













译者 | 李睿
审校 | 孙淑娟
提高分析性能非常重要。大家都明白这一点,但要确保用户在不增加额外工作量的情况下获得所需的速度,最好的方法是什么?
作为数据工程师,通常面临着这个挑战。为了找到解决方案,一个研究团队启动了开放项目StarRocks,这是一个分析引擎,可以满足快速增长的分析性能需求,同时也易于使用和维护。
随着开放项目和技术社区在过去几年的发展,人们已经了解到很多关于分析性能的有效方法和无效方法。如今分享一些关于构建高性能分析引擎的关键技术之一的见解:向量化。
为什么向量化可以提高数据库性能
在深入研究StarRocks如何实现向量化之前,有一点很重要:当谈论向量化时,谈论的是使用现代CPU架构的数据库的向量化。有了这些了解,就可以开始回答这个问题:为什么向量化可以提高数据库性能?
要回答这个问题,首先要回答以下几个问题:
(1)如何衡量CPU性能?
(2)影响CPU性能的因素有哪些?
第一个问题的答案可以用这个公式表示:
CPU时间=(指令数)*CPI*(时钟周期时间)
- 指令数=CPU生成的指令数
- CPI(每条指令的周期)=执行一条指令所需的CPU周期
- 时钟周期时间=CPU时钟周期所用的时间
这个公式提供了一些术语,可以用来讨论影响性能的杠杆。由于对时钟周期时间无能为力,所以需要关注指令号和CPI来提高软件性能。
此外,还知道的另一个重要信息是,CPU指令的执行可以分为五个步骤:
(1)提取
(2)解码
(3)执行
(4)内存访问
(5)写回结果(写入寄存器)
步骤1和步骤2由CPU前端执行,步骤3到步骤5由CPU后端处理。Intel公司发布了自顶向下微架构分析方法,如下图所示。
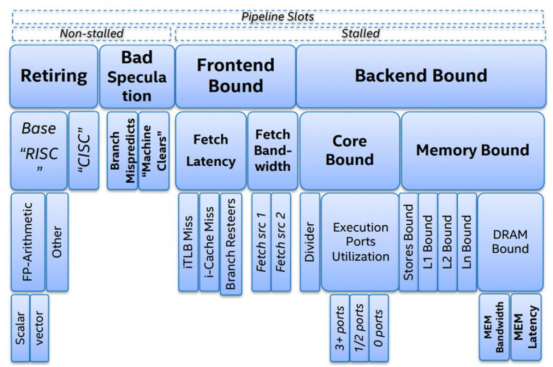
自顶向下微架构分析方法(Intel)
下面是上述方法的简化版本。
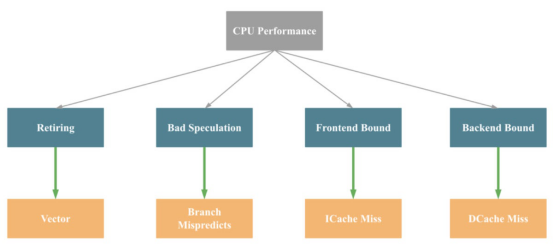
正如人们所看到的,导致CPU性能问题的主要因素是退役、错误猜测、前端绑定和后端绑定。
这些问题背后的主要驱动因素分别是缺乏SIMD指令优化、分支预测错误、指令缓存失误和数据缓存失误。
因此,如果将上述原因映射到前面介绍的CPU性能公式,可以得到以下结论:
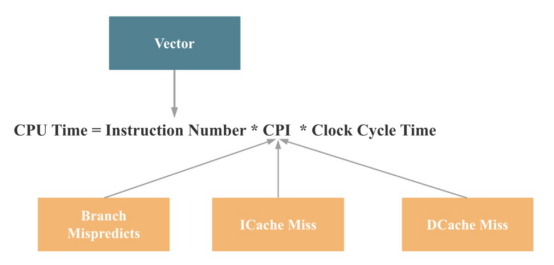
那么,设计什么来提高这四个方面的CPU性能呢?
没错,是向量化。
现在已经确定了向量化可以提高数据库性能。下面将讲解向量化是如何做到这一点。
向量化的基本原理
如果已经很好地理解了向量化,那么可以跳过这一节,然后转到关于数据库向量化的一节,但是如果不熟悉向量化的基础知识,或者可能需要复习一下,那么将简要概述应该知道的内容。
在这里将向量化的讨论局限于SIMD。SIMD向量化不同于接下来将要讨论的一般数据库向量化。
SIMD的介绍
SIMD的意思是“单指令、多数据”。顾名思义,使用SIMD架构,一条指令可以同时操作多个数据点。在SISD(单指令、单数据)架构中,其中一条指令只能在单个数据点上操作,但情况并非如此。
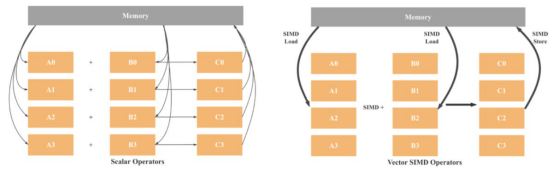
如上所述,在SISD架构中,操作是标量的,这意味着只处理一组数据。因此,4个添加操作将涉及8个加载操作(每个变量一个)、4个添加操作和4个存储操作。如果使用128位SIMD,只需要两个加载,一个添加,一个存储。在理论上,与SISD相比,性能提高了4倍。考虑到现代CPU已经有512位寄存器,可以预期高达16倍的性能增益。
如何向量化一个程序?
以上了解了SIMD向量化如何极大地提高程序的性能。那么,如何开始在自己的工作中使用它呢?
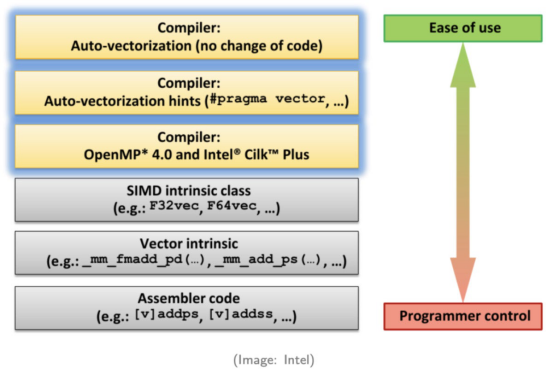
调用SIMD的不同方法
正如英特尔公司的这张图片所示,SIMD有六种调用方式。从上到下,每个方法都需要程序员更多的专业知识,并需要更多的编码工作。
方法1.编译器自动向量化
程序员不需要对他们的代码做任何更改。编译器将自动将标量代码转换为向量代码。只有一些简单的情况可以自动转换为向量代码。
方法2.给编译器的提示
在这个方法中,向编译器提供了一些提示。通过提供额外的信息,编译器可以生成更多的SIMD代码。
方法3.并行编程API
在OpenMP或Intel TBB等并行编程API的帮助下,开发人员可以添加Pragma来生成向量代码。
方法4.使用SIMD类库
这些库包装了启用SIMD指令的类。
方法5.使用SIMD intrinsic
intrinsic是一组程序集编码的函数,允许使用c++函数调用和变量来代替程序集指令。
方法6.直接编写程序集代码
1和方法2。对于不能自动转换为向量代码的性能关键操作,将使用SIMD intrinsic。
验证程序实际生成了SIMD代码
这里有一个重要的问题,当一个程序有一个复杂的代码结构,那么如何确保代码执行是向量化的?
有两种方法可以检查和确认代码已经向量化。
方法1.向编译器添加选项
有了这些选项,编译器将生成关于代码是否向量化的输出,如果没有,原因是什么。例如,可以在GCC编译器中添加--fopt-info-vec-all, -fopt-info-vec-optimized, -fopt-info-vec-missed, 和 -fopt-info-vec-note选项,如下图所示:
方法2.检查执行的程序集代码
可以使用https://gcc.godbolt.org/这样的网站或Perf和Vtun这样的工具来检查程序集代码。如果汇编代码中的寄存器是xmm、ymm、zmm等,或者指令以v开头,那么就知道该代码已经向量化了。
既然已经掌握了向量化的基础知识,现在是时候讨论向量化数据库提高性能的能力了。
数据库的向量化
虽然StarRocks项目已经发展成为一个成熟、稳定、行业领先的MPP数据库(甚至还从CelerData推出了企业级版本),但该社区必须克服许多挑战才能实现这一目标。数据库向量化是最大的突破之一,也是最大的挑战之一。
数据库向量化的挑战
根据经验,向量化数据库要比简单地在CPU中启用SIMD指令复杂得多。这是一个庞大的系统工程。特别是面临着六个技术挑战:
(1)端到端的柱状数据。数据需要跨存储层、网络层和内存层以柱状格式存储、传输和处理,以消除“阻抗失配”。存储引擎和查询引擎需要重新设计以支持列数据。
(2)所有运算符、表达式和函数都必须实现向量化。这是一项艰巨的任务,需要几年才能完成。
(3)如果可能,操作符和表达式应该调用SIMD指令。这需要详细的逐行优化。
(4)内存管理。为了充分利用SIMD CPU的并行处理能力,必须重新考虑内存管理。
(5)新的数据结构。所有用于核心操作符的数据结构,如连接、聚合、排序等,都需要从头开始支持向量化。
(6)系统的优化。对StarRocks的目标是,与其他市场领先的产品(具有相同的硬件配置)相比,性能提高5倍。为了达到这个目标,必须确保数据库系统中的所有组件都得到了优化。
向量化运算符和表达式
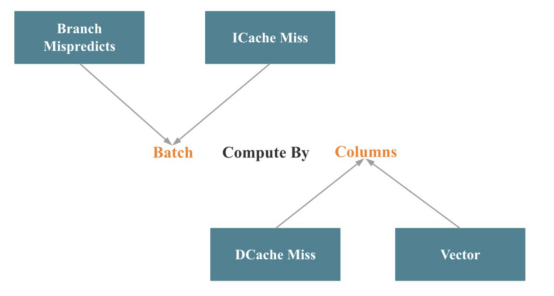
在向量化StarRocks时,大部分工程工作都花在向量化操作符和表达式上。这些工作可以总结为按列批量计算,如下图所示:
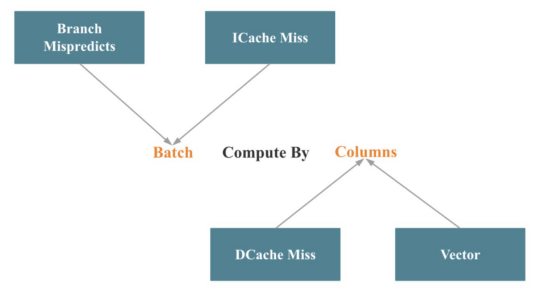
与本文前面讨论的Intel公司自顶向下微架构分析方法相对应,Batch减少了分支错误预测和指令缓存失误。按列减少了数据缓存丢失,并使调用SIMD优化更容易。
实现批处理计算相对容易。困难的部分是关键操作符(如联接、聚合、排序和混洗)的列处理。在进行柱状处理的同时调用尽可能多的SIMD优化是一个更大的挑战。
如何用数据库向量化提高数据库性能
如上所述,向量化数据库是一项系统工程工作。在过去的几年里,在开发StarRocks的过程中实施了数百项优化。以下是需要关注的7个最重要的优化领域。
- 高性能的第三方库。对于数据结构和算法,有许多优秀的开源库。对于StarRocks,使用了许多第三方库,例如Parallel Hashmap、Fmt、SIMD Json和Hyper Scan。
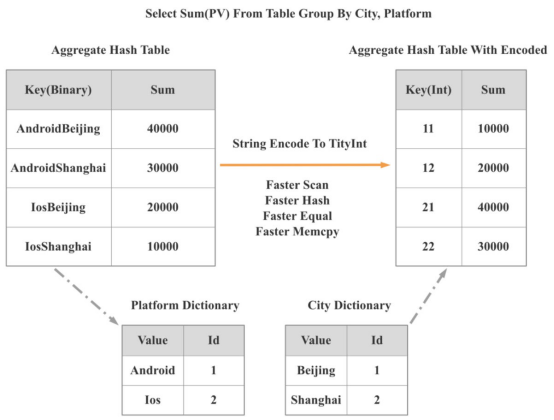
- 数据结构和算法。高效的数据结构和算法可以将CPU周期减少一个数量级。正因为如此,当StarRocks 2.0发布时,引入了一个低基数的全局字典。使用这个全局字典,可以将基于字符串的操作转换为基于整数的操作。
如下图所示,通过操作将两个基于字符串的组转换为一个基于整数的组。因此,扫描、散列、相等和mumcpy等操作的性能提高了许多倍,整体查询性能提高了300%以上。
- 自适应优化。如果能够理解查询的场景,就可以进一步优化查询执行。然而,通常直到执行时才得到查询场景信息。因此,查询引擎必须根据在查询执行过程中获得的场景信息动态调整其策略。这被称为自适应优化。
下面的代码片段显示了一个基于选择率动态选择连接运行时过滤器的示例:
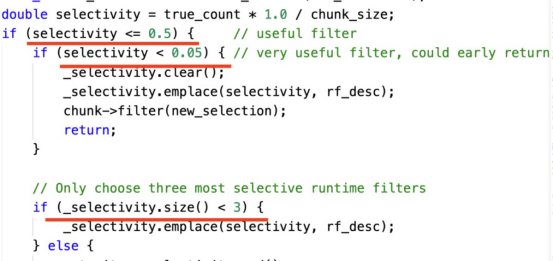
有三个决策点可以指导上述示例:
(1)如果过滤器不能过滤大部分数据,那么就不会使用它。
(2)如果一个过滤器可以过滤几乎所有的数据,那么我们只保留这个过滤器。
(3)最多保留三个过滤器。
- SIMD优化。如下图所示,StarRocks在其操作符和表达式实现中进行了大量SIMD优化。
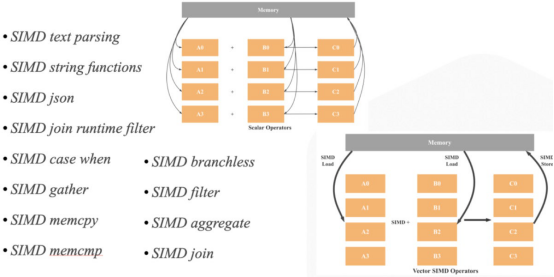
- C++底层优化。即使使用相同的数据结构和算法,不同C++实现的性能也可能不同。例如,可以使用移动或复制操作,可以保留向量,或者可以内联函数调用。这些只是必须考虑的一些优化。
- 内存管理优化。批处理大小越大,并发性越高,分配和释放内存的频率就越高,内存管理对系统性能的影响就越大。
使用StarRocks,实现了一个列池数据结构来重用列的内存,并显著提高了查询性能。以下的代码片段显示了一个HLL(HyperLogLog)聚合函数内存优化。通过按块分配HLL内存,并通过重用这些块,将HLL的聚合性能提高了五倍。
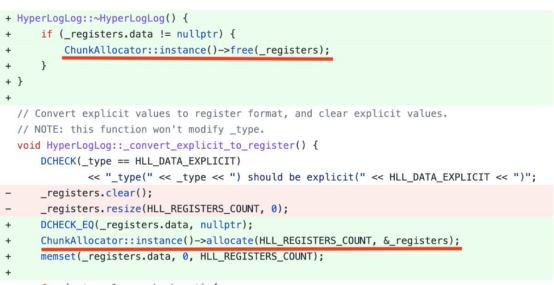
- CPU缓存优化。CPU缓存丢失对性能有巨大的影响。可以从CPU周期的角度来理解这种影响。L1访问缓存需要3个CPU周期,L2访问缓存需要9个CPU周期,L3访问缓存大约需要40个CPU周期,主存访问缓存大约需要200个CPU周期。
在调用SIMD优化和性能瓶颈从CPU限制转移到内存限制之后,CPU缓存缺失成为了一个特别重要的因素。下面的代码片段展示了如何通过预取减少CPU丢失。不过在这里指出的是,预取应该是优化CPU缓存的最后手段。这是因为很难控制预取的时间和距离。
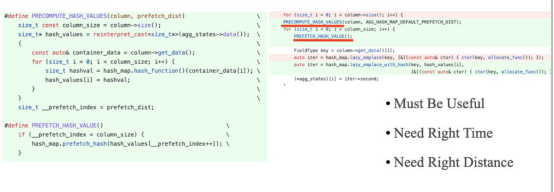
回顾与感想
现在已经踏上了StarRocks数据库向量化的旅程,以下回顾一下学到了什么。
- 不同系统的基本原理是相似的。当开始研究CPU的微架构时,意识到CPU的架构与数据库架构的相似之处。在StarRocks的例子中,前端管理SQL解析和查询规划,后端负责SQL执行和与存储层交互。研究的系统和体系结构越多,就会越深入地理解系统级别的相似性。
- 要建立高性能的数据库,不仅需要设计良好的架构,而且还需要密切关注工程细节。虽然良好的设计和良好的工程似乎都是很明显的需要,但在数据库产品中往往缺少其中之一。如果真的相信这两者,就不会只使用自底向上的方法(从算法和唯一的组件开始)来设计数据库,而不实现确保所有这些组件都能很好地协同工作的高级架构。也不能选择Java或Go等编程语言来实现查询执行引擎和存储引擎,而可以使用C++等更多性能语言。

- 混合向量化和编译。向量化和编译是两种主要的查询执行风格,但它们并不相互排斥。尽管大多数开源数据库都选择使用向量化,但可以利用查询编译,通过查询执行期间获得的信息生成更高效的向量代码。与此同时,查询编译也在不断改进。
- 尝试采用新的硬件,例如GPUu和FPGA。经过大量优化后,可能已经接近CPU优化的收益递减点。可以考虑其他新的硬件,以进一步提高StarRocks的性能。
随着数据量的增长、数据源的扩展和用户期望的提高,数据工程师的角色在未来几年只会变得更加重要。有了StarRocks这样的项目和数据库向量化这样的创新,可以满足遇到的任何性能需求。
原文标题:How vectorization improves database performance,作者:James Li,Kaisen Kang





















