今天遇到D-SMART产品本身的一个性能问题,我准备用D-SMART给一套Oracle数据库做个巡检,发现居然任务因为一条SQL超时而异常了。通过日志发现是一条分析某个指标的SQL。


执行时间居然高达229秒,巡检报告中设定了SQL超时时间是180秒,而如果巡检的时间区间超过一个半月,则这条sql的执行时间介于170秒到250秒之间,就经常会超时了。

D-SMART的后台数据库是PG,这张表是一张TIMESCALEDB的表。表上也创建了适当的索引。通过explain分析看,执行计划也是正常的,通过这个分区索引做范围扫描,然后做聚合(Timescaledb会按照时间戳自动做数据分区)。通过D-SMART的PG数据库等待事件分析工具可以发现,数据文件读是排在前面的。
刚开始的时候我也没有仔细分析,通过EXPAIN发现sort buffer使用量接近20M,明显超出了WORK_MEM参数。于是我调整了WORK_MEM参数,重新执行了这条SQL。发现原来需要200多秒的SQL不到50毫秒就完成了。不过我还是留了个心眼,因为D-SMART分析工具里可以看出文件读占了比较靠前的位置。于是我重启了一下PG数据库,再次执行这条SQL。比刚才稍微慢了一点,大概80多毫秒。不过比起200多秒来,也提升不少。于是我和同事说,这条SQL的性能问题解决了,加大WORK_MEM参数就可以了。
老储还是在PG上有丰富的实战经验,他提醒我,验证PG的问题,重启数据库是没用的,文件缓冲会影响SQL的性能。搞了二十多年Oracle,总是用Oracle的思维来思考现在的数据库问题,这回又犯了类似的错误。于是我重新做了测试,关闭数据库,然后使用echo 3 > drop_caches命令清除OS缓冲,然后再进行测试。
令人遗憾的是,SQL的性能又回到了从前,看样子加大WORK_MEM并没有有效的改善SQL性能。回过头来想想也是,哪怕因为排序缓冲超了一点,做了硬盘排序,也不可能有20秒的性能影响。
公司的这套PG 14.4的环境是装在一台虚拟机上的,磁盘是SATA盘,性能确实不行。对于PG这样使用DOUBLE CACHE的数据库,文件缓冲确实可以对SQL性能有明显的帮助。而这种特性也会让PG数据库的同一条SQL语句在OS的不同状态下执行性能有较大的波动。下面我们通过一个例子来验证一下。
在做这个测试之前,我们先要安装一个插件-pgfincore,对这个插件有兴趣的朋友可以去https://github.com/klando/pgfincore 下载。Pgfincore是针对PG数据库的OS缓冲分析与操作的插件,一般被用户用来分析OS缓冲中的数据库表或者索引,也被部分用户用来预热数据,让部分热数据总是被缓冲在FILE CACHE中,从而让OS CACHE能够更好的发挥作用。
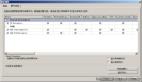
Pgfincore的功能十分强大,首先可以用来查看某张表或者索引在OS缓冲中的情况。比如:

我检查的一个timescaledb的索引分区,总共有15.7万个page,其中13.9万个page在OS缓冲里了。

第二个功能是把某张表或者索引的数据预热到OS CACHE里。这里要注意的是如果表是分区表,一定要直接预热分区,而不要使用表的名字,pgfincore不支持自动识别表分区。Timescaledb的一个表分区,原本这张表并没有完全被缓冲到内存里,通过调用pgfadvise_willneed函数,把这张表的所有数据都调用到OS缓冲中了。
第三个功能是备份和恢复某个场景下的OS CACHE。这对于一些十分关键的系统的预热十分有价值。比如说某个系统的某些热数据对于系统性能十分关键。当系统重启(特别是服务器重启)后的某个时间段里,数据没有预热完成之前,系统性能是会有较大影响的。如果我们在停机重启前,先备份OS CACHE中某些热表的缓冲情况,系统重启后立即预热这部分数据,则可以确保系统重启后立即恢复重启前的性能。

首先在系统重启前将pgfincore的数据保存在pgfincore_snapshot表中,系统重启后使用pgfadvise_loader重新装载缓冲数据。
有了上面的基础知识,我们下面就来做一个实验。

首先对OS缓冲做一个完全的清理。然后启动PG数据库。执行刚才有问题的那条SQL语句。

我只截取了部分执行计划,因为针对每个分区,都是相同的扫描方式,先对索引做扫描,然后再回表。这条SQL执行了34秒多。
接下来我们先按照上面的流程再次关闭数据库,清理缓冲,然后把所有的索引分区都先预热一下,看看效果如何。

可以看出,现在所有索引的OS缓冲项都是0,说明没有任何索引数据被缓存了。接下来预热,然后再次执行这条SQL。

大家可以看到,预热后,这些索引分区都在OS缓冲里了,同样再把所有的表的数据也预热一下。再来执行刚才的SQL语句:

大家可以看到,执行时间从34秒变成了31毫秒。实际上对于使用double cache的数据库来说,此类问题是十分常见的。此类数据库产品的同一条SQL在不同时间里执行的性能可能差异上百倍,但是其执行计划是完全相同的。这是因为DOUBLE CACHE的原因。Pgfincore插件为解决此类问题提供了一个很好的解决方案。利用snapshot/restore的方式,如果做一些适当的精细化管理,可以起到十分好的稳定关键业务SQL执行效率的作用。希望我的这个性能故障的案例能够给大家一些启示。