有在用,但是大多是 logback 和 log4j 2.x。虽然异步日志的效率 logback 和 log4j 2.x 相差无几,但 log4j 2.x 仍有些微弱的优势。
日志接口框架
可以看到,Java 中是存在多种不同日志框架的实现的,这就会造成 2 个问题:
多框架协作:在一个项目中,不光有你的代码,还有各种各样的框架代码,比如分布式协调会用到 Zookeeper、Curator;RPC 通信会用到 Dubbo、Thrift。为了方便开发,业务系统中往往集成了许多第三方框架。我们需要日志来了解各个第三方框架之间的协作状态,这些第三方框架又依赖于各个日志框架进行输出。这时候如果直接使用像 logback、log4j 这样的日志框架,岂不是业务系统要接入每个日志框架?
不同框架竞争:如果要引入多个日志框架,我们还需要考虑各个框架的输出位置。要是多个日志框架同时写入一个日志文件,还会涉及竞争问题,导致性能无法发挥。
由此就出现了面向接口的日志框架,它提供了统一的 API。开发人员在编写代码的时候,直接使用这套面向接口的日志框架,当业务项目人员在使用时,只需要选择好实现框架,就可以统一日志实现框架。

目前使用最为广泛的日志接口框架是 SLF4J,出自 logback 的开发者,目前基本已经形成规范。SLF4J 提供了动态占位符的功能,大大提高了程序的性能,无须开发人员再对参数信息进行拼接。
比如默认情况下程序是 info 级别的,在原先的代码方式中想要进行日志输出需要自行拼接字符串:
这会产生一个问题,系统中如果存在大量类似的代码,同时系统只输出 info 及 info 以上级别的日志,那么,在输出 debug 日志时会产生大量的字符串,而并不会输出 debug 日志,最后造成字符串不停地拼接,浪费系统性能。此时,SLF4J 就可以使用占位符的功能编写日志,比如像下面这样:
通过这样的形式,SLF4J 就可以根据日志等级判断,只对符合要求的日志进行数据拼接和打印。
有些时候日志输出需要进行数值计算,或者 JSON 转换,此时就需要一定的计算任务。但方法调用如果被当作参数传递的话一样会被执行,所以 Java8 中 SLF4J 还可以通过 Supplier 来传递。如下所示:
可以看到,SLF4J 不仅为我们制定了一套面向接口开发的方式,还为我们明确了如何有效地编写日志。这也是为什么越来越多人喜欢用 SLF4J。
日志编写方式
在详细介绍了我们在开发时需要使用的日志框架后,我将正式展开我们的标题:“如何编写‘可观测’的日志?”我会从日志编写位置、写入性能、占位符、可读性、关键信息隐蔽、减少代码位置信息的输出、文件分类、和日志 review 这 8 个点来讲解,并将它们分成了 2 个方向:
日志开发时(前 5 项):怎么样写出更有效率的日志?
日志完成后(后 3 项):上线前后有哪些需要注意的?
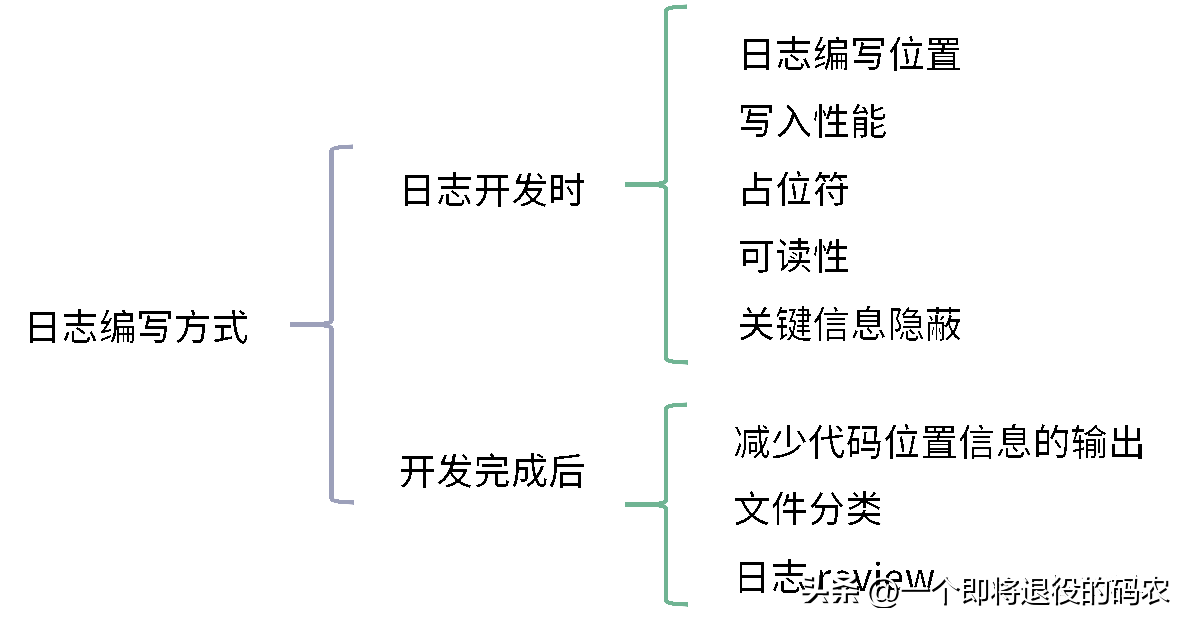
日志编写位置
日志编写的位置可以说是重中之重,好的日志位置可以帮你解决问题,也可以让你更加了解代码的运行情况。我总结了几点比较重要的编写日志的位置,以供参考。
系统/应用启动和参数变更:当系统启动时,可以将相关的参数信息进行打印,以便出现问题时,更准确地查询原因;参数信息可能并不存储在本地,需要通过配置中心获取,而参数信息有变更时,也需要将变更后的内容输出在日志中。
关键操作节点:最典型的就是在关键位置添加日志,记录用户进行的某个操作。当出现问题时,你可以通过这个位置的日志了解到用户的操作。同样你也可以在系统进行某些操作时添加日志,比如你准备启动某个线程池来进行数据处理时,可以加上日志便于以后分析问题。
大型任务进度上报:当系统在处理某个比较大型的任务时,可以在这个过程中增加相关的日志来表明任务处理的进度,防止因为长时间没有处理而无法得知程序执行的状态,比如在文件下载时,可以按照百分比来定时/定次地上报数据。
异常:当程序出现异常时,我们通常是通过 try-catch 来记录当时的情况,然后以日志的形式表现出来。如果是通过 try-catch 处理,你需要注意日志编写的位置。如果你需要将日志在本层抛出,则不需要进行日志记录,否则会出现日志重复的问题。如果你除了异常以外还需要记录其他的内容,则可以通过定制异常信息来实现。
写入性能
日志的写入性能则会受到如下 5 个因素的影响:
日志编写位置:日志编写的位置在程序中十分重要,如果在 for 循环中编写,因为这个循环会持续很多次,那么就会产生大量的日志记录。此时可以考虑一下,这个日志的记录是否有必要。
日志数量:如果你大量地编写日志,那么日志的质量一定会降低。同时,大量的日志会让你很难去查看问题,反而成了一种负担。在高访问量时,过多的日志也会影响程序的执行效率。
日志编写等级:我在上一节中讲过,日志等级很容易被滥用,不正确的日志等级会导致我们查询问题的时间增加。
日志输出级别:这里指的是对于配置日志输出级别的选择。在线上环境,不建议使用 debug 级别,因为线上一直有请求,debug 级别会输出大量的基础和请求信息,极其浪费资源,因此建议开启 info 或者以上。
无用输出参数:不对大字段、无用字段输出,因为这很影响程序执行效率和日志的内容。我曾遇到一个案例,A 同学在线上打印了一个完整的 HTML 内容,导致当日的部分日志内容错乱,部分日志无法检索,原因就在于 HTML 存在多行内容导致无法解析的问题。当开发人员到线上服务器上查看时,日志文件的大小已经扩大了 3 倍。
好的日志一定是便于你去排查问题的。在编写日志时你一定要思考这个日志可以帮你做什么。
占位符
在介绍日志接口框架时我提到过,在日志编写时尽可能地选择基于占位符的编写方式。这里我会告诉你为什么要用占位符:
- 节约性能。在生成较高级别的日志时,低级别的日志会不停叠加字符串而占用过多的内存、CPU 资源,导致性能浪费。
- 便于编写。先确认日志所想要表达的内容,再确认你所需要编写的参数,这样在写日志时,目的也会更加明确。
- 便于查看。在代码 review 时,更方便查看日志想表达的意思,而不会被日志的参数打乱。
可读性
日志的可读性也是日志编写的关键之一。一个好的日志就像一篇好的文章,能让你很快了解到这个日志中的关键信息。我在工作中发现很多人写的日志都是无意义的,根本无法帮你定位问题的根源,比如像下面的这段代码:
这段代码乍一看似乎没什么问题,但是运行后系统会大量地输出“数据保存成功!”的消息,这个输出和没有是一样的,起不到任何的作用。
我总结了几点在日志中容易遗漏的信息:
- 会话标识:当前操作的用户和与当前请求相关的信息,类似 Session。当出现问题/查看行为时,可以根据这个值来快速识别到相关的日志。
- 请求标识:每个请求都拥有一个唯一的标识,这样在查看问题时,我们只需要查看这一个请求中的所有日志即可。一般我们会配合链路追踪系统一同使用,因为后者可以实现跨应用的日志追踪,从而帮助我们过滤掉不相关的信息。
- 参数信息:在日志中增加参数信息能帮你了解到,是什么情况下产生的问题,这样你也很容易复现问题,以及辨别错误的原因。
- 发生数据的结果:和参数信息相互对应,一个是执行前,一个是执行后。发生数据的结果可以帮你了解程序执行的结果,出错时也是很重要的参考条件。
关键信息隐蔽
对于关键的信息不显示或者进行掩码显示,以免信息被盗取后出现数据内容泄漏。推特在 2018 年曾将用户打印在日志中,这一行为泄露了 3.3 亿人。
减少代码位置信息的输出
如果不是必要,尽量不要在日志格式中输出当前日志所在的代码行和方法名称信息。如果你看过 logback,log4j 的源码你就知道,这都是通过获取当前线程堆栈快照信息来进行实现的,这种实现方式会极大地影响程序执行的效率。
在 log4j 的文档中有这样一段话:“使用同步方式进行获取位置信息会慢 1.3 到 5 倍,如果是使用异步日志,因为会涉及跨线程获取位置信息,会慢 30 到 100 倍。原文:https://logging.apache.org/log4j/2.0/manual/async.html#Location。
所以,关闭代码位置信息的输出可以节省系统资源的使用,提升性能。
文件分类
文件分类可以帮助你提高检索日志信息时的效率。将不同的业务逻辑按照不同的日志文件来分类,可以保证你看到的信息都是和这个功能相关的,不会被其他的日志干扰。这也是在大型系统中经常会使用到的功能。
比如拉勾的单点登录系统,就会将用户的极验验证功能和登录验证功能拆成两个单独的日志文件,当出现问题时,可以根据相关功能的日志来快速筛查问题,减少了筛选所需的时间。
日志 review
每一次功能上线后,除了要对业务功能进行回归,还要对日志进行观察,确认日志内容的输出情况,比如日志内容是否符合预期,会不会有不合适的地方?
好的日志不是一次就能写好的,一定是要和代码一样不停地迭代,才能写出更方便处理问题,也更具有可读性的日志。
日志管理
就像店家在卖出商品后还要负责其售后,编写完日志,对于它的管理也是十分重要的。好的日志管理方式可以提高阅读日志的效率,而这需要开发人员和运维人员共同协作。
日志格式
日志的格式布局会影响运维人员将这些日志内容收集与管理的效率。如果编写者和管理者能够通过协商,规定出一套完整的日志格式,这样就能在排查问题时事半功倍。
我会简单介绍几点在日志编写时需要注意的事项:
- 系统之间格式保持一致:每个应用在日志格式上尽量保持统一,这样,运维人员在进行日志收集时,就可以采用统一的日志模板来收集和格式化内容,减少双方的沟通成本。
- 不编写多行的日志内容:除了异常堆栈信息,不对日志内容进行多行的输出,多行的内容十分不便于数据解析,可能会出现生成多条日志的情况。
- 不要使用日志中的常见内容来分割:如果采用日志中常见的内容来分割,会在格式解析时出现问题,比如用户 ID 中的空格就是比较常见的内容。
日志归档
日志归档是一件很重要的事情。如果你将日志内容全部写到一个文件中,这个日志文件会变得越来越烦冗,不利于日志的收集和查看。
一般情况下,我们会对日志按照日期来归档,每天生成一个日志文件,这样在日志备份和恢复时,可以按照日期来进行。如果感觉天级别的日志仍然太大了,可以考虑按照小时细分。
结语
今天我们了解了日志编写的工具、日志编写需要注意的 8 个事项以及日志管理的方式,有哪些是你原来犯过的错误,又有哪些是你原来没有想到的呢?欢迎你在留言区分享与讨论。希望你在日后的日志编写中可以注意到这些问题。