一、前情回顾
我们采用冷热数据分离:
冷数据基于HBase+Elasticsearch+纯内存自研的查询引擎,解决了海量历史数据的高性能毫秒级的查询
热数据基于缓存集群+MySQL集群做到了当日数据的几十毫秒级别的查询性能。
最终,整套查询架构抗住每秒10万的并发查询请求,都没问题。
本文作为这个架构演进系列的最后一篇文章,我们来聊聊高可用这个话题。所谓的高可用是啥意思呢?
简单来说,就是如此复杂的架构中,任何一个环节都可能会故障,比如MQ集群可能会挂掉、KV集群可能会挂掉、MySQL集群可能会挂掉。那你怎么才能保证说,你这套复杂架构中任何一个环节挂掉了,整套系统可以继续运行?
这就是所谓的全链路99.99%高可用架构,因为我们的平台产品是付费级别的,付费级别,必须要为客户做到最好,可用性是务必要保证的!
我们先来看看目前为止的架构是长啥样子的。
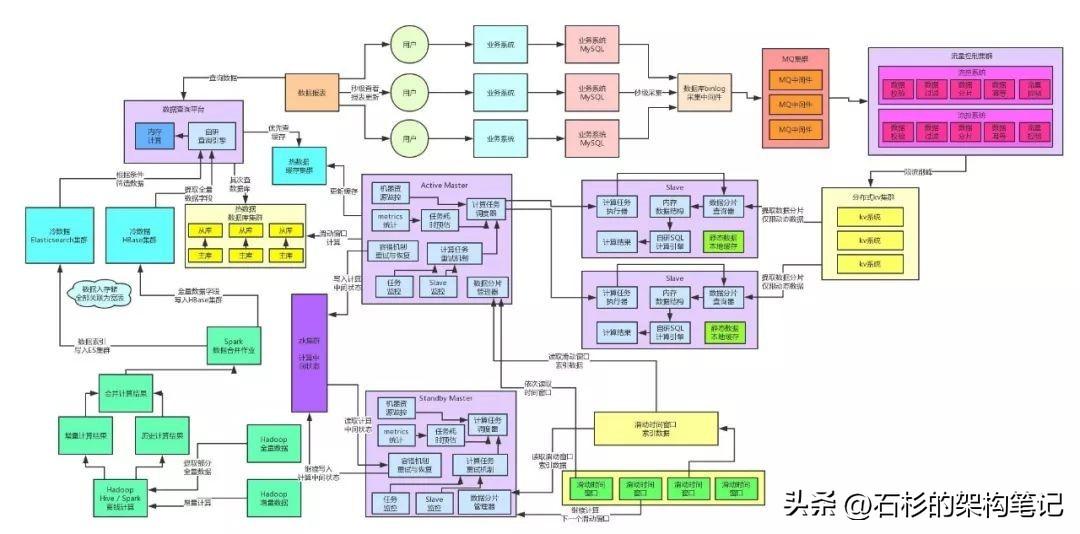
二、MQ集群高可用方案
异步转同步 + 限流算法 + 限制性丢弃流量
MQ集群故障其实是有概率的,而且挺正常的,因为之前就有的大型互联网公司,MQ集群故障之后,导致全平台几个小时都无法交易,严重的会造成几个小时公司就有数千万的损失。我们之前也遇到过MQ集群故障的场景,但是并不是这个系统里。
大家想一下,如果这个链路中,万一MQ集群故障了,会发生什么?
看看右上角那个地方,数据库binlog采集中间件就无法写入数据到MQ集群了啊,然后后面的流控集群也无法消费和存储数据到KV集群了。这套架构将会彻底失效,无法运行。
这个是我们想要的效果吗?那肯定不是的,如果是这样的效果,这个架构的可用性保障也太差了。
因此在这里,我们针对MQ集群的故障,设计的高可用保障方案是:异步转同步 + 限流算法 + 限制性丢弃流量。
简单来说,数据库binlog采集环节一旦发现了MQ集群故障,也就是尝试多次都无法写入数据到MQ集群,此时就会触发降级策略。不再写入数据到MQ集群,而是转而直接调用流控集群提供的备用流量接收接口,直接发送数据给流控集群。
但是流控集群也比较尴尬,之前用MQ集群就是削峰的啊,高峰期可以稍微积压一点数据在MQ集群里,避免流量过大,冲垮后台系统。
所以流控集群的备用流量接收接口,都是实现了限流算法的,也就是如果发现一旦流量过大超过了阈值,直接采取丢弃的策略,抛弃部分流量。
但是这个抛弃部分流量也是有讲究的,你要怎么抛弃流量?如果你不管三七二十一,胡乱丢弃流量,可能会导致所有的商家看到的数据分析结果都是不准确的。因此当时选择的策略是,仅仅选择少量商家的数据全量抛弃,但是大部分商家的数据全量保存。
也就是说,比如你的平台用户有20万吧,可能在这个丢弃流量的策略下,有2万商家会发现看不到今天的数据了,但是18万商家的数据是不受影响,都是准确的。但是这个总比20万商家的数据全部都是不准确的好吧,所以在降级策略制定的时候,都是有权衡的。
这样的话,在MQ集群故障的场景下,虽然可能会丢弃部分流量,导致最终数据分析结果有偏差,但是大部分商家的数据都是正常的。
大家看看下面的图,高可用保障环节全部选用浅红色来表示,这样很清晰。
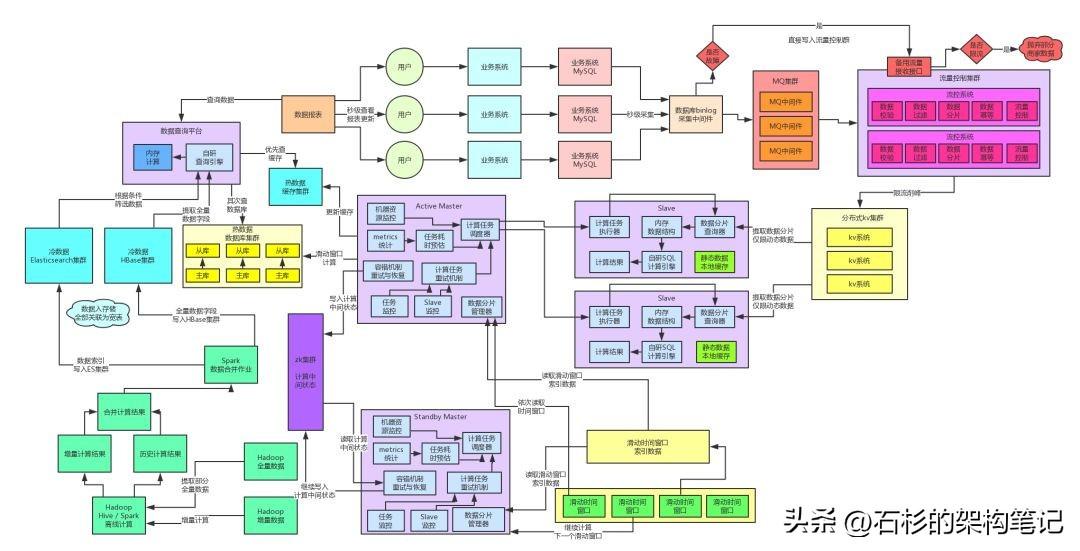
三、KV集群高可用保障方案
临时扩容Slave集群 + 内存级分片存储 + 小时级数据粒度
下一个问题,如果KV集群挂了怎么办?这个问题我们还真的遇到过,不过也不是在这个系统里,是在另外一个我们负责过的核心系统里,KV集群确实出过故障,直接从持续好多个小时,导致公司业务都几近于停摆,损失也是几千万级别的。
大家看看那个架构图的右侧部分,如果KV集群挂了咋办?那也是灾难性的,因为我们的架构选型里,直接就是基于kv集群来进行海量数据存储的,要是KV挂了,没任何高可用保障措施的话,会导致流控集群无法把数据写入KV集群,此时后续环节就无法继续计算了。
我们当时考虑过要不要引入另外一套存储进行双写,比如引入一套hbase集群,但是那样依赖会搞的更加的复杂,打铁还需自身硬,还是要从自身架构来做优化。
因此,当时选择的一套kv集群降级的预案是:临时扩容Slave集群 + 小时级数据粒度 + 内存级分片存储。
简单来说,就是一旦发现kv集群故障,直接报警。我们收到报警之后,就会立马启动临时预案,手动扩容部署N倍的Slave计算集群。
接着同样会手动打开流控集群的一个降级开关,然后流控集群会直接按照预设的hash算法分发数据到各个Slave计算节点。
这就是关键点,不要再基于kv集群存数据了,本身我们的Slave集群就是分布式计算的,那不是刚好可以临时用作分布式存储吗!直接流控集群分发数据到Slave集群就行了,Slave节点将数据留存在内存中即可。
然后Master节点在分发数据计算任务的时候,会保证计算任务分发到某个Slave节点之后,他只要基于本地内存中的数据计算即可。
将Master节点和Slave节点都重构一下,重构成本不会太高,但是这样就实现了本地数据存储 + 本地数据计算的效果了。
但是这里同样有一个问题,要知道当日数据量可是很大的!如果你都放Slave集群内存里还得了?
所以说,既然是降级,又要做一个balance了。我们选择的是小时级数据粒度的方案,也就是说,仅仅在Slave集群中保存最近一个小时的数据,然后计算数据指标的时候,只能产出每个小时的数据指标。
但是如果是针对一天的数据需要计算出来的数据指标,此时降级过后就无法提供了,因为内存中永远只有最近一个小时的数据,这样才能保证Slave集群的内存不会被撑爆。
对用户而言,就是只能看当天每个小时的数据指标,但是全天汇总的暂时就无法看到。
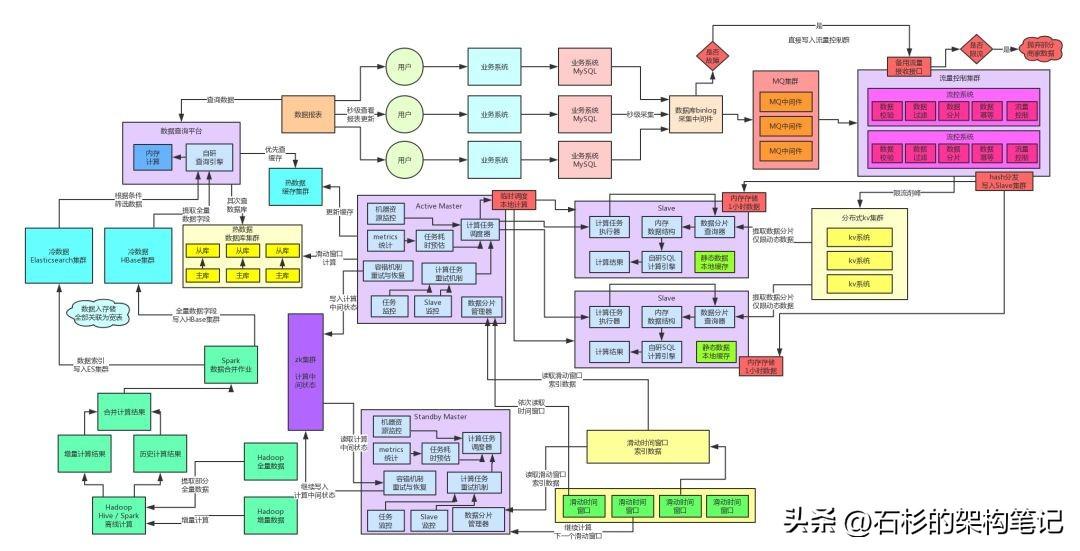
四、实时计算链路高可用保障方案
计算任务重分配 + 主备切换机制
下一块就是实时计算链路的高可用保障方案了,其实这个之前给大家说过了,实时计算链路是一个分布式的架构,所以要么是Slave节点宕机,要么是Master节点宕机。
其实这个倒没什么,因为Slave节点宕机,Master节点感知到了,会重新分配计算任务给其他的计算节点;如果Master节点宕机,就会基于Active-Standby的高可用架构,自动主备切换。
咱们直接把架构图里的实时计算链路中的高可用环节标成红色就可以了。
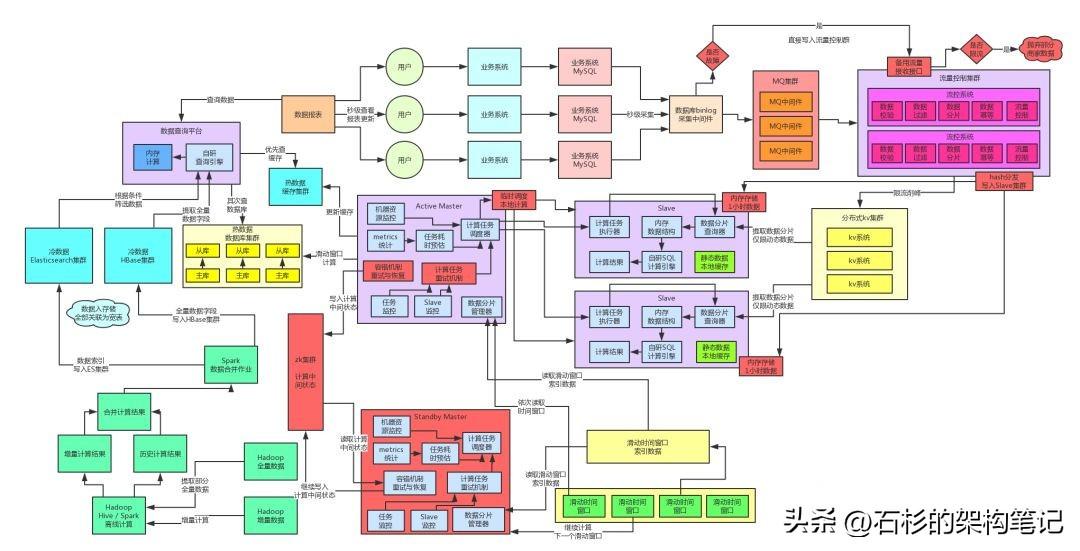
五、热数据高可用保障方案
自研缓存集群查询引擎 + JVM本地缓存 + 限流机制
接着咱们来看左侧的数据查询那块,热数据也就是提供实时计算链路写入当日数据的计算结果的,用的是MySQL集群来承载主体数据,然后前面挂载一个缓存集群。
如果出现故障,只有两种情况:一种是MySQL集群故障,一种是缓存集群故障。
咱们分开说,如果是MySQL集群故障,我们采取的方案是:实时计算结果直接写入缓存集群,然后因为没有MySQL支撑,所以没法使用SQL来从MySQL中组装报表数据。
因此,我们自研了一套基于缓存集群的内存级查询引擎,支持简单的查询语法,可以直接对缓存集群中的数据实现条件过滤、分组聚合、排序等基本查询语义,然后直接对缓存中的数据查询分析过后返回。
但是这样唯一的不好,就是缓存集群承载的数据量远远没有MySQL集群大,所以会导致部分用户看不到数据,部分用户可以看到数据。不过这个既然是降级 ,那肯定是要损失掉部分用户体验的。
如果是缓存集群故障,我们会有一个查询平台里的本地缓存,使用ehcache等框架就可以实现,从mysql中查出来的数据在查询平台的jvm本地缓存里cache一下,也可以用作一定的缓存支撑高并发的效果。而且查询平台实现限流机制,如果查询流量超过自身承载范围,就限流,直接对查询返回异常响应。
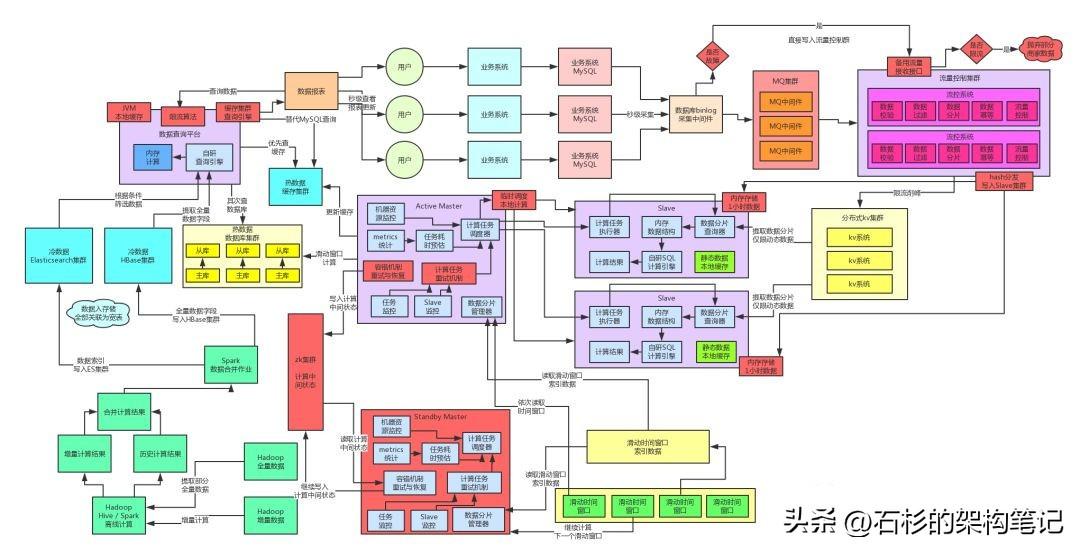
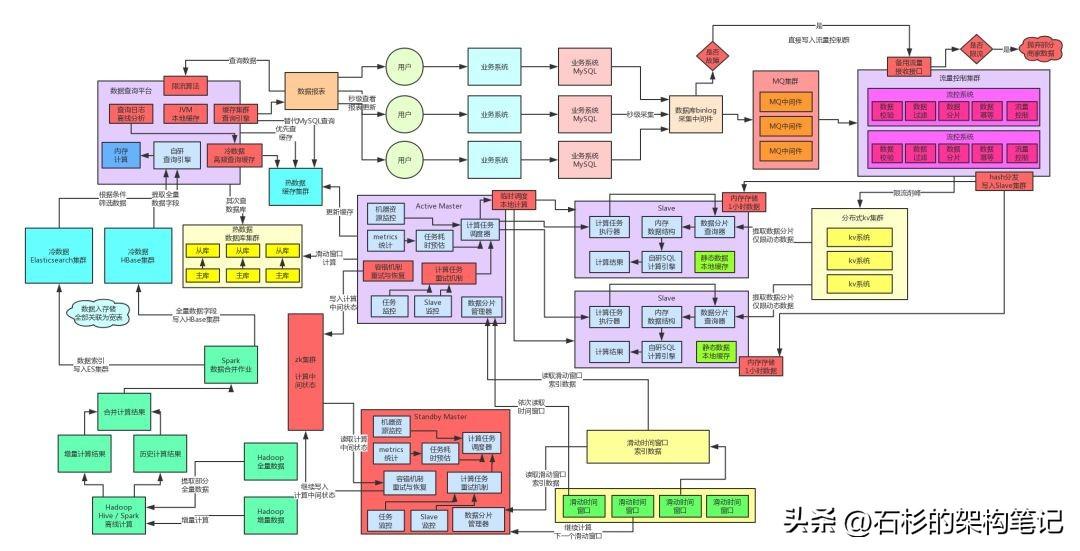
六、冷数据高可用保障方案
收集查询日志 + 离线日志分析 + 缓存高频查询
其实大家看上面的图就知道,冷数据架构本身就比比较复杂,涉及到ES、HBase等东西,如果你要是想做到一点ES、HBase宕机,然后还搞点儿什么降级方案,还是挺难的。
你总不能ES不能用了,临时走Solr?或者HBase不能用了,临时走KV集群?都不行。那个实现复杂度太高,不合适。
所以当时我们采取的方法就是,对最近一段时间用户发起的离线查询的请求日志进行收集,然后对请求日志在每天凌晨进行分析,分析出来那种每个用户会经常、多次、高频发起的冷数据查询请求,然后对这个特定的查询(比如特殊的一组条件,时间范围,维度组合)对应的结果,进行缓存。
这样就直接把各个用户高频发起的冷数据查询请求的结果每天动态分析,动态放入缓存集群中。比如有的用户每天都会看一下上周一周的数据分析结果,或者上个月一个月的数据分析结果,那么就可以把这些结果提前缓存起来。
一旦ES、HBase等集群故障,直接对外冷数据查询,仅仅提供这些提前缓存好的高频查询即可,非高频无缓存的查询结果,就是看不到了。
七、最终总结
上述系统到目前为止,已经演进到非常不错的状态了,因为这套架构已经解决了百亿流量高并发写入,海量数据存储,高性能计算,高并发查询,高可用保障,等一系列的技术挑战。线上生产系统运行非常稳定,足以应对各种生产级的问题。
其实再往后这套系统架构还可以继续演进,因为大型系统的架构演进,可以持续N多年,比如我们后面还有分布式系统全链路数据一致性保障、高稳定性工程质量保障,等等一系列的事情,不过文章就不再继续写下去了,因为文章承载内容量太少,很难写清楚所有的东西。
其实有不少同学跟我反馈说,感觉看不懂这个架构演进系列的文章,其实很正常,因为文章承载内容较少,这里有大量的细节性的技术方案和落地的实施,都没法写出来,只能写一下大型系统架构不断演进,解决各种线上技术挑战的一个过程。
我觉得对于一些年轻的同学,主要还是了解一下系统架构演进的过程,对于一些年长已经做架构设计的兄弟,应该可以启发一些思路。