1、语音合成概念介绍
语音合成简单来说就是把文字信息转换为标准语音的过程,最终可以输出对应的音频文件。可以实现让机器像人类一样可以实时的说话。涉及的领域有声学、语言学、数字信号处理、计算机管理等方面的知识。
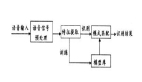
2、语音合成的过程
主要包括:获取输入的文本→语言处理→韵律处理→声学处理→输出音频文件。其中语音识别主要是语言处理、韵律处理、声学处理三个阶段的操作。
2.1 语言处理
该阶段主要是模拟人类对大自然语言理解的过程,主要工作有输入文本分析、分词、语义分析,目的是让计算机能够尽可能准确理解输入文本的含义并为后面的环节做准备。
2.2 韵律处理
主要是为合成的语音规划出音高、音长、音强等语音特征,目的是为了让合成的语音能表达确切的语意,使得输出的音频文件更符合实际。
2.3 声学处理
这个阶段主要是把前两个阶段处理结果合成最终的音频文件。
3、语音合成使用场景
3.1 智能服务方面
智能服务方面主要包括语音机器人、智能音响等设备。通过语音合成语音可以输出形形色色的声音,比如甜美亲切的银行导航机器人;呆萌可爱的早教机器人;智能音响也极大丰富了我们的日常生活比如通知智能音响可以播放歌曲、相声、新闻、讲故事等实用功能。
3.2 APP应用方面
手机APP应用就更加广泛了,比如手机阅读器的听书功能、地图的导航播报功能、手机自带的语音助手、视频剪辑通过文字直接转换音频文件等方面应用非常广泛。