一、前言
我们在开发或者面试的过程中经常会涉及到索引。今天我们来详细剖析一下索引常用的知识点。首先我们先介绍mysql的常用的存储引擎,其次是索引分类。
二、索引分类
MySQL 的索引有两种分类方式:逻辑分类和物理分类
三、逻辑分类
有多种逻辑划分的方式,比如按功能划分,按组成索引的列数划分等
3.1、功能划分
主键索引:一张表只能有一个主键索引,不允许重复、不允许为 NULL
主键索引:一张表只能有一个主键索引,不允许重复、不允许为 NULL
唯一索引:数据列不允许重复,允许为 NULL 值,一张表可有多个唯一索引,索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一
普通索引:一张表可以创建多个普通索引,一个普通索引可以包含多个字段,允许数据重复,允许 NULL 值插入;
全文索引:它查找的是文本中的关键词,主要用于全文检索
按列数划分
单列索引:一个索引只包含一个列,一个表可以有多个单例索引。
组合索引:一个组合索引包含两个或两个以上的列。查询的时候遵循 最左前缀原则
3.2、物理分类(重点)
聚簇索引
将数据存储与索引放到了一块,找到索引也就找到了数据
非聚簇索引
将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置
四、不同存储引擎中索引落盘的差异
存储引擎
MyISAM:
- *.frm:与表相关的元数据信息都存放在frm文件,包括表结构的定义信息等
- *.MYD:MyISAM DATA,用于存储MyISAM表的数据
- *.MYI:MyISAM INDEX,用于存储MyISAM表的索引相关信息
InnoDB:
- *.frm:与表相关的元数据信息都存放在frm文件,包括表结构的定义信息等
- *.ibd:InnoDB DATA,表数据和索引的文件。该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据
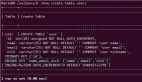
五、假设用户(t_user)如下
id | name | gender | phone |
1 | Qin | 1 | 181** |
2 | Jac | 0 | 125** |
3 | Jam | 1 | 199** |
4 | Mic | 1 | 185** |
5 | Tom | 1 | 147** |
6 | Sev | 0 | 186** |
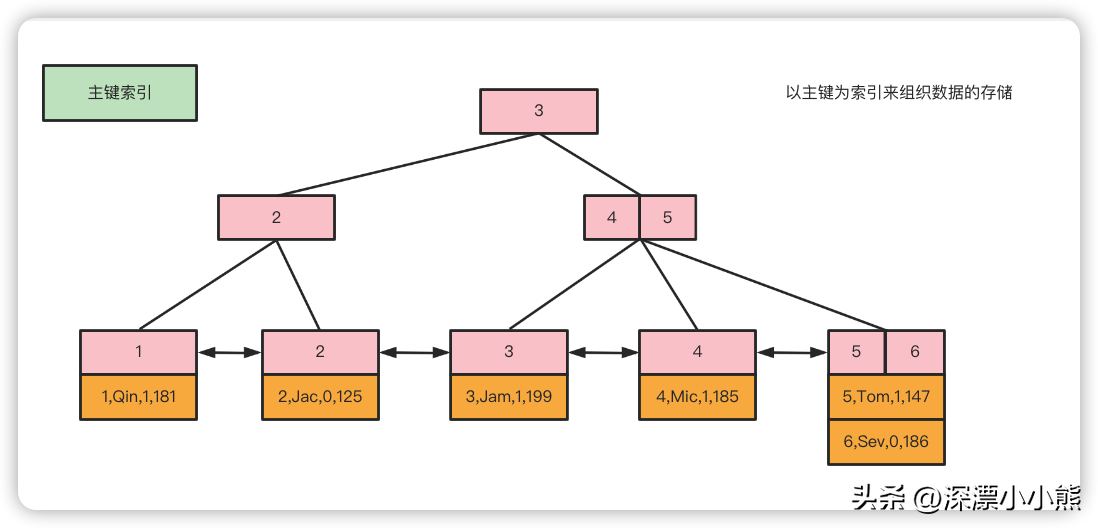
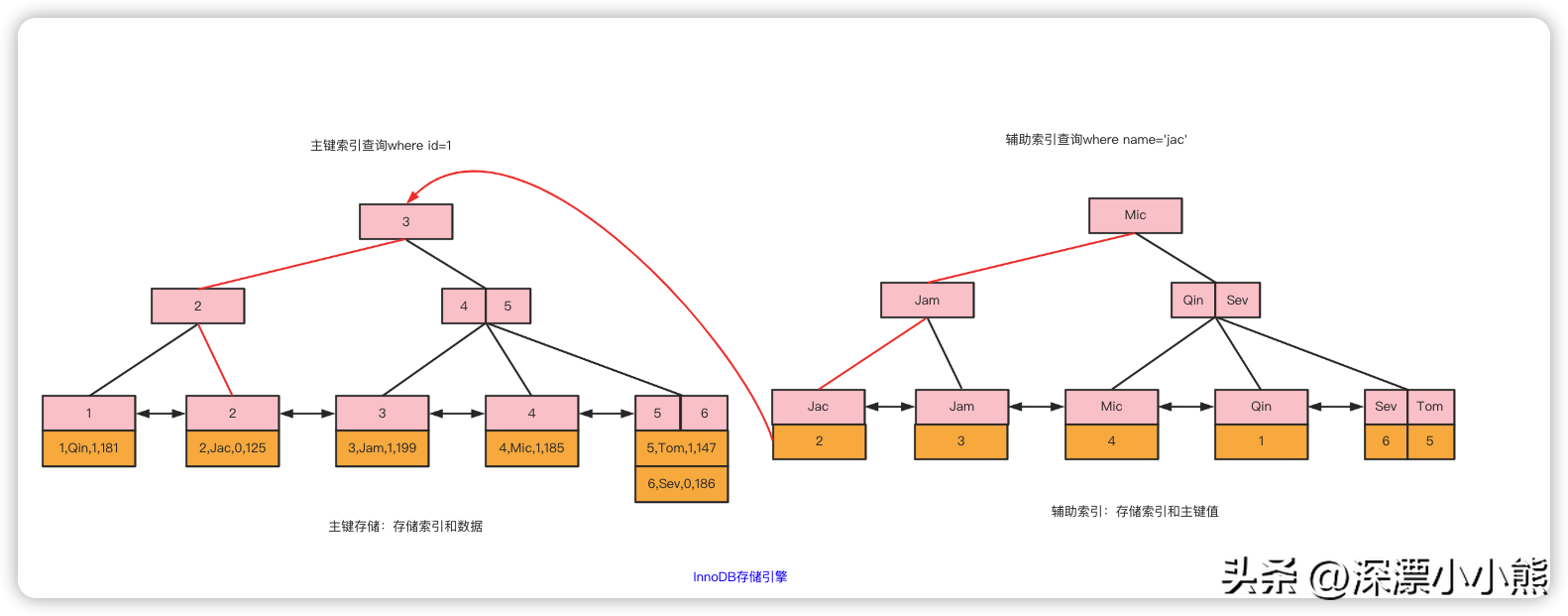
六、聚集索引 (又叫聚簇索引)
主键索引
InnoDB只有一个文件(.ibd文件),那索引放在哪里呢?在InnoDB 里面,它是以主键为索引来组织数据的存储的,所以索引文件和数据文件是同一个文件,都在.ibd文件里面。在InnoDB的主键索引的叶子节点上,它直接存储了我们的数据。
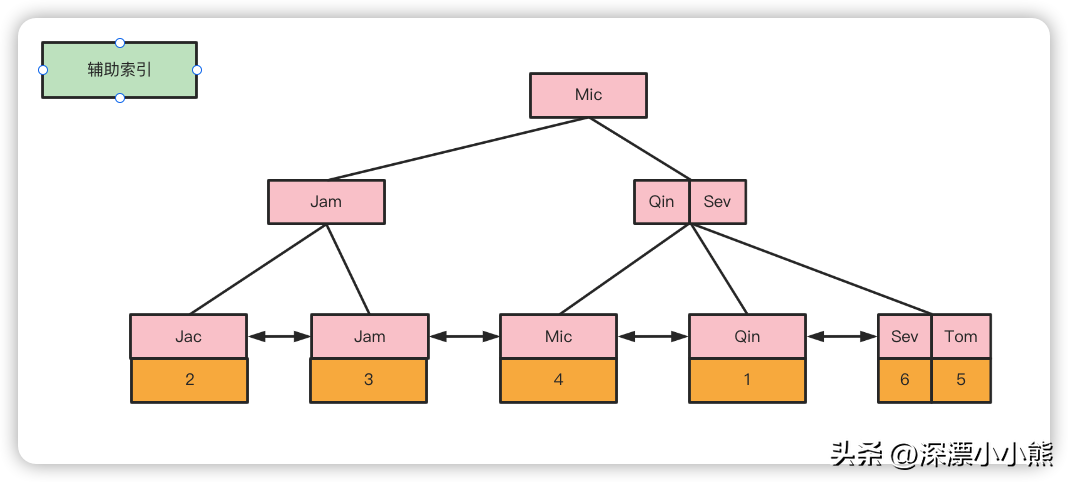
辅助索引
假设在NAME列上创建一个索引,那name的索引B+ tree 如下
查询IO图形化表示如下:
主键索引与辅助索引配合查询
非聚集索引
主键索引
非聚集索引在叶节点上有一个“指针”直接指向要查询的数据区域
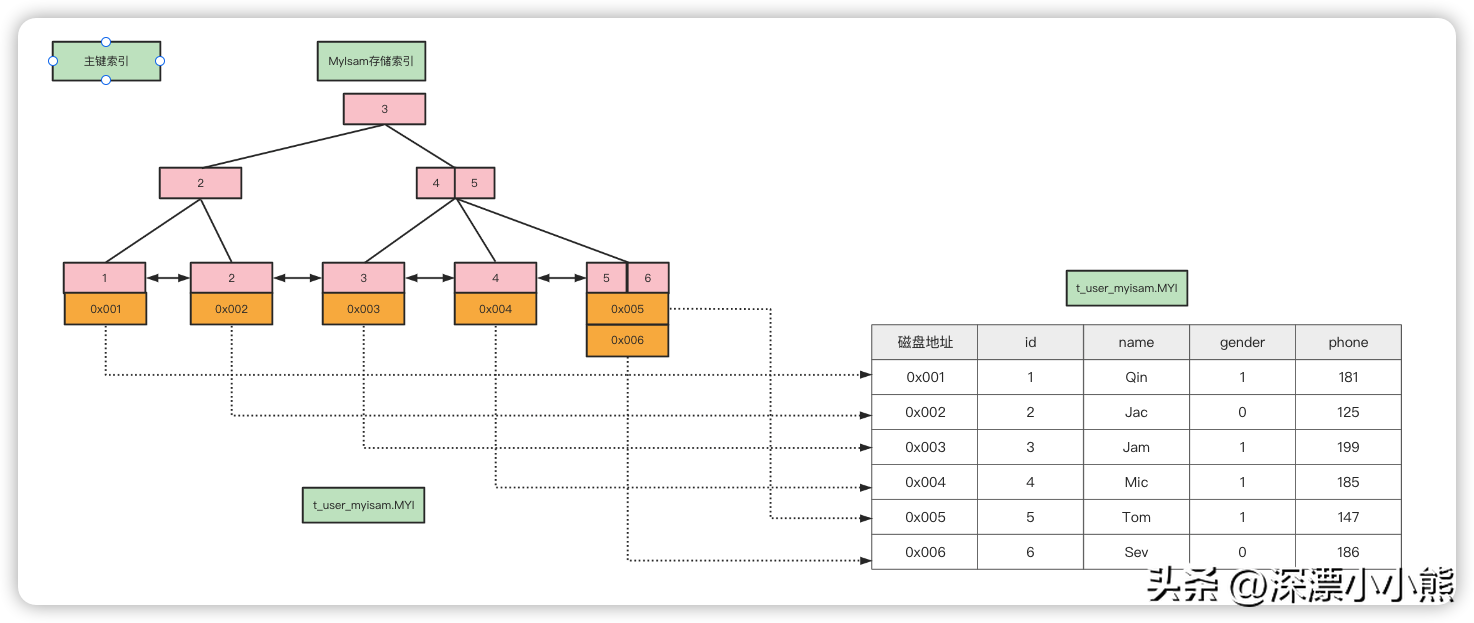
辅助索引
在MyISAM里面,辅助索引也在这个.MYI文件里面。辅助索引跟主键索引存储和检索数据的方式是没有任何区别的,一样是在索引文件里面找到磁盘地址,然后到数据文件里面获取数据。