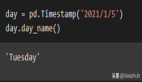
Pandas是一个在数据科学中常用的功能强大的Python库。它可以从各种来源加载和操作数据集。当使用Pandas时,默认选项就已经适合大多数人了。但是在某些情况下,我们可能希望更改所显示内容的格式。所以就需要使用Pandas的一些定制功能来帮助我们自定义内容的显示方式。

1、控制显示的行数
在查看数据时,我们希望看到比默认行数更多或更少的行数(默认行数为10)。
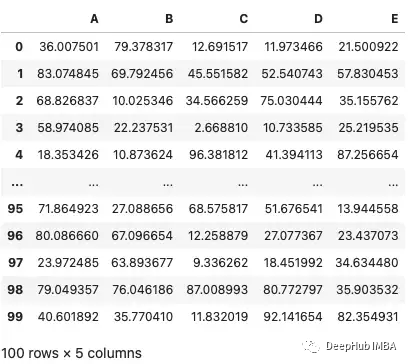
可以看到,默认包括数据帧的前5行和后5行。因为这样可以防止pandas在调用数据框架时显示大量的数据,从而降低计算机的速度。
这里有两个选项可用于控制显示的行数。
首先是display.max_rows,它控制在截断之前显示的最大行数。如果数据中的行数超过此值,则显示将被截断。默认设置为60。
如果希望显示所有行,则需要将display.max_rows设置为None。如果数据非常大,这可能会占用很多资源并且降低计算速度。
这样就可以看到df中的所有行。

如果数据的行数多于 max_rows 设置的行数,则必须将 display.min_rows 参数更改为要显示的值。还需要确保 max_rows 参数大于 min_rows。
如果将min_rows设置为20,那么当查看时,将看到顶部有10行,底部有10行。
2、控制显示的列数
当处理包含大量列的数据集时,pandas将截断显示,默认显示20列。下图第9列和第15列之间的三个点(省略号)表示已经被截断了
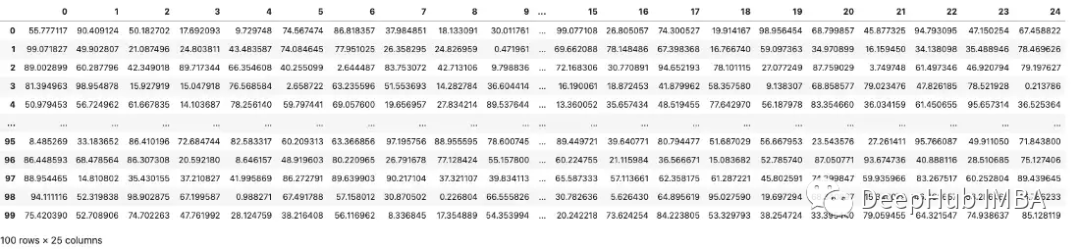
上述数据,是使用以下代码显示的:
要查看显示上的更多列,可以更改display.max_columns参数
这样做最多将显示30列。但是这可能会导致其他问题,例如当有图片时这会变得很难看。

3、禁止科学记数法
通常在处理科学数据时,你会遇到非常大的数字。一旦这些数字达到数百万,Pandas就会将它们重新格式化为科学符号,这可能很有帮助,但并不总是如此。
要生成具有非常大值的数据,可以使用以下代码。
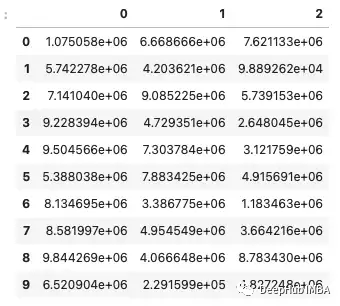
如果想要显示这些数字的完整形式而不使用科学符号。这可以通过更改float_format显示选项并传入一个lambda函数来实现。这将重新格式化显示,使其具有不带科学记数法的值和最多保留小数点后3位。
如果你想让它看起来更好看,你可以在千位之间添加逗号分隔符。
下面的代码可能看起来与上面的相同,但是如果您仔细查看该代码的f'{x:部分后面有一个逗号。

4、更改数据的浮点精度
在某些情况下,数据可能在小数点后有太多的值,这样看起来很乱。默认情况下,Pandas将在小数点后显示6个位。

为了使它更容易阅读,可以通过调用display.precision来减少显示的值的数量。
数值列的浮点精度已降低到2。

此设置只更改数据的显示方式。它不更改底层数据值。
5、控制Float格式
在某些情况下,数字可以代表百分比或货币价值。如果是这种情况,用正确的单位来格式化它们是很方便的。
若要在列后面添加百分比符号,可以调用display.float_format选项,并使用f-string传入想要显示的格式:

要以美元符号开始,可以这样更改代码:

6、更改默认的Pandas绘图库
在进行探索性数据分析时,通常需要快速生成数据图。可以使用matplotlib来构建一个plot,但是在Pandas中可以使用.plot()方法使用几行代码来完成它。
Pandas为我们提供了一系列可以使用的绘图库:
- matplotlib
- hvplot >= 0.5.1
- holoviews
- pandas_bokeh
- plotly >= 4.8
- altair
要更改当前的默认绘图库,需要更改plotting.backend选项。
这样就使用.plot方法创建plot时就会调用设置的库

7、重置显示选项
如果希望将特定选项的参数设置回默认值,可以调用reset_option方法并传入想要重置的选项。
或者可以通过all作为参数将它们全部更改回默认值。
如果想一次设置多个选项可以这样做。
这样做可以帮助节省时间,减少编写的代码数量,提高可读性。
总结
Pandas是一个功能强大的库,但是默认选项可能不适合特定的需要。本文介绍了一些常用选项,可以改进查看数据的方式。