作者简介
Flora,携程高级研发经理,关注Node.js相关领域。
如果对跨域不太熟悉的同学,可以阅读一下MDN HTTP访问控制(CORS)这篇文章。相关概念在本文中就不再做赘述。
一、背景回顾
一个周五的下午,我们收到了一个需求,需要调整一下响应头中的Access-Control-Allow-Origin字段。这个需求的起因是什么呢?
先看一下目前的情况。针对webresource站点(后续皆以这个站点作为资源站点的代号),无论是否是跨域请求,都会返回这样的头部。见图1。

图1 请求webresource站点的响应头截图
Fig.1 Screenshot of response headers for requesting a webresource site
这个响应看上去似乎没有什么问题。
但是考虑这样一个场景:如果用户需要基于HTTP cookies和HTTP认证信息发送身份凭证,那么就需要再客户端设置一个特殊的credentials标志。例如,如果使用了fetch,那么就需要新增fetch的配置,如图2所示:

图2 fetch方法新增credentials配置
Fig.2 fetch method adds credentials configuration
再客户端调整成如上配置后,再次运行会报以下错误,见图3。
“Access to fetch at
'https://webresource.c-ctrip.com/ResUnionOnline/R1/common/marinRedirect.js?v=20220903'
from origin 'https://www.ctrip.com' has been blocked by CORS policy: The value of the 'Access-Control-Allow-Origin' header in the response must not be the wildcard '*' when the request's credentials mode is 'include'.”

图3 请求出错截图
Fig.3 Screenshot of request error
通过翻阅这篇文章(Reason: Credential is not supported if the CORS header ‘Access-Control-Allow-Origin’ is ‘*’),我们可以得到解答:
“CORS 请求发出时,已经设定了 credentials,但服务端配置了 http 响应首部 Access-Control-Allow-Origin 的值为通配符 ("*") ,而这与使用 credentials 相悖。”
所以,这才回到了本节一开始我们需要做的一个调整,将原先的Access-Control-Allow-Origin设置为具体的origin值,而非 * 星号。
再次调整之后,服务的响应头更新为图4所示:

图4 请求webresource站点的响应头截图
Fig.4 Screenshot of response headers for requesting a webresource site
二、故障现场
周五代码调整好,资源源站服务的单元测试跑通,发布到金丝雀测试,用户也反馈不报错了,变更正式发布。监控看板一切正常,就愉快的回家过周末了。
周六上午突然有开发同学截了一张图给我,说他们的应用报错了:

图5 在线故障截图
Fig.5 Screenshot of online fault
用户在https://ebooking.ctrip.com 访问了一个资源,但是这个资源响应的Access-Control-Allow-Origin的头是 https://flights.ctrip.com 。我去访问了这个页面,并未发现此类报报错。回访了一些用户,也让同事一起尝试访问,得到的反馈是一部分客户端报错,一部分客户端正常。
三、原因分析
当时我们的第一反应就是再次检查源站的逻辑更改,发现源站的Access-Control-Allow-Origin的配置代码无异常,绝对不会将Access-Control-Allow-Origin的值 origin设置错误。再次结合反馈的情况,是部分用户会报错,开始将排障方向转向CDN(Content Delivery Network)。
如果对CDN不熟悉的同学,可以阅读wikipedia CDN或者What is a CDN (Content Delivery Network)?
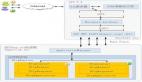
首先看这张简化的CDN结构图(图6)。目前针对webresource站点有三家CDN供应商,我们将他们称为:B供应商、W供应商和A供应商。其中B和W供应商为国内用户提供服务,他们的流量配比分别是50%和50%;A供应商为海外用户提供服务,他的流量配比是100%。
当一个国内用户请求某个webresource站点的资源时,他有可能会被分配到B、有可能分配到W。B或者W都会有概率(如果CDN节点命中失败的话),就会请求到资源源站服务。

图6 简化的CDN结构图
Fig.6 Simplified CDN Structure Diagram
由于客户端的反馈是部分正确部分异常,所以推测是CDN供应商可能某一家有异常或者某个节点有异常。于是再次绑定B供应商和W供应商的服务器节点进行测试,均设置请求头中的Origin为https://ebooking.ctrip.com。
我们得到了如下的结果:
1)B供应商响应的内容和源站响应的内容保持一致,如图7所示。

图7 B供应商的响应体截图
Fig.7 Screenshot of response body for B supplier
2)W供应商响应的内容与源站有2个响应头不一致,如图8所示。

图8 W供应商的响应体截图
Fig.8 Screenshot of response body for W supplier
第一个不一致是Access-Control-Allow-Origin不是源站,第二个不一致是缺少了Vary的头部。细心的同学通过“图4 请求webresource站点的响应头截图”,可以看到,源站是有设置Vary头部为“Origin, Accept-Encoding”,见图9。要知道,一旦缺少了这个头部,就无法标识要基于Origin做协商缓存。
对Vary不熟悉的同学,可以参看HTTP Vary。
“Vary 是一个 HTTP 响应头部信息,它决定了对于未来的一个请求头,应该用一个缓存的回复 (response) 还是向源服务器请求一个新的回复。它被服务器用来表明在 content negotiation algorithm(内容协商算法)中选择一个资源代表的时候应该使用哪些头部信息(headers).”
如果Vary字段中有Origin,那么简单理解可以是基于Origin+URL做缓存。当Origin不一样的时候,就需要做头部信息的更新。同理,比如一些特殊文件polyfill,是需要基于浏览器做一些处理的,那么就可以设置将User-Agent设置到Vary中,这样就会针对同一个文件,基于User-Agent做缓存。

图9 请求webresource站点的响应头截图
Fig.9 Screenshot of response headers for requesting a webresource site
至此问题基本定位到:
当两个不同的Origin(主站点)跨域请求同一个资源的时候,由于W供应商并没有根据资源服务返回的响应,正确配置CDN缓存头部,这样会导致返回的Access-Control-Allow-Origin值错乱。
四、故障解决
解决在线故障第一要素是快速响应。所以我们将国内CDN配比从原先的各50%,更改成B供应商100%,保证客户端的响应正常。
接着联系W供应商,当我们认为是供应商的一个严重的bug时,供应商的答复是:
①请求Origin: http://ebooking.ctrip.com 缓存下来后(其对应的Etag为W/"D96CF9DBB3B578CC1721941E799BE22D"),由于源站响应了Vary: origin, accept-encoding,走入到了Vary缓存的逻辑中;
②再请求Origin: http://a.ctrip.com,由于走入到Vary缓存的逻辑,且VaryData没有匹配到http://a.ctrip.com,则走入到Vary miss的逻辑中,miss回上层的时候带了If-None-Match: W/"D96CF9DBB3B578CC1721941E799BE22D",此次回上层带的Origin是http://a.ctrip.com,但由于带了If-None-Match,且源站不同Origin的Etag值是相同的。所以响应了304,这时候就会直接复用Origin: http://ebooking.ctrip.com的响应了,也就会用到Origin: http://ebooking.ctrip.com响应的Access-Control-Allow-Origin头部了”
这里W供应商这里有一个致命的逻辑错误:当用If-None-Match请求源站时,源站返回了304。这代表body没有改变,但同时源站返回了正确的Access-Control-Allow-Origin的头给到CDN。然而CDN并没有替换源站给到的头,而是直接读取一个缓存中错误的头。
虽然我们源站遵循了HTTP的标准,但是CDN没有遵循,导致返回给用户的响应头出错了。

图10 304请求也需要响应Vary头
Fig.10 304 requests also need to respond to the Vary header
经过一番沟通,W供应商答应可以将这个逻辑做一个配置,规避出错的问题。但是需要按照资源域名逐一配置,也就是配置白名单的方式。
所以最终的解决方案是给到W供应商一批资源域名列表,让供应商做手动配置。且需要记住每一次新增一个资源域名都要同步到W供应商。
五、经验总结
经过这次的故障,我们有如下总结:
1)测试完整性:资源源站站点的每次更新发布,除了需要验证自身应用的正确性,也需要将每个CDN供应商进行逐一的集成测试。因为不知道哪一个环节或者哪个配置可能会踩到坑。
2)开发标准性:无论我们的上游是怎么处理的,资源源站服务的开发一定要遵循HTTP标准。只有参照标准,才能进行有秩序的治理。HTTP是一份需要经常拿来阅读的文档。
3)资源的唯一性:在引用静态资源时,尽量保证资源URL的唯一性,例如可以用md5来标识文件。这样的好处是,当这个资源出现一些不可预期的故障时,可以及时升级文件来达到快速刷新客户端请求内容的效果,而不是依靠缓存清理工具。
一方面是因为每个CDN供应商purge(清理缓存)的机制不一样,而且没有一个治理工具可以获悉是否每个CDN节点的缓存正确purge了。我想也许“缓存清理成功率”这个指标并未写到CDN供应商的交付指标中。
另一个方面是还有一些未可知的缓存节点,例如客户端的缓存,又例如在某个酒店内部使用的系统,有可能酒店内部网络存在缓存。
我们曾经发生过无论如何执行CDN侧的缓存清理脚本,客户端都无法拿到新的资源。与CDN供应商排查了许久未果,最终迫不得已还是修改了引用的URL地址(例如加一个query字段,虽然不优雅,但至少能暂时解决问题)。所以保证资源的唯一性还是很有必要的。
最后还想说一句,如果可以实现统一各CDN供应商的标准,那该是件多么美好的事情。
再经过一番深入了解后知悉,某些CDN供应商的设计初衷是直接对接存储,而非一个静态源站服务。而一些头部的配置是直接放在CDN供应商的控制面板中做配置。例如默认不会开启Vary这些的配置,是为了提升缓存效率。