一、往期回顾
上篇文章:《为什么有些看起来很厉害的技术高手,设计的架构都很垃圾?》主要聊了一下将单块系统重构为分布式系统,以此来避免单台机器的负载过高。同时引申出来了弹性资源调度、分布式容错机制等相关的东西。
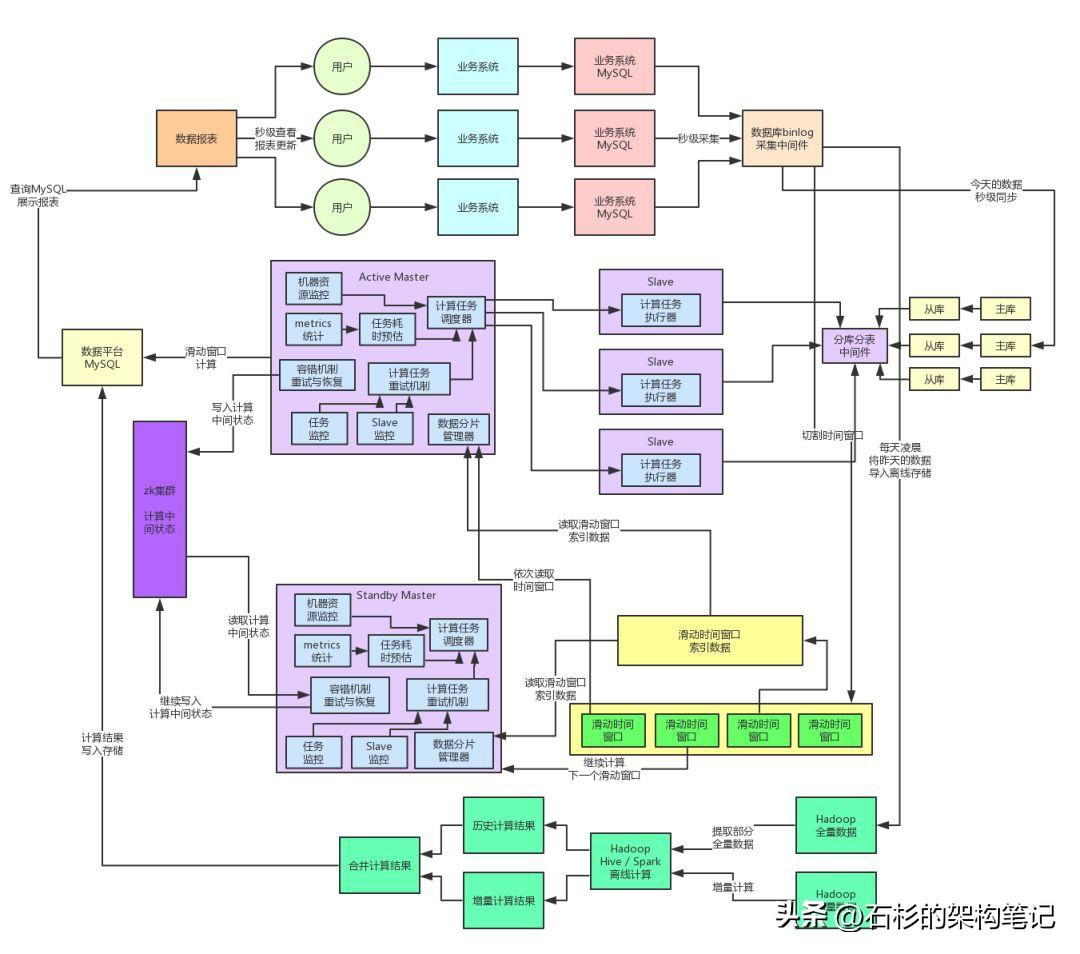
这篇文章我们继续来聊聊这个系统后续的重构演进过程,先来看下目前的系统架构图,一起来回顾一下。
二、百亿流量的高并发技术挑战
上篇文章说到,如果仅仅只是每天亿级流量的话,其实基本上目前的系统架构就足够支撑了,但是呢,我们面临的可不仅仅是亿级流量那么简单。我们面对的是日益增多和复杂的各种业务系统,我们面对的是不断增加的系统用户,我们面对的是即将迎来每天百亿级的高并发流量。
给大家先说下当时的系统部署情况,数据库那块一共部署了8主8从,也就是16台数据库服务器,每个库都是部署在独立的数据库服务器上的,而且全部用的是物理机,机器的配置,如果没记错的话,应该是32核+128G+SSD固态硬盘。
为啥要搞这么多物理机,而且全部都是高配置呢?不知道大家发现没有,目前为止,我们最大的依赖就是MySQL!
之前给大家解释过,在当时的背景下,我们要对涌入的亿级海量数据,实时的运行数百个复杂度为几百行到上千行的大SQL,几秒钟就要出分析结果。
这个是没有任何一个开源系统可以做到的,Storm不行,Spark Streaming也不行,因此必须得基于MySQL纯自研一套数据平台架构出来,支撑这个需求场景。
所以,只有MySQL是可以支撑如此复杂的SQL语句完美运行的,因此我们在早期必须严重依赖于MySQL作为数据的存储和计算,将源源不断涌入的数据放在MySQL中进行存储,接着基于数据分片计算的架构来高性能的运行复杂大SQL基于MySQL来进行计算。
所以大家就知道了,MySQL目前为止是这套系统的命脉。在当时的场景下,每台数据库服务器都要抗住每秒2000左右的并发请求,高峰期的CPU负载、IO负载其实都非常高,而且主库和从库的延迟在高峰期已经有点严重,会达到秒级了。
在我们的生产系统的实际线上运行情况下,单台MySQL数据库服务器,我们一般是不会让他的高峰期并发请求超过2000/s的,因为一旦达到每秒几千的请求,根据当时线上的资源负载情况来看,很可能MySQL服务器负载过高会宕机。
所以此时就有一个很尴尬的问题了,假如说每天亿级流量的场景下,需要用8主8从这么多高配置的数据库服务器来抗,那如果是几十亿流量呢?甚至如果是百亿流量呢?难道不停的增加更多的高配置机器吗?
要知道,这种高配置的数据库服务器,如果是物理机的话,是非常昂贵的!
之前给大家简单介绍过项目背景,这整套大型系统组成的商业级平台,涉及到N多个系统,这个数据产品只是一个子产品而已,不可能为了这么一个产品,投入大量的预算通过不停的砸高配置的机器来撑住更高的并发写入。
我们必须用技术的手段来重构系统架构,尽量用有限的机器资源,通过最优秀的架构来抗住超高的并发写入压力!
三、计算与存储分离的架构
这个架构里的致命问题之一,就是数据的存储和计算混在了一个地方,都在同一个MySQL库里!
大家想想,在一个单表里放上千万数据,然后你每次运行一个复杂SQL的时候,SQL里都是通过索引定位到表中他要计算的那个数据分片。这样搞合适吗?
答案显然是否定的!因为表里的数据量很大,但是你每次实际SQL运算只要对其中很小很小的一部分数据计算就可以了,实际上我们在生产环境中实践过后发现,如果你在一个大表运行一个复杂SQL,哪怕通过各种索引保证定位到的数据量很少,因为表数据量过大,也是会导致性能直线下降的。
因此第一件事情,先将数据的存储和计算这两件事情拆开。
我们当时的思路如下:
- 数据直接写入一个存储,仅仅只是简单的写入即可
- 然后在计算的时候从数据存储中提取你需要的那个数据分片里的可能就一两千条数据,写入另外一个专用于计算的临时表中,那个临时表内就这一两千条数据
- 然后运行你的各种复杂SQL即可。
bingo!一旦将数据存储和计算两个事情拆开,架构里可以发挥的空间就大多了。
首先你的数据存储只要支撑高并发的写入,日百亿流量的话,高峰每秒并发会达到几十万,撑住这就可以了。然后支持计算引擎通过简单的操作从数据存储里提取少量数据就OK。
太好了,这个数据存储就可以PASS掉MySQL了,就这点儿需求,你还用MySQL干什么?兄弟!
当时我们经过充分的技术调研和选型之后,选择了公司自研的分布式KV存储系统,这套KV存储系统是完全分布式的,高可用,高性能,轻量级,支持海量数据,而且之前经历过公司线上流量的百亿级请求量的考验,绝对没问题。主要支持高并发的写入数据以及简单的查询操作,完全符合我们的需求。
这里给大家提一句,其实业内很多类似场景会选择hbase,所以大家如果没有公司自研的优秀kv存储的话,可以用选用hbase也是没问题的,只不过hbase有可能生产环境会有点坑,需要大家对hbase非常精通,合理避坑和优化。
轻量级的分布式kv系统,一般设计理念都是支持一些简单的kv操作,大量的依托于内存缓存热数据来支持高并发的写入和读取,因为不需要支持MySQL里的那些事务啊、复杂SQL啊之类的重量级的机制。
因此在同等的机器资源条件下,kv存储对高并发的支撑能力至少是MySQL的数倍甚至数十倍。
就好比说,大家应该都用过Redis,Redis普通配置的单机器撑个每秒几万并发都是ok的,其实就是这个道理,他非常的轻量级,转为高并发而生。
然后,我们还是可以基于MySQL中的一些临时表来存放kv存储中提取出来的数据分片,利用MySQL对复杂SQL语法的支持来进行计算就可以了。也就是说,我们在这个架构里,把kv系统作为存储,把MySQL用做少量数据的计算。
此时我们在系统架构中引入了分布式kv系统来作为我们的数据存储,每天的海量数据都存放在这里就可以了,然后我们的Slave计算引擎每次计算,都是根据那个数据分片从kv存储中提取对应的数据出来放入MySQL内的一个临时表,接着就是对那个临时表内的一两千条数据分片运行各种复杂SQL进行计算即可。
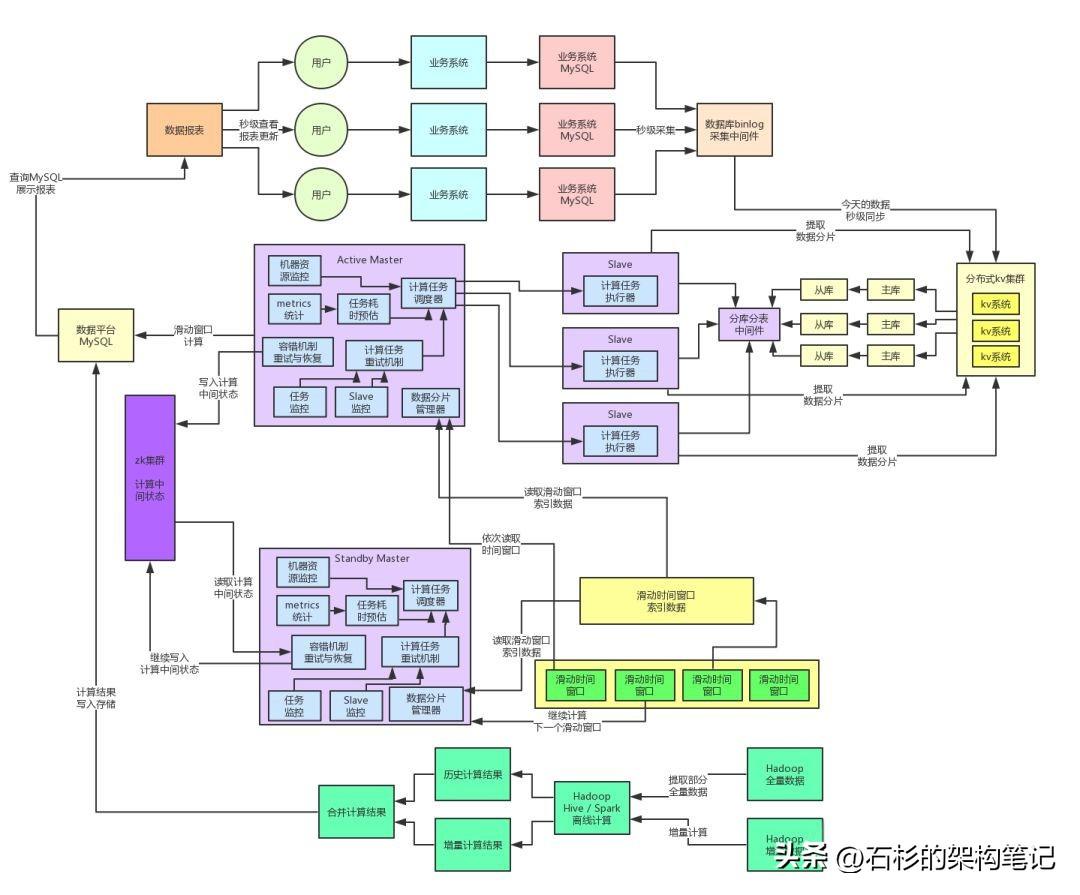
大家看上面的图,此时通过这一步计算与存储架构的分离,我们选用了适合支撑高并发的kv集群来抗住每天百亿级的流量写入。然后基于MySQL作为临时表放入少量数据来进行运算。这一个步骤就直接把高并发请求可以妥妥的抗住了。
而且分布式kv存储本来就可以按需扩容,如果并发越来越高,只要扩容增加机器就可以了。此时,就完成了架构的一个关键的重构步骤。
四、自研纯内存SQL计算引擎
下一步,我们就要对架构追求极致!因为此时我们面临的一个痛点就在于说,其实仅仅只是将MySQL作为一个临时表来计算了,主要就是用他的复杂SQL语法的支持。
但是问题是,对MySQL的并发量虽然大幅度降低了,可是还并不算太低。因为大量的数据分片要计算,还是需要频繁的读写MySQL。
此外,每次从kv存储里提取出来了数据,还得放到MySQL的临时表里,还得发送SQL去MySQL里运算,这还是多了几个步骤的时间开销。
因为当时面临的另外一个问题是,每天请求量大,意味着数据量大,数据量大意味着时间分片的计算任务负载还是较重。
总是这么依赖MySQL,还要额外维护一大堆的各种临时表,可能多达几百个临时表,你要维护,要注意他的表结构的修改,还有分库分表的一些运维操作,这一切都让依赖MySQL这个事儿显得那么的多余和麻烦。
因此,我们做出决定,为了让架构的维护性更高,而且将性能优化到极致,我们要自己研发纯内存的SQL计算引擎。
其实如果你要自研一个可以支持MySQL那么复杂SQL语法的内存SQL计算引擎,还是有点难度和麻烦的。但是在我们仔细研究了业务需要的那几百个SQL之后,发现其实问题没那么的复杂。
因为其实一般的数据分析类的SQL,主要就是一些常见的功能,没有那么多的怪、难、偏的SQL语法。
因此我们将线上的SQL都分析过一遍之后,就针对性的研发出了仅仅支持特定少数语法的SQL引擎,包括了嵌套查询组件、多表关联组件、分组聚合组件、多字段排序组件、少数几个常用函数,等等。
接着就将系统彻底重构为不再依赖MySQL,每次从kv存储中提取一个数据分片之后,直接放入内存中,然后用我们自研的SQL计算引擎来在纯内存里针对一个数据分片执行各种复杂的SQL。
这个纯内存操作的性能,那就不用多说了,大家应该都能想象到了,基本上纯内存的SQL执行,都是毫秒级的,基本上一个时间分片的运算全部降低到毫秒级了。性能进一步得到了大幅度的提升,而且从此不再依赖MySQL了,不需要维护复杂的分库分表等等东西。
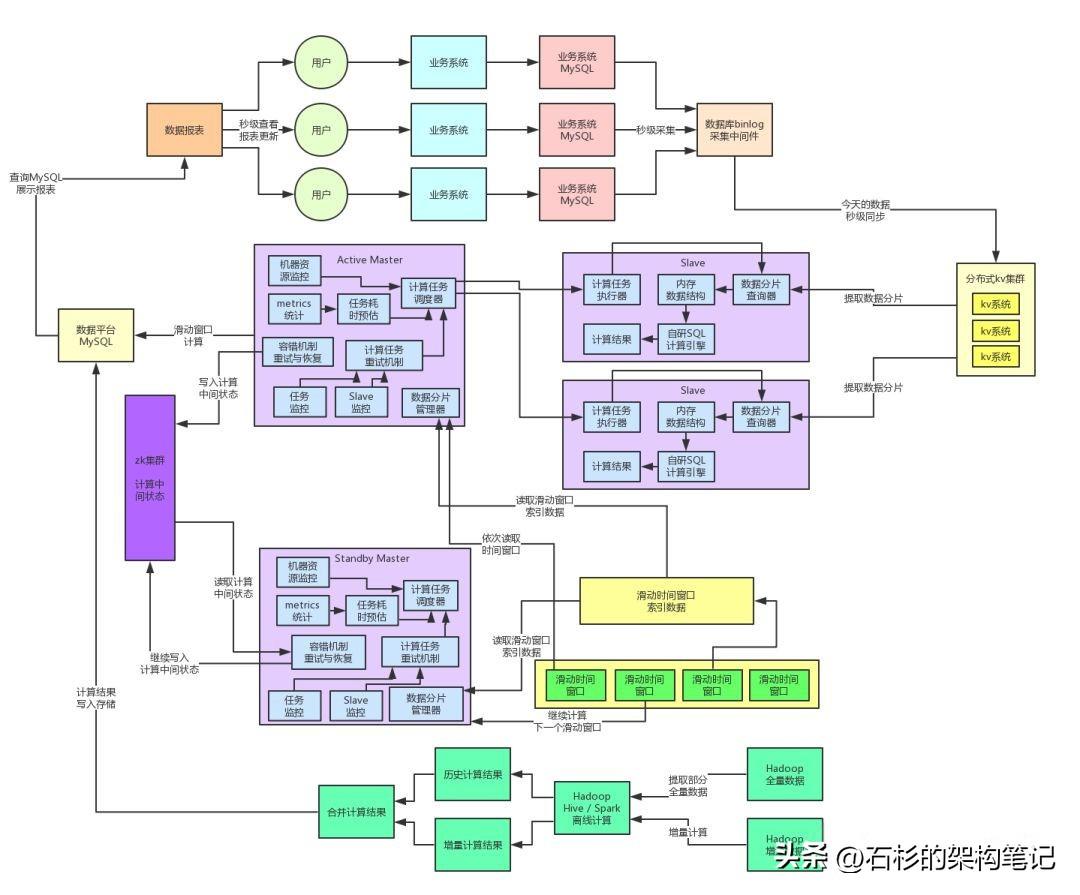
这套架构上线之后,彻底消除了对MySQL的依赖,理论上,无论多大的流量过来,都可以通过立马扩容kv集群以及扩容Slave计算集群来解决,不需要依赖MySQL的分库分表、几百张临时表等比较耗费人力、麻烦而且坑爹的方案了。而且这种纯内存的计算架构直接把计算性能提升到了毫秒级。
而且消除对MySQL的依赖有另外一个好处,数据库的机器总是要高配置的,但是Slave机器主要4核8G的普通虚拟机就够了,分布式系统的本质就是尽量利用大量的廉价普通机器就可以完成高效的存储和计算。
因此在百亿流量的负载之下,我们Slave机器部署了几十台机器就足够了,那总比你部署几十台昂贵的高配置MySQL物理机来的划算多了!
五、MQ削峰以及流量控制
其实如果对高并发架构稍微了解点的同学都会发现,这个系统的架构中,针对高并发的写入这块,还有一个比较关键的组件要加入,就是MQ。
因为我们如果应对的是高并发的非实时响应的写入请求的话,完全可以使用MQ中间件先抗住海量的请求,接着做一个中间的流量分发系统,将流量异步转发到kv存储中去,同时这个流量分发系统可以对高并发流量进行控制。
比如说如果瞬时高并发的写入真的导致后台系统压力过大,那么就可以由流量分发系统自动根据我们设定的阈值进行流量控制,避免高并发的压力打垮后台系统。
而且在这个流控系统中,我们其实还做了很多的细节性的优化,比如说数据校验、过滤无效数据、切分数据分片、数据同步的幂等机制、100%保证数据落地到kv集群的机制保障,等等。
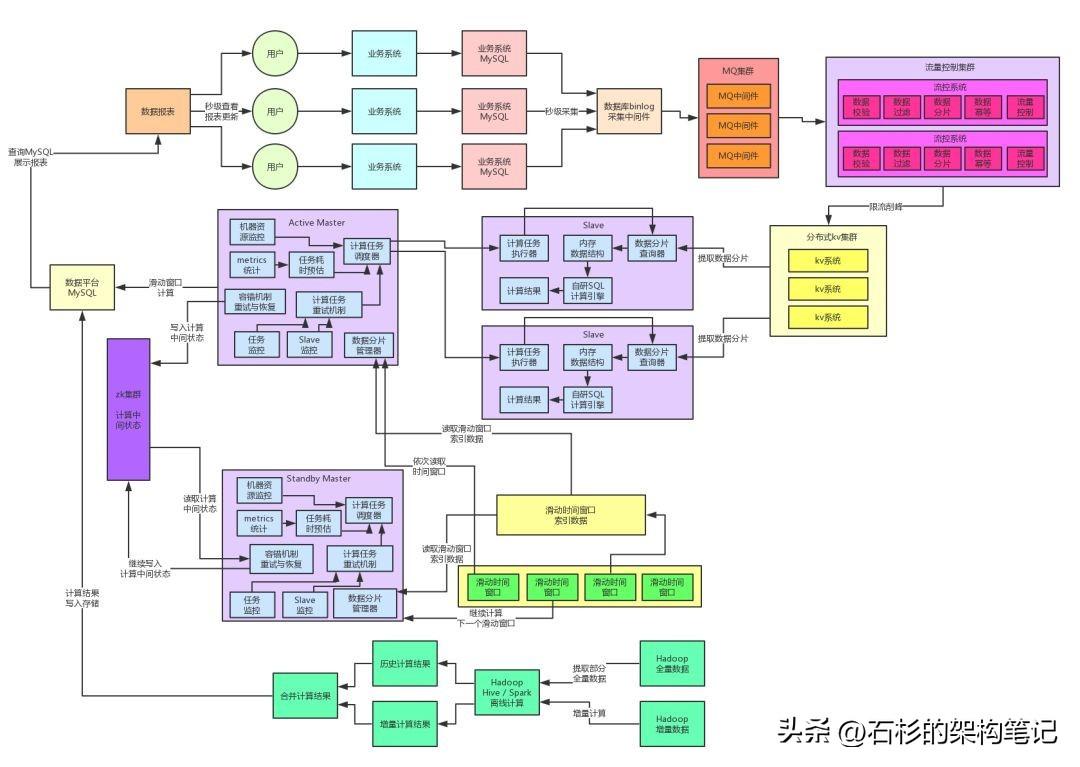
公司的MQ集群天然都支撑过大流量写入以及高并发请求,因此MQ集群那个层面抗住高并发并不是什么问题,再高的并发按需扩容就可以了,然后我们自己的流控系统也是集群部署的,线上采用的是4核8G的虚拟机,因为这个机器不需要太高的配置。
流控系统,基本线上我们一般保持在每台机器承载每秒小三千左右的并发请求,百亿流量场景下,高峰每秒并发在每秒小几十万的级别,因此这个流控集群部署到几十台机器就足够了。
而公司的kv集群也是天然支撑过大流量高并发写入的,因此kv集群按需扩容,抗住高并发带流量的写入也不是什么问题,而且这里其实我们因为在自身架构层面做了大量的优化(存储与计算分离的关键点),因此kv集群的定位基本就是online storage,一个在线存储罢了。
通过合理、巧妙的设计key以及value的数据类型,使得我们对kv集群的读写请求都是优化成最最简单的key-value的读写操作,天然保证高并发读写是没问题的。
另外稍微给大家一点点的剧透,后面讲到全链路99.99%高可用架构的时候,这个流控集群会发挥巨大的作用,他是承上启下的一个效果,前置的MQ集群故障的高可用保障,以及后置的KV集群故障的高可用保障,都是依靠流控集群来实现的。
六、数据的动静分离架构
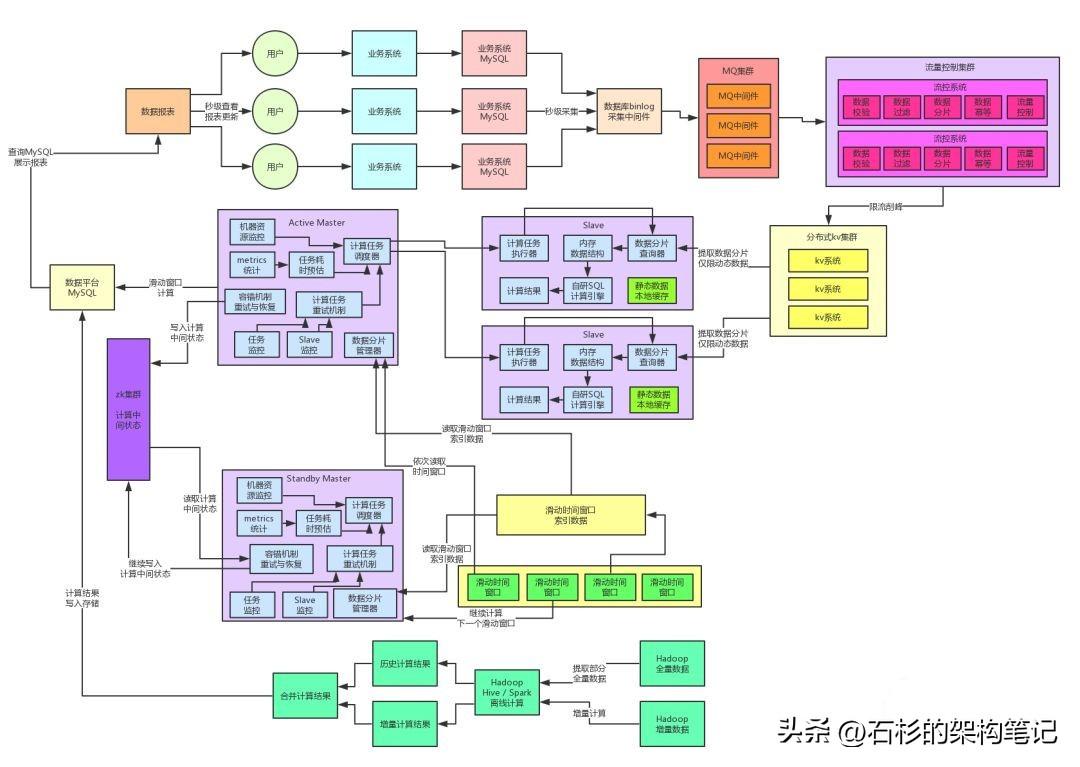
在完成上述重构之后,我们又对核心的自研内存SQL计算引擎做了进一步的优化。因为实际生产环境运行过程中,我们发现了一个问题:就是每次如果Slave节点都是对一个数据分片提取相关联的各种数据出来然后进行计算,其实是没必要的!
给大家举个例子,如果你的SQL要对一些表进行关联计算,里面涉及到了一些大部分时候静态不变的数据,那些表的数据一般很少改变,因此没必要每次都走网络请求从kv存储里提取那部分数据。
我们其实完全可以在Slave节点对这种静态数据做个轻量级的cache,然后只有数据分片里对应的动态改变的数据才从kv存储来提取数据。
通过这个数据的动静分离架构,我们基本上把Slave节点对kv集群的网络请求降低到了最少,性能提升到了最高。大家看下面的图。
七、阶段性总结
这套架构到此为止,基本上就演进的比较不错了,因为超高并发写入、极速高性能计算、按需任意扩容,等各种特性都可以支持到了,基本上从写入到计算,这两个步骤,是没什么太大的瓶颈了。
而且通过自研内存SQL计算引擎的方案,将我们的实时计算性能提升到了毫秒级的标准,基本已经达到极致。
八、下一步展望
下一步,我们就要看看这个架构中的左侧,还有一个MySQL呢!
首先是实时计算链路和离线计算链路,都会导入大量的计算结果到那个MySQL中。
其次面向数十万甚至上百万的B端商家时,如果是实时展示数据分析结果的话,一般页面上会有定时的JS脚本,每隔几秒钟就会发送请求过来加载最新的数据计算结果。
因此实际上那个专门面向终端用户的MySQL也会承受极大的数据量的压力,高并发写入的压力以及高并发查询的压力。