1、背景
最近用到了向量搜索,所以要对milvus进行压测。同时为了更加深入分析压测中遇到的问题,也对milvus的部分源码与文档进行了走读。其中遇到了一些问题与疑惑,我们也直接与milvus社区或开源贡献者沟通。
通过压测,我们发现某场景下存在milvus的性能提升不上去的问题,并给出基于该场景的解决方案,社区反馈给milvus官方。
以下为milvus的设计与压测中遇到的一些问题与解决或跟进方案。
2、向量搜索与milvus
2.1 向量搜索
向量搜索简称ANNS,英文全名:Approximate Nearest Neighbor Search 。大致概念是从一堆向量中找出与某个目标向量距离最近的N个向量。最简单粗暴的搜索方式是暴力搜索,但是可以通过扩增索引的方式加快搜索速度,提升大规模查询的QPS。
当前的向量索引可以分为四大类:基于树的索引、基于图的索引、基于哈希的索引、基于量化的索引。其中图思路由于较高的召回率、较好的性能和较多的后期优化思路,脱颖而出。
2.2 milvus
milvus(主要针对2.0以上版本)是一款元原生向量数据库,支持向量的插入,ANNS搜索等。Milvus能够很好地应对海量向量数据,它集成了目前在向量相似性计算领域比较知名的几个开源库(Faiss, SPTAG等),通过对数据和硬件算力的合理调度,以获得最优的搜索性能。
官网:https://milvus.io/
3、milvus架构介绍
3.1 milvus的数据集概念
数据集概念:

- collection: 数据集,类似于mysql的表。
- channel:基于主键把数据集细分为很多channel,在数据写入与查询时,对应与msg borker中的通道的概念。
- partion:partion把数据集进行了一层划分,常见的partion,比如:日期,按照日期分类存储数据。partion与channel是正交的关系。
- segment:milvus数据集的最小单位,具体的索引都是基于segment去构建的。查询的最小单位也是segment。
官网给出数据集读取写入例子:https://milvus.io/docs/v2.1.x/example_code.md
数据集查询工具:https://github.com/milvus-io/birdwatcher
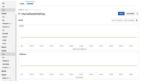
以下利用birdwatcher展示collection与segment信息:


以上输出结果,对该工具进行了改造。
具体一个segment在etcd中所有的信息:
 、
、
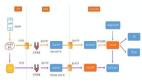
3.2 milvus架构图
milvus官网给出的架构图如下:

按照分组又可以分为以下几大类别:

简单介绍下以上各个微服务的功能:
- 系统门面:
- Proxy:所有SDK查询都会经过proxy,proxy会把写数据投递到message borker中对应不同的channel,proxy会处理三类数据:写请求,读请求,控制类请求。
- 系统协调者:
- RootCoord:类似于传统master角色 主要做一些DDL,DCL的管理,比如:创建Collection,删除Collection,或对于partion做管理。此外还有一个更大的责任,rootCoord给系统分配全局唯一时间戳。
- 写数据:
- DataCoord:协调者,分配,管理segment,管理dataNode,处理dataNode的故障恢复等。
- DataNode:消费来自数据流的数据,进行数据序列化,负责把log数据转成log snapshot,刷新到磁盘中。
- 索引创建:
- IndexCoord:对sealed SegMent创建索引,管理indexNode。
- IndexNode:负责具体的索引创建事宜。
- 查询:
- QueryCoord:数据查询管理,负责管理QueryNode。
- QueryNode:负责具体的数据查询事宜。
- 元信息与元数据存储:
- MetaStore:metastore使用ETCD存储。主要负责元信息与元数据的存储。比如:表结构,Segment结构,全局时间戳等。
- 写数据消息投递:
- Log Borker:Log broker采用了pulsar。最新的2.0及以上版本中,写入的数据都是先写入Log Broker,然后DataNode从Log Broker中读取。
- 数据与索引存储:
- Object Store:Object store当前采用了minio,主要用来存储数据,索引等。
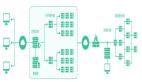
以上可以看出微服务比较多,微服务之间的通信方式主要有以下几种:

4、milvus向量写入与读取链路
4.1 milvus向量写入路径

- proxy通过produce把数据写入到Message borker的物理channel中。
- DataNode作为消费者消费数据。
- DataNode定期把消费数据存到Object store中。
- DataNode会定期通知dataCoord记录数据元信息。
3.2 milvus向量搜索路径

以下当前最新版本2.1.4的读流程 ,与网上的读流程版本链路不同,应该是做了改造。
- Proxy收到向量搜索(ANNS)请求后,会把请求丢给shard leader query node。
- Leader querynode 会依据每个segments的分布,把ANNS请求分发给每个Query Node。Query Node内部会基于最小搜索单位Segment,cpu核数等去做并行查询,并做结果reduce。
- Proxy收到所有的请求后,会对search结果做reduce,并返回给客户端。
5、milvus压测中的问题分析
压测版本:milvus-2.1.4
数据维度:512dim
索引:
5.1 压测结果
向量个数 | 索引 | 规格 | QPS | 99%耗时 |
十万*512dim | FLAT | 2*(8cpu*16Gi) | 880 | 82ms |
十万*512dim | FLAT | 2*(16cpu*16Gi) | 1489 | 62ms |
百万*512dim | FLAT | 2*(16cpu*16Gi) | 240 | 200ms |
千万*512dim | FLAT | 2*(16CPU*32Gi) | 20 | 1.98s |
5.2 压测中遇到的问题与分析
QPS与CPU使用率压不上去,CPU很难超过50%。(已经优化)
现象描述:
压测过程中,发现QPS始终压不上去,仔细排查发现查询节点的cpu使用率上不去,导致qps也上不去。
- 解决方案:
初步怀疑是查询节点调度问题,经过各种排查,发现与一个调度参数scheduler.cpuRation高度相关。以下是该参数在不同值的QPS情况。
规格 | scheduler.cpuRation | qps |
2*(8cpu*16Gi) | 20 | 385 |
2*(8cpu*16Gi) | 100 | 768 |
2*(8cpu*16Gi) | 120 | 913 |
2*(8cpu*16Gi) | 140 | 880 |
该参数主要用来评估一个search task的cpu使用情况,该参数越高,预示该task使用cpu越多,调度的时候,多个task去查询的并行数量就会少一些。现在怀疑并行task太多,并不会达到很高的QPS。
milvus并没有公开该参数配置,已经通过issue/enhancement提给milvus社区中了,后续版本应该会有所优化。
扩容查询节点后,短时间内segments没有自动均衡(怀疑,跟进中)
现象描述:
- 比如当前线上有两个查询节点,50个segments均分在两个nodes上。压测中多次发现如果增加一个node后,segments并不会自动均衡到新的node上。
- 当前进度:
整个压测过程中做了三次写入,有两次没有自动均衡,最后一次自动均衡了。
跟milvus社区维护人员咨询过该问题,他们认为理论上扩增是会自动均衡的。这与我们测出的结果不匹配,后续会继续跟进,找到问题所在。
持续大规模写了很久后,会导致大量growing segment,导致查询性能下降(跟进中)。
- 现象描述:
多个线程,持续大规模插入向量数据后,通过日志排查,发现部分部分查询节点上的segment一直处于growing状态,虽然这些segment在写入节点已经sealed了,但是某个查询节点并不会自动重新加载这些sealed segments,而是一直认为这些节点处于growing状态。
由于growing 状态的segment查询时不用索引,而是暴力搜索,这样会导致查询变的比较慢,需要手动操作release。

- 当前进度:
跟milvus社区维护人员咨询过该问题,后续还要持续跟进,找出原因并改进。
版本升级后,原有数据不兼容(已有方案)。
版本升级后,原有数据不兼容(已有方案)。
- 现象描述:
milvus版本由2.1.4升级到最新版后,原有数据没办法加载,且启动不了。回退版本后,发现数据元信息已经被写坏了,没法加载。 - 解决方案:
后续稳定后,谨慎做版本升级,或升级前做好充分调研。另外官方给出的建议是升级前先merge数据。
千万级别数据,压测QPS不能达到预期(跟进中)
- 现象描述:
当数据插入千万级别后,发现压测提升QPS比较难,99%耗时下降也比较快,即使通过提升cpu核的个数,提升也不是很明显。
比如以下是使用两个 32核 16G:

- 解决方案:
这个可能跟我们使用FLAT索引有关,后续会尝试新的索引方式压测。
不要通过deployment扩容缩容,尽量通过helm去操作
- 现象描述:
当通过deployment扩容后,因为参数不能统一修改的问题,做不到平滑扩容,比如扩容后可能需要重新release与load数据,造成短时间中断。
所以官网也给出建议尽量通过helm去平滑扩容。
6、总结
经过压测,milvus是可以满足我们当前业务场景的。以上压测中的一些遗留问题,我们还在跟进中,比如:大量growing segment问题,节点扩增等问题。这些问题并不是100%出现的,有些是在我们极端测试条件下才出现的。后续我们还会持续测试,定位原因,并反馈给社区进一步优化。以上压测的索引采用的是FLAT,官方建议我们采用图索引可以取得更高性能。由于我们当前的业务场景要用到FLAT索引,所以当前先基于FLAT索引去压测。后续会用到图索引,也会进行压测。
通过对milvus的压测,顺便了解并学习下milvus的设计。总体来说milvus是一款优秀的云原生向量数据库,它的一些设计理念还是比较先进的,把向量搜索与k8s结合在一起,通过简单的查询节点扩增便可以线性提升向量搜索的性能。对于一款分布式数据库,它实现了读写分离,存算分离。官网给出的文档也比较丰富,工具也比较多,比如:attu,birdwatcher等。