分布式消息队列是分布式系统架构中的关键组件,主要用于解决应用耦合、异步消息、流量削峰的问题。随着业务逻辑的拆分和业务系统的微服务改造,不仅要求消息队列在性能和可靠性上有充分保障,也对其在一些特殊业务场景的功能支持上提出了需求。本文就分布式消息队列顺序消息的基础逻辑及使用过程中的问题进行了简单总结。
分布式消息队列的消息顺序问题
在分布式架构中,消息队列为实现其高性能、高可用以及弹性伸缩等特点,其存储数据的逻辑结构大都选择了多分区的模式,即将一个Topic划分为多个Partition。多分区的设计大幅提高了架构的并发性和可用性,但消息队列本身仅能保证每个Partition内部消息的有序性,整个Topic内、多个Partition之间消息的顺序性无法得到保障。

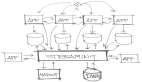
图1 普通消息的收发样例
在图1中,a1-a4四条按顺序生产的消息在消费的时候已经被彻底打乱,在一般的业务场景中该消费结果是可接受的,但在部分有特殊需求的场景中则不能满足业务需求。如在给用户发送银行卡余额变更的场景中,必须保证同一账户的余额变更通知是顺序的,对于业务端顺序生成的余额变更消息a1,a2,a3,a4,必须保证用户接收消息的顺序也是a1,a2,a3,a4,如图2所示。

图2 顺序消息的业务需求
在此类有顺序需求的场景里,就需要业务系统端和消息队列服务端“共同努力”,保障业务逻辑的实现。
顺序消息的基础实现逻辑
顺序消息是指生产者将需要保证顺序的一批消息严格按照先进先出(FIFO)的原则发送到消息队列中,在消费的时候消费者对这一批消息按相同的先后顺序进行消费。根据业务场景,一般将顺序消息划分为局部顺序和全局顺序两种,但全局顺序是局部顺序的一种特殊实现,因此本文后续的讨论中均围绕局部顺序展开。
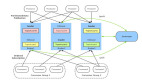
局部顺序:对于指定的一个Topic,只需要保证具有相同标识的一批消息严格按照先进先出的原则进行发布和消费即可,不同标识的消息之间不做顺序要求,上文中提到的在给用户发送余额变更短信的场景中,只需要保证相同账户ID的通知消息具有顺序性即可,不同账户之间的短信通知顺序无需保证。在实现上,大部分消息队列都是通过在投放时对Message设置ShardingKey,将具有相同ShardingKey的Message投放到相同的Partition的方式保障消息顺序存储,如图3所示。

图3 通过ShardingKey实现局部顺序
全局顺序:对于指定的一个Topic,所有消息按照严格的先入先出(FIFO)的顺序来发布和消费。全局顺序消息实际上是一种特殊的局部顺序消息,或者是将该Topic所有的消息打上相同的ShardingKey实现,或者是在消息队列服务端只为该Topic提供1个Partition,因此其并发度和性能都将严重受损。
分区变动带来的顺序错乱
在正常场景下,通过ShardingKey的方式可以保证消息的有序性,但分布式队列在使用过程中经常会遇到分区故障或分区扩缩容的情况,此时很难保障消息的严格顺序。
如在Rocket MQ的主从架构中,主Broker的故障必然会带来分区数量的变化,此时通过ShardingKey计算出的分区ID也将变化,从而导致消息顺序的错乱。

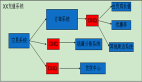
图4 Partition故障导致消息顺序错乱
如图4所示,正常场景下a1,a2投递到Partition2,此时Partition3发生故障,消息队列服务端的Partition数量发生变化,同一ShardingKey的Hash算法结果会出现变动,因此a3、a4两条消息被投递到Partition1,此时两个队列之间的消费顺序无法得到保障。
在Kafka的架构设计中,尽管Partition副本会在Leader故障后重新选主,故障前后分区的数量未发生变化,但要注意分区选主的过程中整个Partition处于不可用的状态,此时如果有顺序消息生成也将导致顺序错乱。
实践场景中必须注意的两个问题
概括来说,顺序消息的实现只需要Producer给Message打上ShardingKey即可,但在实际使用过程中仍然需要在使用时结合不同消息队列产品的特性做针对性的优化,下面针对Kafka和RocketMQ两款产品顺序消息的使用过程中需要注意的问题做简单介绍。
1. 同步发送保障消息投递的有序
要保证消息在发送阶段的有序性,就要在同一个Producer线程中,使用同步发送的方法对消息进行发送,同时要注意对于发送失败的情况下要在Producer端做好重试控制,避免因投递失败带来的顺序错误。
在RocketMQ中,Producer提供的send()方法默认为同步发送,应用可以根据返回的SendResult判断当前消息是否投递成功。但在Kafka中,所有的发送本质上都是异步发送,用户编码的Producer线程调用的send()方法仅是将消息暂存到客户端本地的RecordAccumulator中,实际将消息从本地发送到Broker的是后台的Kafka Sender线程。

图5 Kafka发送消息的实际逻辑
因此在Kafka中,要实现同步发送的效果要首先获取send()方法返回的Future对象,而后调用Future对象的get()方法进行阻塞,等待Kafka Broker的响应。
2. 多worker线程消费的问题
在分布式消息队列的消费模型中,为了保障同一Partition内消息的顺序消费,一个Partition在同一个消费组中只能被一个consumer实例消费,因此该消费组的消费能力与Partition的数量密切相关,为解决这一问题很多应用在消费时将consumer仅作为拉取消息的实例,在内部实现多worker线程提高并发度,此时尽管consumer实例拉取到的消息是有序的,但消息在不同的worker线程中处理,也会出现顺序错乱的问题。

图6 多worker线程消费导致消息顺序错乱
要保障消息的消费顺序,必须保障同一ShardingKey的消息在同一线程中处理。客户端在消费时采用了多worker的逻辑,可以为每一个worker线程引入一个阻塞队列,consumer分发消息时将相同ShardingKey的消息放入同一个阻塞队列消费,worker线程不断轮询从阻塞队列中获取消息处理即可。
总结
在系统的微服务改造过程中,顺序消息的使用是不可避免的,用户要对消息队列的实现逻辑有清晰的认识,并对其在故障场景下可能造成的影响有提前的预估。本文对顺序消息的基础实现逻辑、服务端故障导致的消息顺序错乱以及应用设计在producer端和consumer端需要注意的问题进行了总结性说明,应当充分认识到顺序消息相关业务场景的实现不能仅仅靠消息队列本身去保障,需要业务端一起共同努力去实现。