哈喽,大家好。
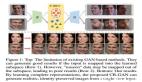
最近大家都在玩 AI 绘画,我在 GitHub 上找了一个开源项目,给大家分享一下。

今天分享的这个项目是用 GAN 生成对抗网络实现的,关于GAN的原理和实战我们之前分享过很多文章,想了解的朋友可以去翻历史文章。
源码和数据集文末获取,下面分享如何训练、运行项目。
1. 准备环境
安装 tensorflow-gpu 1.15.0,GPU显卡使用2080Ti,cuda版本10.0。
git下载项目AnimeGANv2源码。
搭建好环境后,还需要准备数据集和vgg19。

下载dataset.zip压缩文件,里面包含 6k 张真实图片和2k张漫画图片,用于GAN的训练。

vgg19是用来计算损失的,下面会有详细介绍。
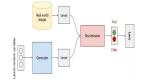
2. 网络模型
生成对抗网络需要定义两个模型,一个是生成器,一个是判别器。
生成器网络定义如下:
with tf.variable_scope('A'):
inputs = Conv2DNormLReLU(inputs, 32, 7)
inputs = Conv2DNormLReLU(inputs, 64, strides=2)
inputs = Conv2DNormLReLU(inputs, 64)
with tf.variable_scope('B'):
inputs = Conv2DNormLReLU(inputs, 128, strides=2)
inputs = Conv2DNormLReLU(inputs, 128)
with tf.variable_scope('C'):
inputs = Conv2DNormLReLU(inputs, 128)
inputs = self.InvertedRes_block(inputs, 2, 256, 1, 'r1')
inputs = self.InvertedRes_block(inputs, 2, 256, 1, 'r2')
inputs = self.InvertedRes_block(inputs, 2, 256, 1, 'r3')
inputs = self.InvertedRes_block(inputs, 2, 256, 1, 'r4')
inputs = Conv2DNormLReLU(inputs, 128)
with tf.variable_scope('D'):
inputs = Unsample(inputs, 128)
inputs = Conv2DNormLReLU(inputs, 128)
with tf.variable_scope('E'):
inputs = Unsample(inputs,64)
inputs = Conv2DNormLReLU(inputs, 64)
inputs = Conv2DNormLReLU(inputs, 32, 7)
with tf.variable_scope('out_layer'):
out = Conv2D(inputs, filters =3, kernel_size=1, strides=1)
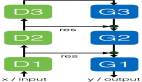
self.fake = tf.tanh(out)生成器中主要的模块是反向残差块

残差结构(a)和反向残差块(b)
判别器网络结构如下:
def D_net(x_init,ch, n_dis,sn, scope, reuse):
channel = ch // 2
with tf.variable_scope(scope, reuse=reuse):
x = conv(x_init, channel, kernel=3, stride=1, pad=1, use_bias=False, sn=sn, scope='conv_0')
x = lrelu(x, 0.2)
for i in range(1, n_dis):
x = conv(x, channel * 2, kernel=3, stride=2, pad=1, use_bias=False, sn=sn, scope='conv_s2_' + str(i))
x = lrelu(x, 0.2)
x = conv(x, channel * 4, kernel=3, stride=1, pad=1, use_bias=False, sn=sn, scope='conv_s1_' + str(i))
x = layer_norm(x, scope='1_norm_' + str(i))
x = lrelu(x, 0.2)
channel = channel * 2
x = conv(x, channel * 2, kernel=3, stride=1, pad=1, use_bias=False, sn=sn, scope='last_conv')
x = layer_norm(x, scope='2_ins_norm')
x = lrelu(x, 0.2)
x = conv(x, channels=1, kernel=3, stride=1, pad=1, use_bias=False, sn=sn, scope='D_logit')
return x
3. 损失
计算损失之前先用VGG19网路将图片向量化。这个过程有点像NLP中的Embedding操作。
Eembedding是讲词转化成向量,VGG19是讲图片转化成向量。

VGG19定义
计算损失部分逻辑如下:
def con_sty_loss(vgg, real, anime, fake):
# 真实图片向量化
vgg.build(real)
real_feature_map = vgg.conv4_4_no_activation
# 生成图片向量化
vgg.build(fake)
fake_feature_map = vgg.conv4_4_no_activation
# 漫画风格向量化
vgg.build(anime[:fake_feature_map.shape[0]])
anime_feature_map = vgg.conv4_4_no_activation
# 真实图片与生成图片的损失
c_loss = L1_loss(real_feature_map, fake_feature_map)
# 漫画风格与生成图片的损失
s_loss = style_loss(anime_feature_map, fake_feature_map)
return c_loss, s_loss
这里使用vgg19分别计算真实图片(参数real)与生成的图片(参数fake)的损失,生成的图片(参数fake)与漫画风格(参数anime)的损失。
c_loss, s_loss = con_sty_loss(self.vgg, self.real, self.anime_gray, self.generated)
t_loss = self.con_weight * c_loss + self.sty_weight * s_loss + color_loss(self.real,self.generated) * self.color_weight + tv_loss
最终给这两个损失不同的权重,这样是的生成器生成的图片,既保留了真实图片的样子,又向漫画风格进行迁移
4. 训练
在项目目录下执行以下命令开始训练
python train.py --dataset Hayao --epoch 101 --init_epoch 10
运行成功后,可以看到一下数据。

同时,也可以看到损失在不断下降。
源码和数据集都已经打包好了,需要的朋友评论区留言即可。
如果大家觉得本文对你有用就点个 在看 鼓励一下吧,后续我会持续分享优秀的 Python+AI 项目。