定义
hash 是一种把任意长度输入变换成固定长度输出的一种算法。
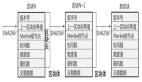
假设我们已经定义了一个 hash 函数名为 H,输入内容为 message,输出内容为 x,那么就有如下公式。
这是一个压缩的过程,通常情况下,我们会把输出值称之为 hash 值。
接下来通过一个具体的案例来了解 hash 的过程。
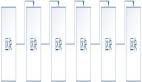
我们定义这样一个场景,约定任意正整数,要存放在长度为 6 的数组中,那么此时,我们可以利用 hash 的思想设计什么样的方案来做到这个事情呢?
数组的具体位置我们可以用下标来表示 0, 1, 2, 3, 4, 5。想要将任意正整数放入到数组中,那么我们只需要设计一个函数,输入值为任意正整数,输出值为该数组下标中的任意一个即可,得到了输出值,我们就相当于知道应该把输入值放到数组中的某个位置了。

我们可以使用求余法来定义这个 hash 函数。
于是,随便取几个数,得到 hash 值之后就能存入数组对应的位置。


此时的哈希值表示的是数组的下标,因此在很多应用场景,输出结果哈希值也被称为哈希地址。
哈希碰撞
在上面的例子中,输入值的范围一定大于输出值的范围,这是 hash 的重要特性之一。因此在某些情况下,不同的输入会得到相同的输出结果。
此时哈希地址相同,按照规则,我们不得不把不同的值,存入相同的位置,这种情况就被称之为哈希碰撞(collision)。
解决哈希碰撞的方法很多,这里介绍一个比较常见的方法:以数组的每个地址为根节点,构建一个新的链表。
例如当输入数字分别为 7, 61 时。

但是当数据量庞大时,链表的查询速度比较低效,因此我们在实践中,会将链表替换成红黑树等操作效率更高的数据结构。
当然,最理想的情况是输出范围足够广,不出现 hash 碰撞。因此我们实践中使用的 hash 函数,输出值的范围都非常庞大,例如早期用得比较多的 md5,现在使用比较多的sha256:比特币中使用的哈希算法。但是由于输入值范围一定大输出值范围,因此理论上哈希碰撞一定会存在。
现在 md5 已经可以人为制造 hash 碰撞,因此实用性大大降低。
本文转载自微信公众号「这波能反杀」,可以通过以下二维码关注。转载本文请联系这波能反杀公众号。