译者 | 朱先忠
审校 | 孙淑娟
简介
神经网络嵌入能够实现输入数据的低维表示,从而服务于各种类型的神经网络应用程序。嵌入有一些有趣的功能,因为它们可以捕获数据点的语义。这对于图像和视频等非结构化数据尤其有用,这样不仅可以对像素相似性进行编码,还可以对一些更复杂的关系进行编码。
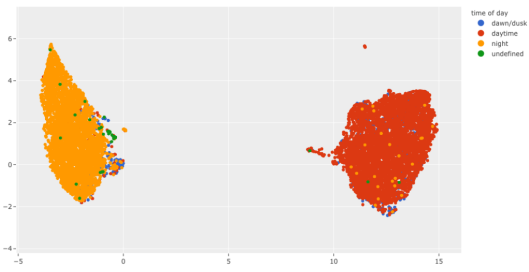
使用FiftyOne和Plotly可视化针对BDD100K数据集的嵌入
在这些嵌入上执行搜索可以应用于许多场景下,如分类任务、建立推荐系统,甚至是异常检测任务。对嵌入执行最近邻搜索以完成这些任务的主要好处之一是,无需为每个新问题创建自定义网络;您可以经常使用预先训练的模型。而且,使用某些公开可用模型生成的嵌入是完全可能的,而无需任何进一步的微调。
虽然有很多涉及嵌入的强大使用场景,但在执行嵌入搜索的工作流中往往都存在一些不同程度的挑战。具体而言,在大型数据集上执行最近邻搜索,然后有效地对搜索结果采取行动——例如执行自动标记数据等工作流,都存在技术和工具方面的挑战。为此,借助于Qdrant和FiftyOne这两个开源软件可以帮助简化这些工作流任务。
- Qdrant是一个开源的向量数据库,旨在对密集的神经嵌入执行近似最近邻搜索(ANN),这对于任何预计将扩展到大数据量的生产就绪系统都是非常必要的。
- FiftyOne是一个开源数据集管理和模型评估工具,允许开发人员有效地管理和可视化数据集,生成嵌入并改进模型结果。
在本文中,我们将MNIST数据集加载到FiftyOne中,并基于ANN进行分类。数据点将通过从训练数据集中的K个最近点中选择最常见的参考答案标签进行分类。换句话说,对于每个测试样本,我们将使用选定的距离函数选择其K个最近的邻居,然后通过投票选择最佳标签。另一方面,向量空间中的所有搜索都将使用Qdrant来完成,以加快速度。然后,我们将在FiftyOne中评估该分类的结果。
安装
如果您想开始使用Qdrant的语义搜索,您需要运行它的一个实例,因为该工具以客户机—服务器方式工作。要做到这一点,最简单的方法是使用一个官方Docker映像,只需一个命令即可启动Qdrant:
运行该命令后,我们将运行Qdrant服务器,端口6333处暴露HTTP API,端口6334处暴露gRPC接口。
此外,我们还需要安装一些Python包。我们将使用FiftyOne来可视化数据、它们的参考答案标签以及嵌入相似性模型预测的数据。嵌入将通过torchvision中提供的MobileNet v2创建。当然,我们也需要以某种方式与Qdrant服务器通信,因为我们将使用Python,所以Qdrant_client是实现这一任务的首选方式。
整体任务流程
1. 加载数据集
2. 生成嵌入
3. 将嵌入加载到Qdrant
4. 最近邻分类
5. FiftyOne评估
加载数据集
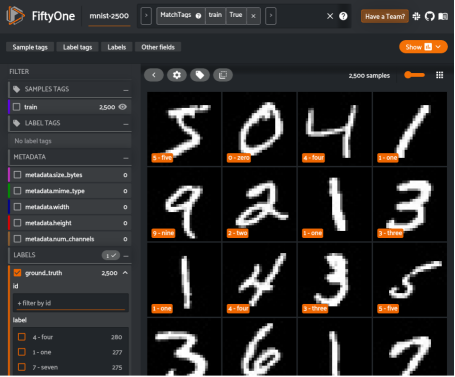
为了使事情顺利进行,我们需要采取几个步骤。首先,我们需要加载MNIST数据集,并从中提取训练样本,因为我们将在搜索操作中使用它们。为了使一切更快,我们不打算使用所有的样本,只使用2500个样本。我们可以使用FiftyOne数据集Zoo,并通过一行代码来加载所需的MNIST子集。
接下来,让我们仔细分析一下FiftyOne应用程序中所使用的数据集。
生成嵌入
下一步是在数据集中的样本上生成嵌入。这始终可以在FiftyOne之外使用您的自定义模型完成。然而,FiftyOne也在其中的FiftyOneModelZoo中提供了各种模型,这些模型可以直接用于生成嵌入。
在本例中,我们使用在ImageNet上训练的MobileNetv2来计算每个图像的嵌入。
将嵌入结果加载到Qdrant
Qdrant不仅可以存储向量,还可以存储一些相应的属性——每个数据点都有一个相关的向量,还可以选择附带一个JSON类型的属性项。我们想用这个来传递参考答案标签,以确保我们可以在稍后做出预测。
创建嵌入后,我们可以开始与Qdrant服务器进行通信了。需要说明的是,QdrantClient有一个类实例比较有用,因为它包含了所有必需的方法。让我们连接并创建一个名为“mnist”的点集合。向量大小取决于模型输出;因此,如果我们想在以后使用不同的模型进行实验,我们需要导入不同的模型,但其余的将保持不变。最终,在确保集合存在后,我们可以发送所有向量及其包含其真实标签的有效载荷。
最近邻分类
现在对数据集执行推断。我们可以为测试数据集创建嵌入,但忽略基本事实,并尝试使用ANN找到它,然后比较两者是否匹配。让我们一步一步地从创建嵌入开始。
是时候“施展魔法”了。让我们遍历测试数据集的样本和相应的嵌入,并使用搜索操作从训练集中找到15个最接近的嵌入。我们还需要选择有效载荷,因为它们包含找到特定点附近最常见标签所需的参考答案标签。借助于Python的Counter类,我们可以避免再重写任何样板代码。最常见的标签将作为“ann_production”存储在FiftyOne中的每个测试样本上。
这些内容都体现在下面这个函数中。该函数将使用嵌入向量作为输入,并使用Qdrant搜索功能查找与测试嵌入最近的邻居,生成类型预测,并返回一个FiftyOne Classification对象,我们可以将其存储在FiftyOne数据集中。
我们通过计算属于最常见标签的样本分数来估计置信度。这给了我们一种直觉,即我们在预测每种情况的标签时有多么确定,并且可以在FiftyOne中使用,轻松找出令人困惑的样本。
FiftyOne评估
现在是取得一些成果的时候了!让我们从可视化这个分类器的表现开始。我们可以轻松启动FiftyOne应用程序来查看参考答案标签、预测结果和图像。
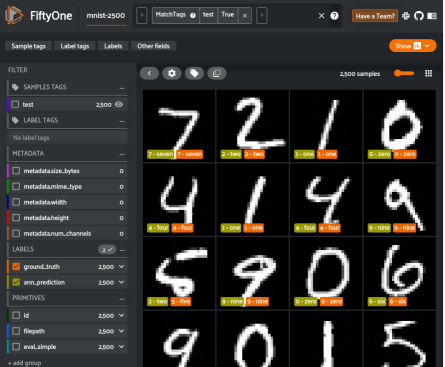
FiftyOne提供了各种内置方法来评估模型预测,包括图像和视频数据集上的回归、分类、检测、多边形、实例和语义分割。通过下面两行代码,我们即可以计算并打印分类器的评估报告。
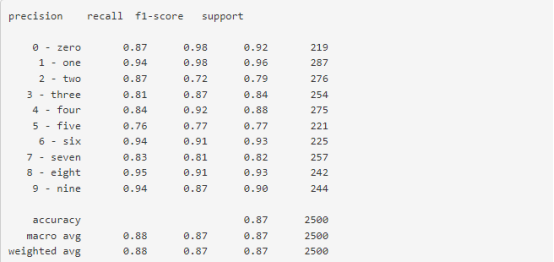
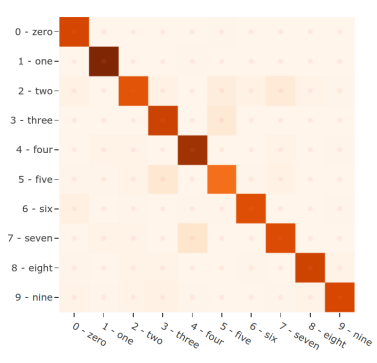
在评估FiftyOne之后,我们可以使用results对象生成一个交互式混淆矩阵(https://voxel51.com/docs/fiftyone/user_guide/plots.html#confusion-matrices),允许我们点击单元格并自动更新应用程序以显示相应的样本。
我们还可以再深入一点。我们可以使用FiftyOne复杂的查询语言,轻松找到所有与实际情况不匹配的预测,但预测的可信度很高。这些通常是数据集中最令人困惑的样本,不过也是我们可以从中获得最深刻见解的样本。
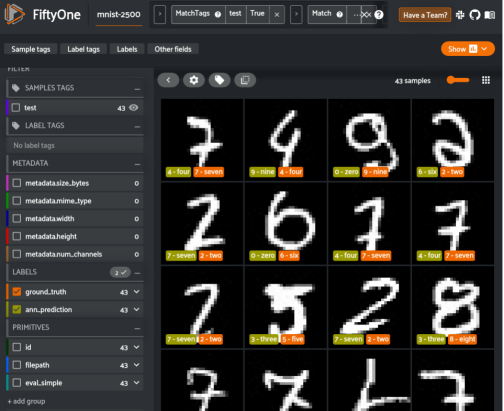
上图中展示了模型中最令人困惑的样本,正如您所看到的,与数据集中的其他图像相比,它们非常不规则。我们可以采取的改进模型性能的下一步可能是使用FiftyOne来添加与这些类似的精确样本。然后,可以通过FiftyOne与CVAT,以及Labelbox等工具之间的集成对这些样本进行注释。此外,我们可以使用更多的向量进行训练,或者通过相似性学习对模型进行微调,例如,使用三元组损失算法。但现在,这个使用FiftyOne和Quadrant进行向量相似性分类的示例已经能够很好地工作了。
就这么简单,我们使用FiftyOne和Qdrant作为嵌入后端创建了一个ANN分类模型,因此查找向量之间的相似性可以不再像传统k-NN那样成为我们任务的瓶颈了。
请自己试试看
最后,Github代码仓库中的笔记本文件包含了你在本文中看到的所有内容的源代码。此外,它还包括该过程的一个实际用例,以在BDD100K道路场景数据集上执行夜间和白天属性的预注释。
总之,FiftyOne和Qdrant两个开源库可以一起使用,有效地对嵌入执行最近邻居搜索,并对图像和视频数据集的结果进行操作。这个过程的美妙之处在于它的灵活性和可重复性。您可以轻松地将新字段的附加参考答案标签加载到FiftyOne和Qdrant中,并使用现有嵌入重复此预注释过程。这可以快速降低注释成本,并更快地生成更高质量的数据集。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Nearest Neighbor Embeddings Search With Qdrant and FiftyOne,作者:Eric Hofesmann