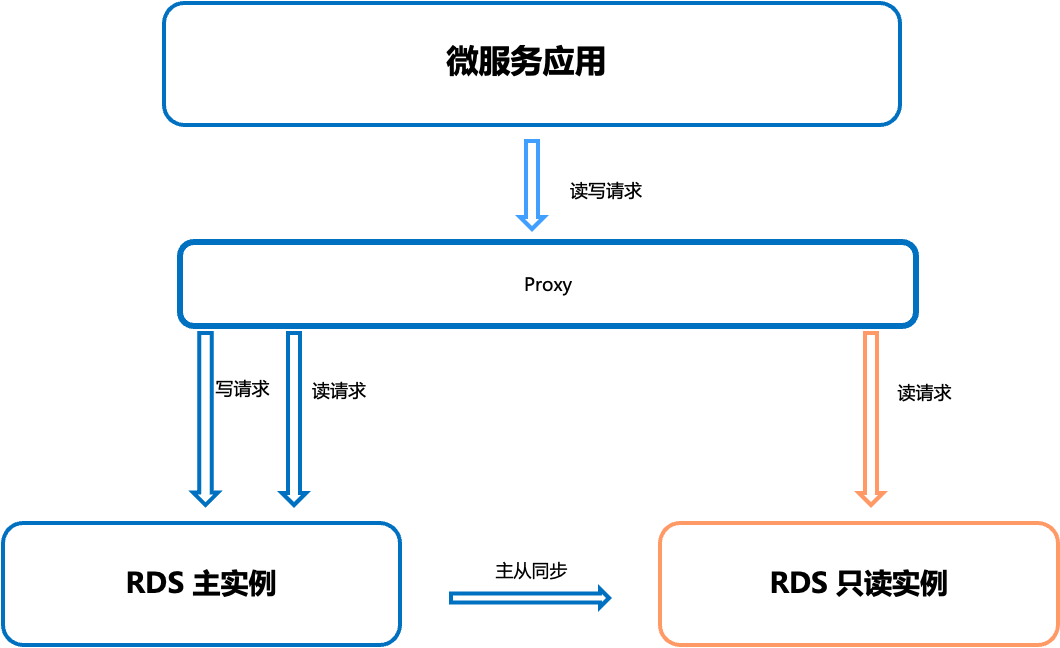
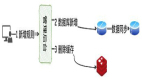
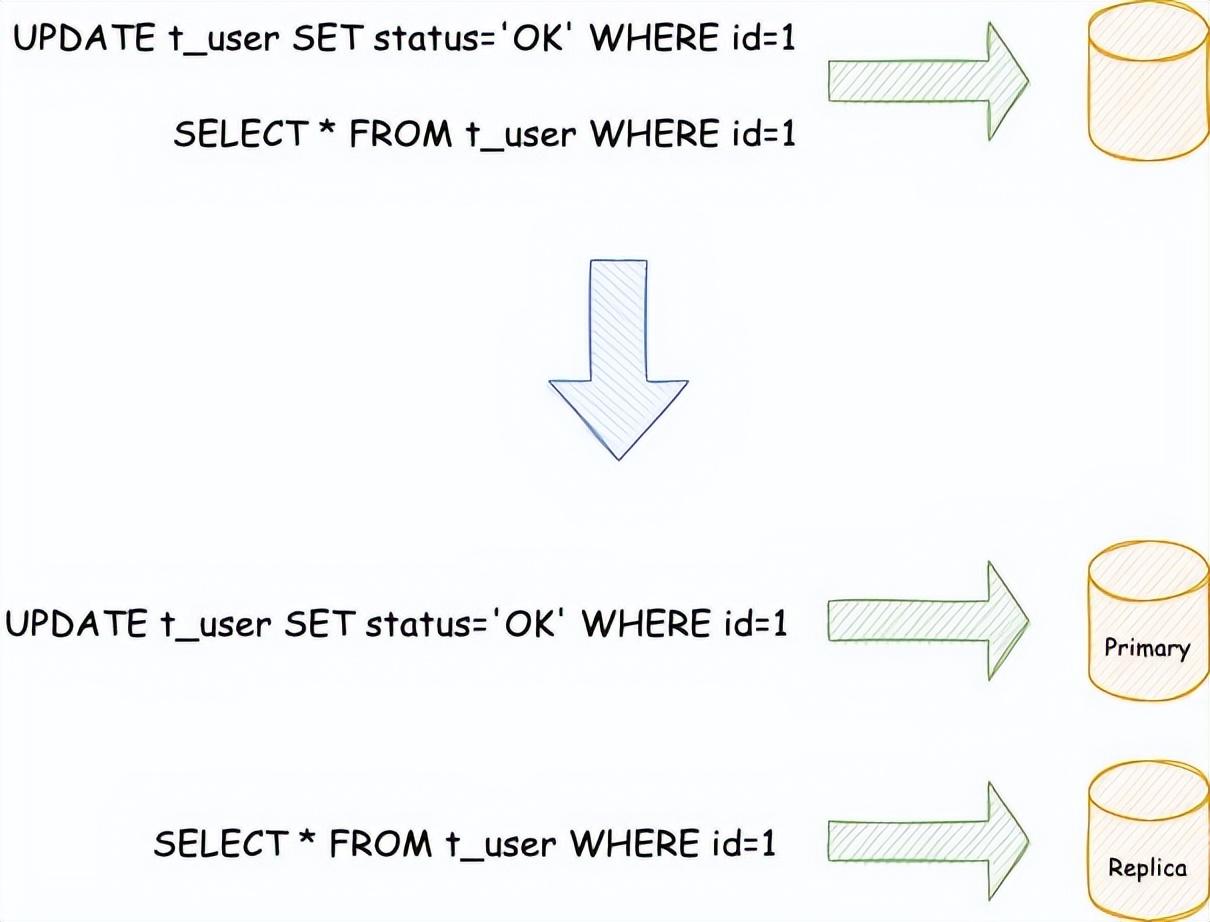
ShardingSphere 读写分离方案[1](摘自 shardingsphere 官网)
ShardingSphere[2] 的读写分离主要依赖内核的相关功能。包括解析引擎和路由引擎。解析引擎将用户的 SQL 转化为 ShardingSphere 可以识别的 Statement 信息,路由引擎根据 SQL 的读写类型以及事务的状态来做 SQL 的路由。如下图所示,ShardingSphere 识别到读操作和写操作,分别会路由至不同的数据库实例。
MSE 数据库读写分离能力
MSE 提供了一种动态数据流量治理的方案,您可以在不需要修改任何业务代码的情况下,实现数据库的读写分离能力。下面介绍 MSE 基于 Mysql 数据存储通过的读写分离能力。
前提条件
- 应用接入 MSE
- 部署 Demo 应用
在阿里云容器服务中部署 A、B、C 三个应用,并且将应用均接入 MSE 服务治理[3],用于增加具备数据库治理能力的 Agent。
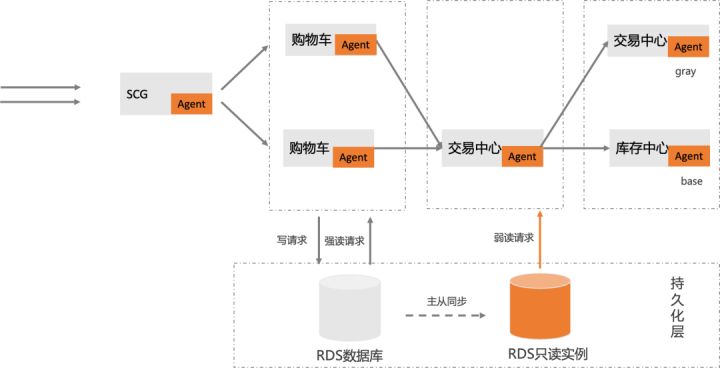
- 创建 RDS 只读实例[4]
我们需要创建 RDS 只读实例,利用只读实例满足大量的数据库读取需求,增加应用的吞吐量。
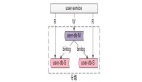
配置读写分离规则
- 我们需要配置以下环境变量来额外开启/配置数据库的读写分离能力

- 我们可以通过控制台配置弱读请求的规则或者指定某些接口为弱读请求
上述 OpenSergo 标准的规则表示 /getLocation 接口的请求为弱读请求。
我们针对一些大数据量查询、对延时不太敏感的业务请求可以配置为 weak 类型
SQL 洞察
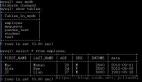
如上只需轻松的两步我们就实现了数据库的读写分离能力。基于数据库读写分离能力,配合 MSE 数据库治理的 SQL 洞察我们可以快速定位 RT 过大的查询请求,帮助我们进一步分析 SQL 对我们数据库稳定性的影响。
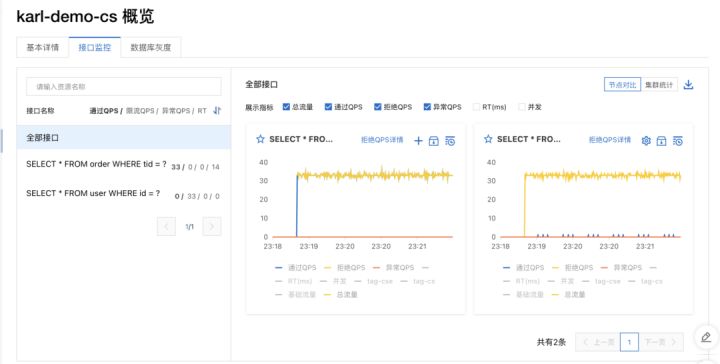
我可以观察应用和资源 API 维度的 SQL 请求实时数据(细化至秒级),同时 MSE 还提供了 SQL 的 topN 列表,我们可以一眼看出 RT 高,查询返回值数据量大的 SQL 语句。

总结
本文详细描述了 MSE 即将推出的数据库治理能力矩阵中关于动态读写分离能力的介绍。通过 MSE 提供的 SQL 洞察能力,结合我们对业务的理解,我们可以快速定位划分接口请求为弱请求。将对主库性能以及稳定性影响大的读操作,分流至 RDS 只读库,可以有效降低主库的读写压力,进一步提升微服务应用的稳定性。
我们从应用的视角出发,抽象了我们在访问以及使用数据库时的一些常见场景以及对应的治理能力,整理了我们在稳定性治理、性能优化、提效等方面的实战经验。对于每一个后端应用来说,数据库无疑是重中之重,我们希望通过我们的数据库治理能力,可以帮助到大家更好地使用数据库服务。
最后提一下服务治理的标准 OpenSergo:
Q:OpenSergo[5] 是什么
A:OpenSergo 是一套开放、通用的、面向分布式服务架构、覆盖全链路异构化生态的服务治理标准,基于业界服务治理场景与实践形成服务治理通用标准。OpenSergo 最大特点就是以统一一套配置/DSL/协议定义服务治理规则,面向多语言异构化架构,做到全链路生态覆盖。无论微服务的语言是 Java, Go, Node.js 或其它语言,无论是标准微服务或 Mesh 接入,从网关到微服务,从数据库到缓存,从服务注册发现到配置,开发者都可以通过同一套 OpenSergo CRD 标准配置针对每一层进行统一的治理管控,而无需关注各框架、语言的差异点,降低异构化、全链路服务治理管控的复杂度