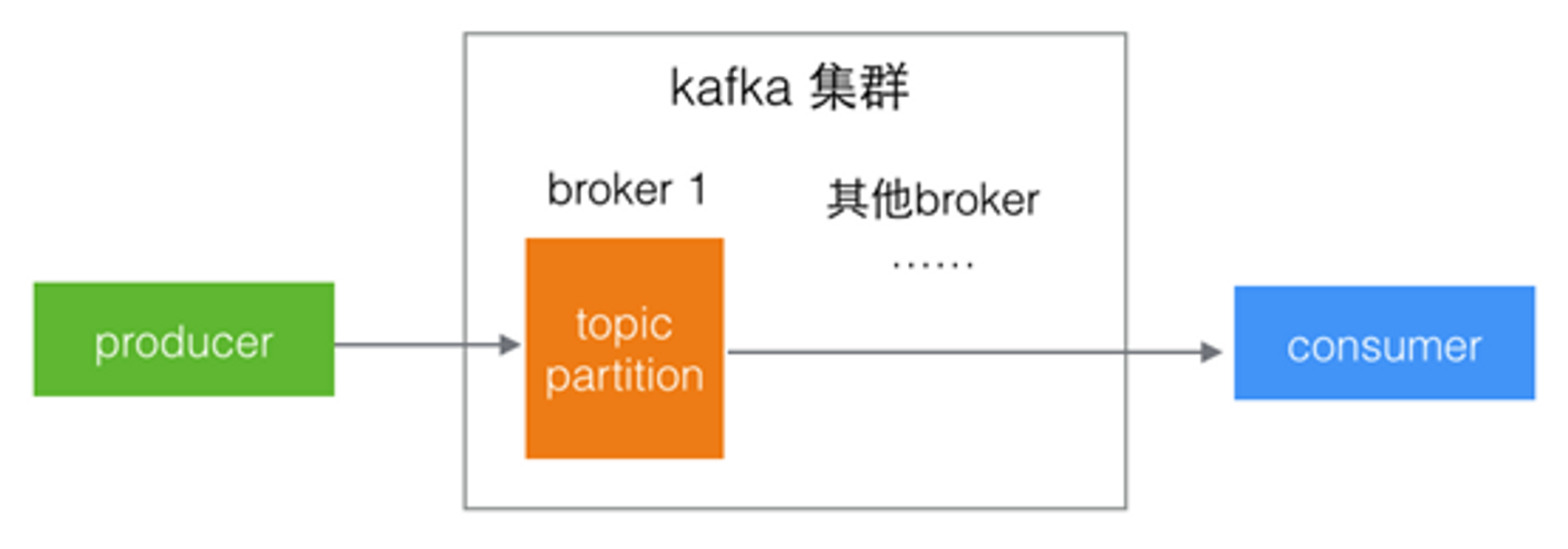
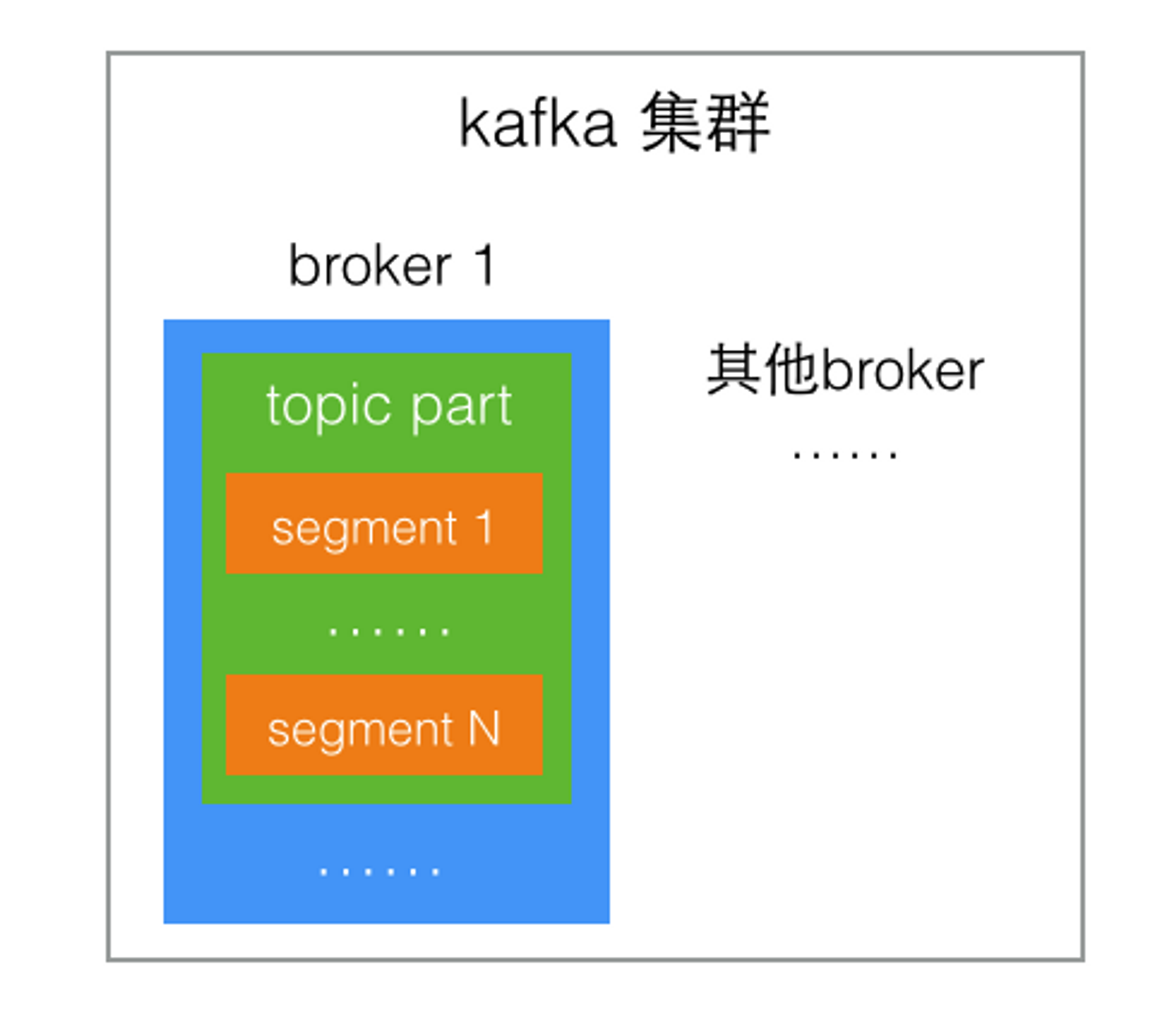
Kafka是一个分布式的消息队列系统,消息存储在集群服务器的硬盘
Kafka中可以创建多个消息队列,称为topic,消息的生产者向topic中发布消息,消息的消费者从topic中获取消息
消息是海量的,为了消息的读写性能,topic被分为多个部分,称为partition,kafka把每个topic的每个partition均匀的分布在集群中的不同服务器上
所以从整体来看,Kafka的逻辑关系就是:生产者向topic中的某个partition发送消息,消费者从partition获取消息
实际的存储结构中,partition并不是存放消息的物理文件,而是一个目录,命名规则是topic名称加上partition序号,其中包含了这个partition的N个分段存储文件segment。
分段存储也是因为partition内容非常多,分成小文件更便于消息的写入和检索。
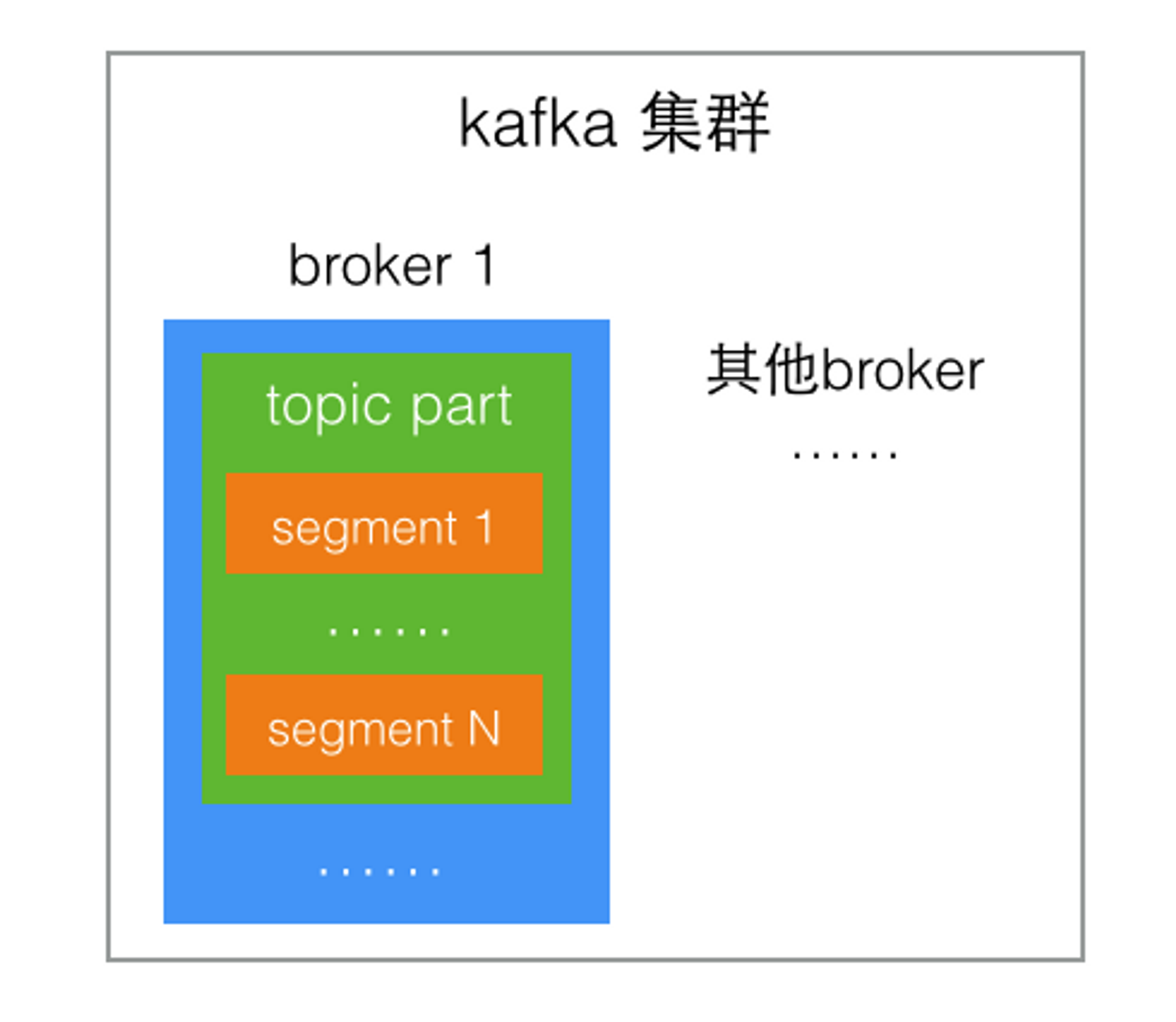
segment也不是一个文件,是由两个物理文件构成:
.index索引文件、.log消息内容文件
这两个文件是成对出现,名称一样,只是后缀不同
实际的存储结构就是这样的
消息是按照顺序产生的,所以每个消息都有一个序号,称为offset,表示partiion的第多少个message,从0开始
每个segment存储了一段offset区间内的消息
segment文件以offset区间的起始值命名,长度固定20位,不足的位用0填充
例如存储了第0-20条的消息,segment文件就是:
00000000000000000000.index
00000000000000000000.log
index文件结构很简单,每一行都是一个key,value对
key 是消息的序号offset
value 是消息的物理位置偏移量
如
1,0
3,299
6,497
...
说明的就是第几个消息的物理位置是哪儿
log文件中保存了消息的实际内容,和相关信息
如消息的offset、消息的大小、消息校验码、消息数据等
消息检索过程示例
例如读取offset=368的消息
(1)找到第368条消息在哪个segment
从partition目录中取得所有segment文件的名称,就相当于得到了各个序号区间
例如有3个segment
00000000000000000000.index
00000000000000000000.log
00000000000000000300.index
00000000000000000300.log
00000000000000000600.index
00000000000000000600.log
根据二分查找,可以快速定位
第368条消息是在00000000000000000300.log文件中
(2)从index文件中找到其物理偏移量
读取00000000000000000300.index
以368为key,得到value,如299,就是消息的物理位置偏移量
(3)到log文件中读取消息内容
读取 00000000000000000300.log
从偏移量299开始读取消息内容
完成了消息的检索过程