













导读
深度学习已在面向自然语言处理等领域的实际业务场景中广泛落地,对它的推理性能优化成为了部署环节中重要的一环。推理性能的提升:一方面,可以充分发挥部署硬件的能力,降低用户响应时间,同时节省成本;另一方面,可以在保持响应时间不变的前提下,使用结构更为复杂的深度学习模型,进而提升业务精度指标。
本文针对地址标准化服务中的深度学习模型开展了推理性能优化工作。通过高性能算子、量化、编译优化等优化手段,在精度指标不降低的前提下,AI模型的模型端到端推理速度最高可获得了4.11倍的提升。
1. 模型推理性能优化方法论
模型推理性能优化是AI服务部署时的重要环节之一。一方面,它可以提升模型推理的效率,充分释放硬件的性能。另一方面,它可以在保持推理延迟不变的前提下,使得业务采用复杂度更高的模型,进而提升精度指标。然而,在实际场景中推理性能优化会遇到一些困难。
1.1 自然语言处理场景优化难点
典型的自然语言处理(Natural Language Processing, NLP)任务中,循环神经网络(Recurrent Neural Network, RNN)以及BERT[7](Bidirectional Encoder Representations from Transformers.)是两类使用率较高的模型结构。为了便于实现弹性扩缩容机制和在线服务部署的高性价比,自然语言处理任务通常部署于例如Intel® Xeon®处理器这样的x86 CPU平台。然而,随着业务场景的复杂化,服务的推理计算性能要求越来越高。以上述RNN和BERT模型为例,其在CPU平台上部署的性能挑战如下:
- RNN
循环神经网络是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网络。实际使用中常见的RNN有LSTM,GRU以及衍生的一些变种。在计算过程中,如下图所示,RNN结构中每一次的后级输出都依赖于相应的输入和前级输出。因此,RNN可以完成序列类型的任务,近些年在NLP甚至是计算机视觉领域被广泛使用。RNN相较于与BERT而言,计算量更少,模型参数共享,但其计算时序依赖性会导致无法对序列进行并行计算。
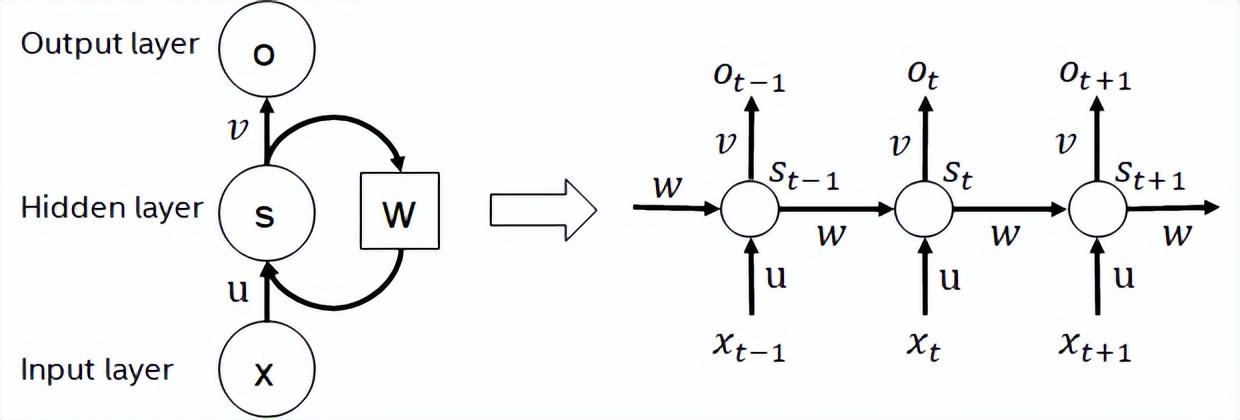
RNN结构示意图
- BERT
BERT[7]证明了能够以较深的网络结构在大型数据集上完成无监督预训练(Unsupervised Pre-training),进而供给特定任务进行微调(finetune)的模型。它不仅提升了这些特定任务的精度性能,还简化了训练的流程。BERT的模型结构简单又易于扩展,通过简单地加深、加宽网络,即可获得相较于RNN结构更好的精度。而另一方面,精度提升是以更大的计算开销为代价的,BERT模型中存在着大量的矩阵乘操作,这对于CPU而言是一种巨大的挑战。
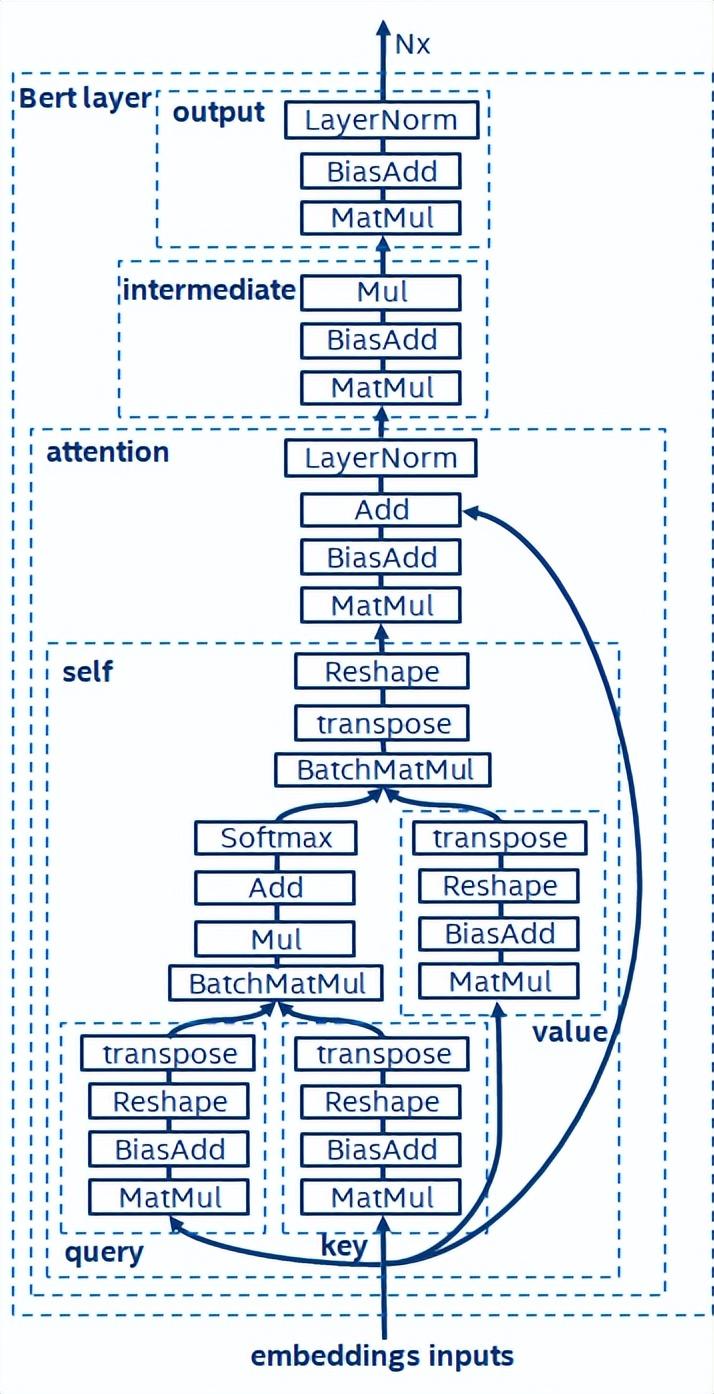
BERT模型结构示意图
1.2 模型推理优化策略
基于上述推理性能挑战的分析,我们认为从软件栈层面进行模型推理优化,主要有如下策略:
- 模型压缩:包括量化、稀疏、剪枝等
- 特定场景的高性能算子
- AI编译器优化
量化
模型量化是指将浮点激活值或权重(通常以32比特浮点数表示)近似为低比特的整数(16比特或8比特),进而在低比特的表示下完成计算的过程。通常而言,模型量化可以压缩模型参数,进而降低模型存储开销;并且通过降低访存和有效利用低比特计算指令(如Intel® Deep Learning Boost Vector Neural Network Instructions,VNNI),取得推理速度的提升。
给定浮点值,我们可以通过如下公式将其映射为低比特值:
其中和是通过量化算法所得。基于此,以Gemm操作为例,假设存在浮点计算流程:
我们可以在低比特域完成相应的计算流程:
高性能算子
在深度学习框架中,为了保持通用性,同时兼顾各种流程(如训练),算子的推理开销存在着冗余。而当模型结构确定时,算子的推理流程仅是原始全量流程个一个子集。因此,当模型结构确定的前提下,我们可以实现高性能推理算子,对原始模型中的通用算子进行替换,进而达到提升推理速度的目的。
在CPU上实现高性能算子的关键在于减少内存访问和使用更高效的指令集。在原始算子的计算流程中,一方面存在着大量的中间变量,而这些变量会对内存进行大量的读写操作,进而拖慢推理的速度。针对这种情况,我们可以修改其计算逻辑,以降低中间变量的开销;另一方面,算子内部的一些计算步骤我们可以直接调用向量化指令集,对其进行加速,如Intel® Xeon®处理器上的高效的AVX512指令集。
AI编译器优化
随着深度学习领域的发展,模型的结构、部署的硬件呈现出多样化演进的趋势。将模型部署至各硬件平台时,我们通常会调用各硬件厂商推出的runtime。而在实际业务场景中,这可能会遇到一些挑战,如:
- 模型结构、算子类型的迭代的速度会高于厂家的runtime,使得一些模型无法快速基于厂商的runtime完成部署。此时需要依赖于厂商进行更新,或者利用plugin等机制实现缺失的算子。
- 业务可能包含多个模型,这些模型可能由多个深度学习框架训得,此外模型可能需要部署至多个硬件平台。此时需要将这些格式不同的模型转化至各个硬件平台所需的格式,同时要考虑各推理框架实现的不同导致的模型精度性能变化等问题,尤其是像量化这类对于数值差异敏感度较高的方法。
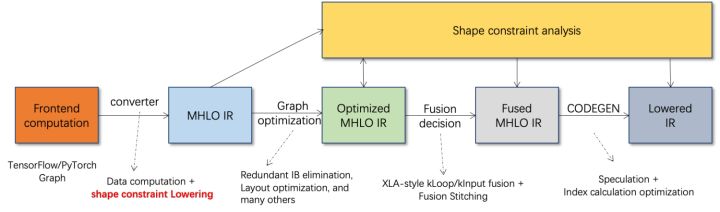
AI编译器就是为了解决上述问题而提出的,它抽象出了多个层次来解决上述的一些问题。首先,它接受各个前端框架的模型计算图作为输入,并通过各类Converter转化生成统一的中间表示。随后,诸如算子融合、循环展开等图优化pass会作用至中间表示,以提升推理性能。最后,AI编译器会基于优化后的计算图进行面向特定硬件平台的codegen,生成可执行的代码,这过程中会引入诸如stitch、shape constraint等优化策略。AI编译器有很好鲁棒性、适应性、易用性,并且能够收获显著优化收益。
本文中,阿里云机器学习平台PAI团队联合英特尔数据中心软件团队、英特尔人工智能和分析团队、达摩院NLP地址标准化团队,针对地址标准化服务的推理性能挑战,合作实现了高性能的推理优化方案。
2. 地址标准化介绍
公安政务、电商物流、能源(水电燃)、运营商、新零售、金融、医疗等行业在业务开展的过程中往往涉及大量地址数据,而这些数据往往没有形成标准结构规范,存在地址缺失、一地多名等问题。随着数字化的升级,城市地址不标准的问题愈加凸显。
地址应用现存问题
地址标准化[2](Address Purification)是阿里巴巴达摩院NLP团队依托阿里云海量的地址语料库,以及超强的NLP算法实力所沉淀出的高性能及高准确率的标准地址算法服务。地址标准化产品从规范地址数据、建立统一标准地址库的角度出发,提供高性能地址算法。
地址标准化优势
该地址算法服务能自动地标准化处理地址数据,可有效地解决一地多名,地址识别,地址真伪辨别等地址数据不规范、人工治理耗时耗力、地址库重复建设问题,为企业,政府机关以及开发者提供地址数据清洗,地址标准化能力,使地址数据更好的为业务提供支持。地址标准化产品具有如下的几个特点:
- 准确率高:拥有海量地址语料库以及超强的NLP算法技术,并持续优化迭代,地址算法准确率高
- 超强性能:积累了丰富的项目建设经验,能够稳定承载海量数据
- 服务全面:提供20多种地址服务,满足不同业务场景需求
- 部署灵活:支持公共云、混合云、私有化部署。
本次优化的模块属于地址标准化中的搜索模块。地址搜索是指用户输入地址文本相关信息,基于地址库和搜索引擎,对用户输入的地址文本进行搜索和联想,并返回相关兴趣点(Point of Interest,POI)信息。地址搜索功能不仅能够提升用户数据处理体验,同时也是多个地址下游服务的基础,如经纬度查询、门址标准化、地址归一等,因此在整套地址服务体系中起到了关键作用。
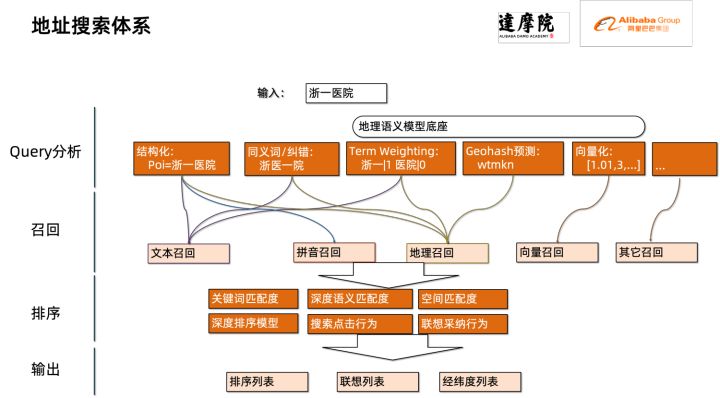
地址服务搜索体系示意图
具体而言,本次优化的模型是基于多任务地理预训练语言模型底座产出的多任务向量召回模型和精排模型。
多任务地理预训练语言模型底座在掩码语言模型 (Masked Language Model, MLM) 任务的基础上结合了相关兴趣点分类与地址元素识别(省、市、区、POI 等),并通过元学习(Meta Learning)的方式,自适应地调整多个任务的采样概率,在语言模型中融入通用的地址知识。
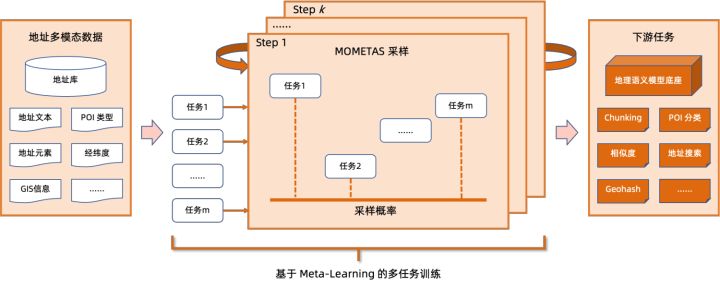
多任务地址预训练模型底座示意图
多任务向量召回模型基于上述底座训练所得,包含双塔相似度、Geohash (地址编码) 预测、分词和 Term Weighting (词权重) 四个任务。
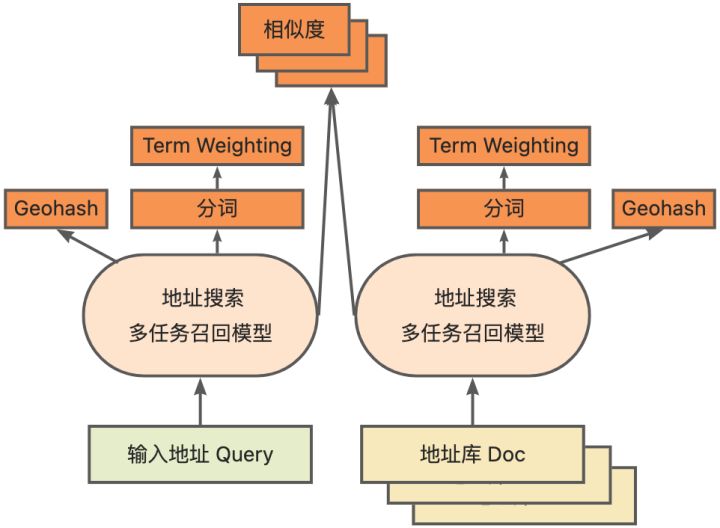
多任务向量召回模型示意图
作为计算地址相似度匹配的核心模块,精排模型则是在上述底座的基础上,引入了海量点击数据和标注数据训练训练所得[3],并通过模型蒸馏技术,提升了模型的效率[4]。最终用应用于召回模型召回的地址库文档重新排序。基于上述流程训练得到的4层单模型能够在CCKS2021中文NLP地址相关性任务[5]上获得较12层基线模型更好的效果(详见性能展示部分)。
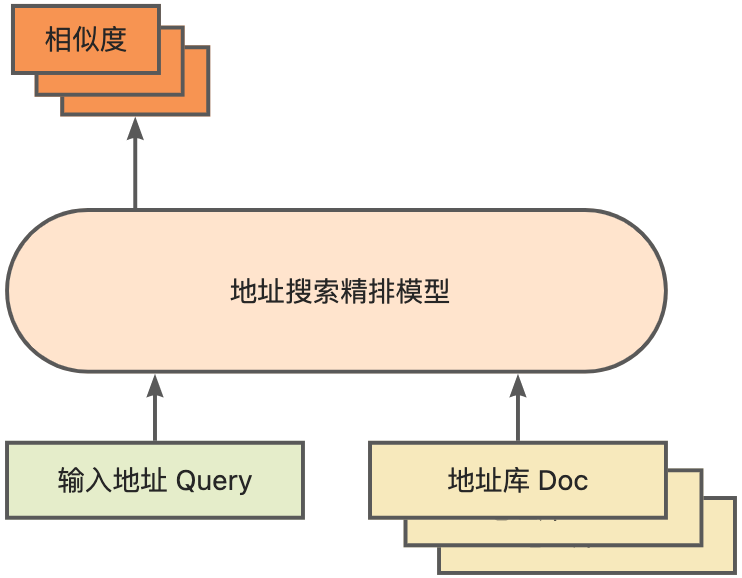
精排模型示意图
3. 模型推理优化解决方案
阿里云机器学习平台PAI团队推出的Blade产品支持以上提及的所有优化方案,提供了统一的用户接口,并拥有多个软件后端,如高性能算子、Intel Custom Backend、BladeDISC等等。

Blade模型推理优化架构图
3.1 Blade
Blade是阿里云机器学习PAI团队(Platform of Artificial Intelligence)推出的通用推理优化工具,可以通过模型系统联合优化,使模型达到最优推理性能。它有机融合了计算图优化、Intel® oneDNN等vendor优化库、BladeDISC编译优化、Blade高性能算子库、Costom Backend、Blade混合精度等多种优化手段。同时,简洁的使用方式降低了模型优化门槛、提升了用户体验和生产效率。
PAI-Blade支持多种输入格式,包括Tensorflow pb、PyTorch torchscript等。对于待优化的模型,PAI-Blade会对其进行分析,再应用多种可能的优化手段,并从各种优化结果中选取出加速效果最明显的为最终的优化结果。
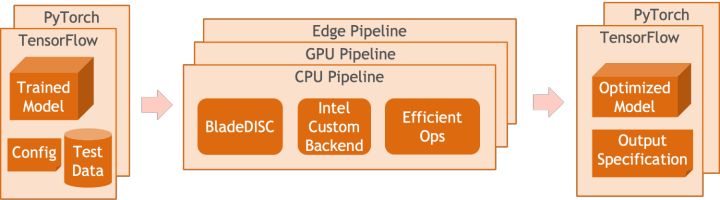
Blade优化示意图
为了在保证部署成功率的前提下获得最大的优化效果,PAI-Blade采取了“圈图”的方式进行优化,即:
- 将待优化子计算图中,能够被推理后端/高性能算子支持的部分转化至相应的优化子图;
- 无法被优化的子图回退(fallback)至相应的原生框架(TF/Torch)执行。
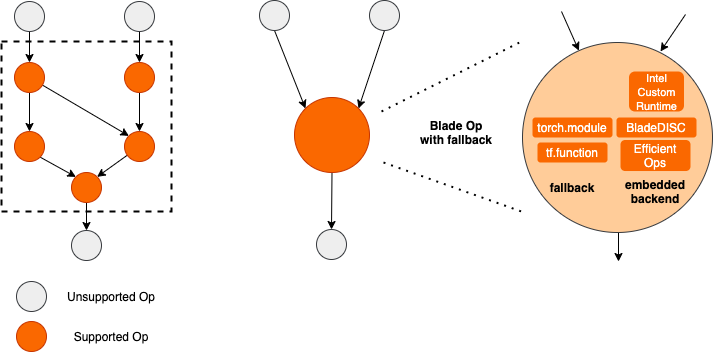
Blade圈图示意图
Blade Compression是Blade推出的面向模型压缩的工具包,旨在协助开发人员进行高效的模型压缩优化工作。它包含了多种模型压缩功能,包括量化、剪枝、稀疏化等。压缩后的模型可以便捷地通过Blade实现进一步优化,以获得模型系统联合的极致优化。
量化方面,Blade Compression:
- 提供了简洁的使用接口,通过调用几个简单api,即可完成量化改图、校准(calibration)、量化训练(Quantization-aware Training,QAT)、导出量化模型等步骤。
- 提供了多种后端的支持,通过config文件的配置,即可完成面向不同设备、不同后端的量化过程。
- 集成了PAI-Blade团队在实际生产业务中自研的各种算法,以获得更高的量化精度。
同时,我们提供了丰富的原子能力api,便于对特定情况进行定制化开发。
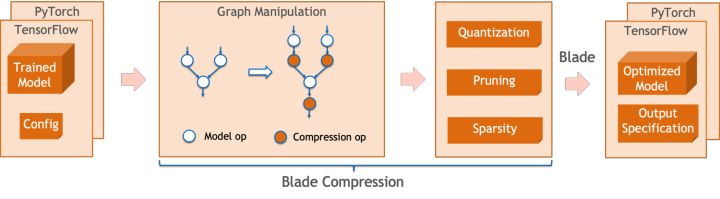
Blade Compression示意图
BladeDISC是阿里云机器学习平台PAI团队推出的面向机器学习场景的动态shape深度学习编译器,是Blade的后端之一。它支持主流的前端框架(TensorFlow、PyTorch)与后端硬件(CPU、GPU),同时也支持推理以及训练的优化。
BladeDISC架构图
3.2 基于Intel® Xeon®的高性能算子
神经网络模型中的子网络通常具有长期的通用性和普遍性,如 PyTorch 中的 Linear Layer 和Recurrent Layers 等,是模型建构的基础模块,负责着特定的功能,通过这些模块的不同组合得到形形色色的模型,并且这些模块也是AI编译器重点优化的目标。据此,为了得到最佳性能的基础模块,从而实现性能最佳的模型,Intel针对X86架构对这些基础模块进行了多层次优化,包括使能高效的AVX512指令、算子内部计算调度、算子融合、缓存优化,并行优化等等。
在地址标准化服务中,经常会出现Recurrent Neural Network (RNN) 模型,并且RNN模型中最影响性能的模块是LSTM或GRU等模块,本章节以LSTM为例,呈现在不定长且多batch的输入时,如何实现对LSTM的极致性能优化。
通常,为了满足不同用户的需求和请求,追求高性能和低成本的云上服务会将不同的用户请求进行Batch,以实现计算资源的最大化利用。如下图所示,总共有3条已经被embedding的句子,并且内容和输入的长度是不相同的。

原始输入数据
为了使得LSTM计算的更高效,需要对Batched input采用PyTorch的pack_padded_sequence()函数进行padding和sort,得到下图所示,一个paddding的数据tensor,一个描述数据tensor的batch size的tensor,一个描述数据tensor的原始序号tensor。

原始输入数据
到目前为止,已经准备好了LSTM的输入,对于LSTM的计算过程如下图所示,对输入的tensor进行分段批量计算,及跳过零值计算。
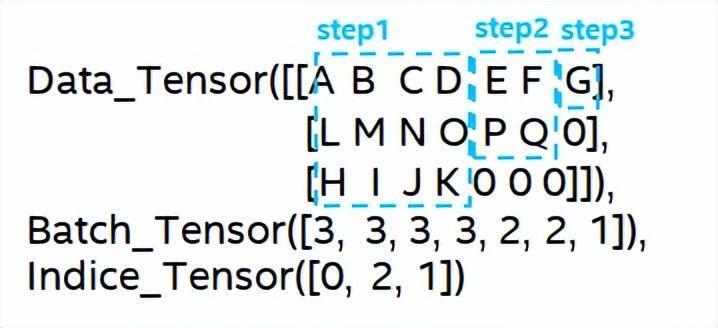
LSTM针对输入的计算步骤
更深入的LSTM的计算优化如下图17所示,公式中的矩阵乘部分进行了公式间计算融合,如下图所示,原先4次矩阵乘转换成1次矩阵乘,并且采用AVX512指令进行数值计算,以及多线程并行优化,从而实现高效的LSTM算子。其中,数值计算指的是矩阵乘和后序的elementwise的元素操作,针对矩阵乘部分,本方案采用的是oneDNN库进行计算,库中具有高效的AVX512 GEMM实现,针对elementwise的元素操作,本方案对其采用AVX512指令集进行算子融合,提升了数据在缓存中的命中率。
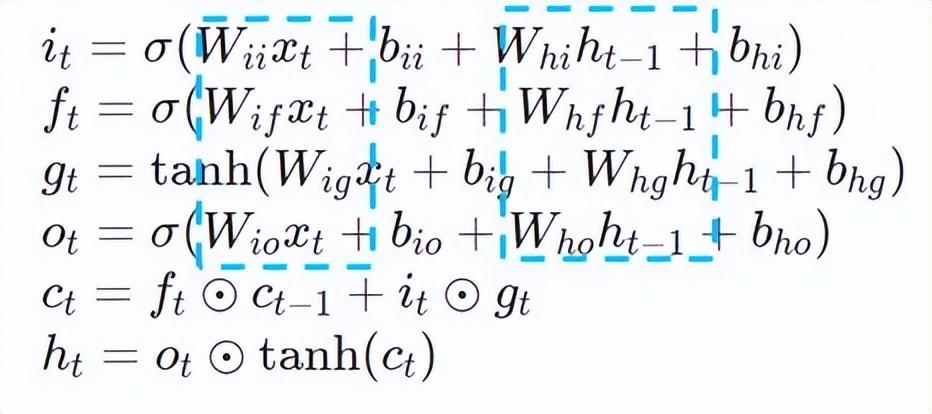
LSTM计算融合[8]
3.3 推理后端 Custom Backend
Intel custom backend[9]作为Blade的软件后端,强有力地加速着模型量化和稀疏的推理性能,主要包含三个层面的优化。首先,采用Primitive Cache的策略对内存进行优化,其次,进行图融合优化,最后,在算子层级,实现了包含稀疏与量化算子在内的高效算子库。
Intel Custom Backend架构图
低精度量化
稀疏与量化等高速算子, 得益于Intel® DL Boost加速指令集,如VNNI指令集。
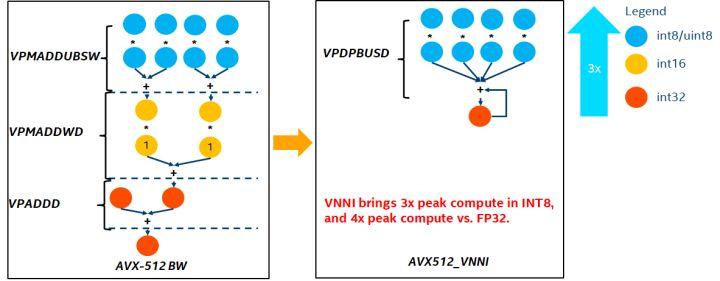
VNNI 指令介绍
上图为VNNI 指令, 8bits可以使用AVX512 BW三个指令来加速, VPMADDUBSW 先对2对由8bits组成的数组做乘法与加法, 得到16bits数据, VPMADDWD将相邻数据加总起来,得到32bits数据, 最后VPADDD加上一个常数, 此三函数可组成一个AVX512_VNNI,此指令可用来加速推理中的矩阵相乘。
图融合
除此之外,Custom Backend中也提供了图融合,例如矩阵相乘后不输出中间态临时Tensor,而是直接运行后面指令,即将后项的post op与前级算子进行融合,如此减少数据搬运以减少运行时间,下图为一个范例,红框内的算子融合后可消除额外的数据搬移,成为一个新的算子。
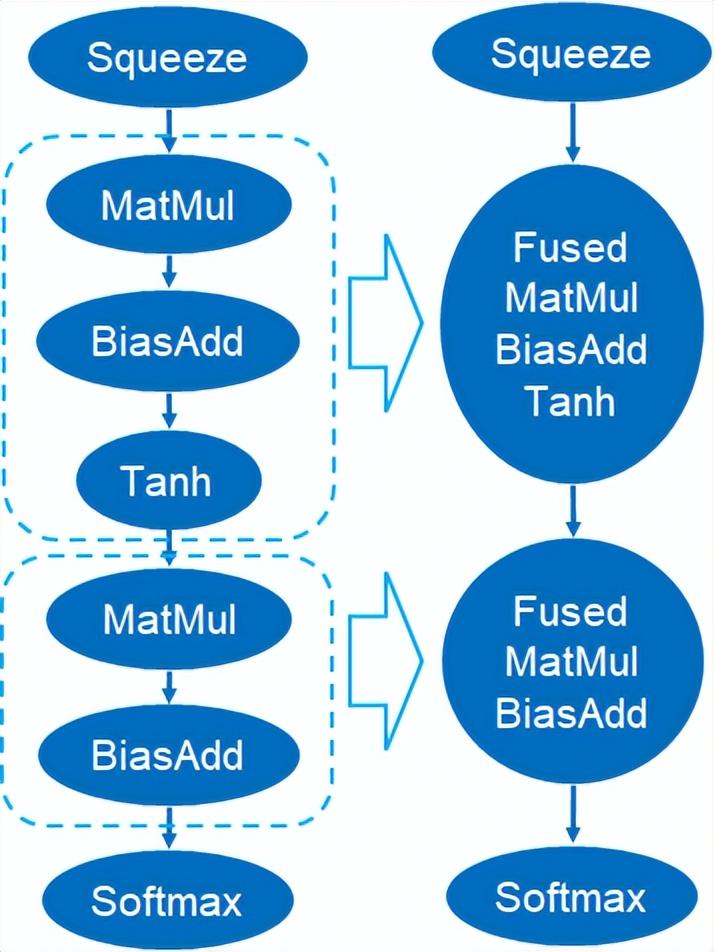
图融合
内存优化
内存分配与释放会与操作系统进行通信,从而导致运行时的延时增加,为了减少这部分的开销,Custom Backend中增加了Primitive Cache的设计,Primitive Cache用于缓存已经被创建的Primitive,使得Primitive不能被系统回收,减少了下一次调用时的创建开销。
同时为耗时较大的算子建立了快取机制,以加速算子运行,如下图所示:
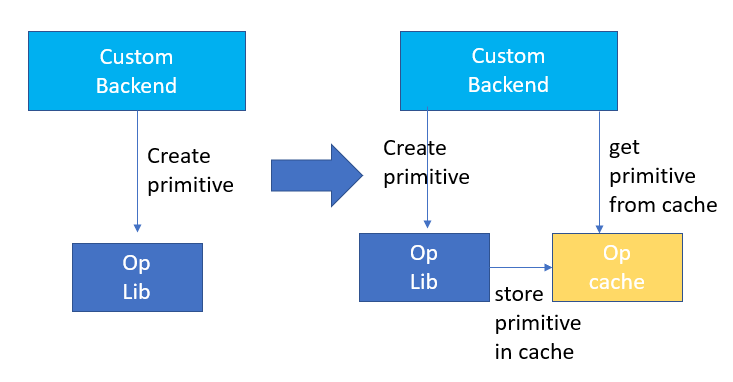
Primitive Cache
量化功能如之前所说,模型大小减小后,计算与存取的开销大幅减少,从而性能得到巨大的提升。
4. 整体性能展示
我们选取了地址搜索服务中典型的两个模型结构来验证上述优化方案的效果。测试环境如下所示:
- 服务器型号:阿里云 ecs.g7.large,2 vCPU
- 测试CPU型号:Intel® Xeon® Platinum 8369B CPU @ 2.70GHz
- 测试CPU核数:1 vCPU
- PyTorch版本:1.9.0+cpu
- onnx版本:1.11.0
- onnxruntime版本:1.11.1
4.1 ESIM
ESIM[6]是一种专为自然语言推断而生的加强版LSTM,它的推理开销主要来自于模型中的LSTM结构。Blade利用Intel数据中心软件团队开发的高性能通用LSTM算子对其进行加速,替换PyTorch module中的默认LSTM (Baseline)。本次测试的ESIM中包含两种LSTM结构,单算子优化前后的性能如表所示:
LSTM结构 | 输入shape | 优化前RT | 优化后RT | 加速比 |
LSTM - A | 7x200 | 0.199ms | 0.066ms | +3.02x |
202x200 | 0.914ms | 0.307ms | +2.98x | |
LSTM - B | 70x50 | 0.266ms | 0.098ms | +2.71x |
202x50 | 0.804ms | 0.209ms | +3.85x |
LSTM单算子优化前后推理性能
优化前后,ESIM端到端推理速度如表 所示,同时优化前后模型的精度保持不变。
模型结构 | ESIM[6] | ESIM[6]+Blade算子优化 | 加速比 |
RT | 6.3ms | 3.4ms | +1.85x |
ESIM模型优化前后推理性能
4.2 BERT
BERT[7]近年来在自然语言处理 (NLP) 、计算机视觉(CV)等领域被广泛采纳。Blade对该种结构有编译优化(FP32)、量化(INT8)等多种手段。
速度测试中,测试数据的shape固定为10x53,各种后端及各种优化手段的速度性能如下表所示。可以看到,blade编译优化后或INT8量化后的模型推理速度均优于libtorch与onnxruntime,其中推理的后端是Intel Custom Backend & BladeDisc。值得注意的是,经过量化加速后的4层BERT的速度是2层BERT的1.5倍,意味着可以在提速的同时,让业务用上更大的模型,获得更好的业务精度。
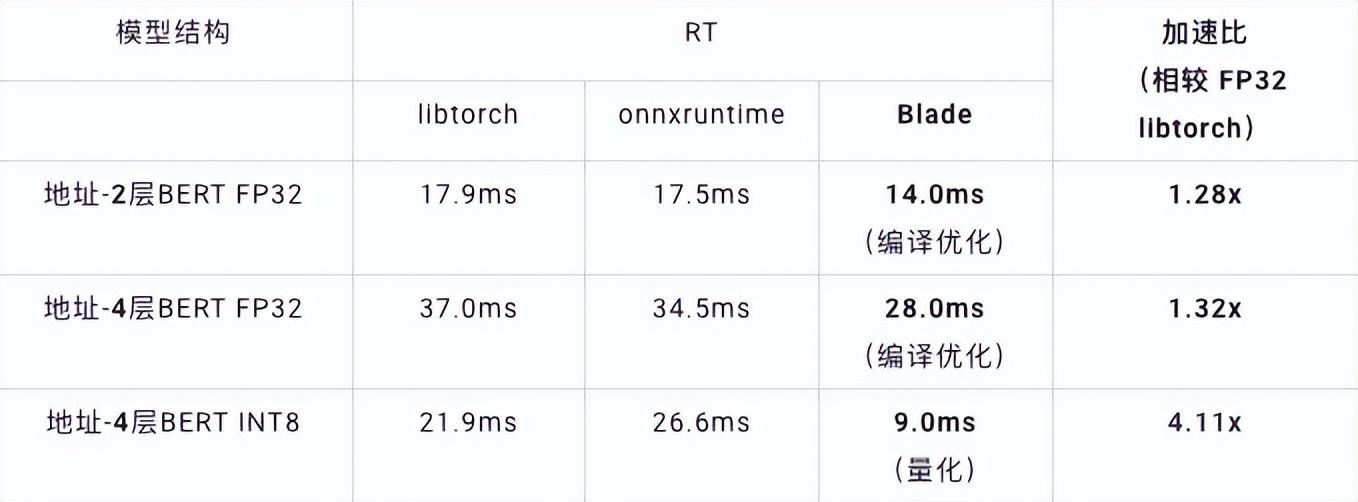
地址BERT推理性能展示
精度方面,我们基于CCKS2021中文NLP地址相关性任务[5]展示相关模型性能,如下表所示。达摩院地址团队自研的4层BERT的macro F1精度要高于标准的12层BERT-base。Blade编译优化可以做到精度无损,而经过Blade Compression量化训练后的真实量化模型精度要略高于原始浮点模型。
模型结构 | macro F1(越高越好) |
12层BERT-base | 77.24 |
地址-4层BERT | 78.72(+1.48) |
地址-4层BERT + Blade编译优化 | 78.72(+1.48) |
地址-4层BERT + Blade量化 | 78.85(+1.61) |
地址BERT相关精度结果



















