













4月14日,信服云可靠性技术专家Marshall在信服云《Tech Talk · 云技术有话聊》系列直播课上进行了《关键基础部件可靠性技术解析》的分享,详细介绍了 IT系统常见的物理故障对业务的可靠性的影响、如何运用软件定义解决硬件故障等内容。以下是他分享的内容摘要,想要了解更多可以点击阅读原文观看直播回放。
一、可靠性的定义和目标
可靠性是指系统不会意外地崩溃、重启甚至发生数据丢失,这意味着一个可靠的系统必须能够做到故障自修复,对于无法自修复的故障也尽可能进行隔离,保障系统其余部分正常运转。简而言之,可靠性的目标是缩短因故障(产品质量、外部部件、环境、人因等)造成的业务中断时间。
高可靠可以从三个层面理解:一,不出故障,系统可以一直正常运行,这种情况就需要提高硬件的研发质量。二,故障不影响业务。三,影响业务但能快速恢复。后两个层面可以通过“软件定义”的方式去规避硬件故障产生的业务中断。
谈到可靠性,首先要了解服务器的关键基础部件。从业界的服务器统计数据看,硬件部件的问题集中在内存、硬盘、CPU、主板、电源、网卡上。在云的环境当中,同一台服务器上可能运行了若干不同业务、不同场景的虚拟机,一旦物理设备崩溃,将会波及众多用户,同时也会对运营商自身造成巨大损失。而在现有的故障模式中,内存、硬盘故障是最高发和最严重故障。
关于内存和硬盘的故障,可以通过这两个案例来进一步了解。
案例一,内存UCE错误导致服务器系统反复宕机重启。服务器发生宕机重启,登录服务器的BMC管理界面,查询服务器的告警信息,出现如下告警:“2019-07-25 08:03:06 memory has a uncorrectable error.”后来,进一步查询硬件错误日志文件,发现DIMM020有大量内存CE错误和部分内存UCE错误,可知是因为DIMM020内存条发生UCE错误导致服务器宕机重启。
案例二,磁盘卡慢导致大数据集群故障。某大数据平台集群节点出现慢盘故障(系统每一秒执行一次iostat命令,监控磁盘I/O的系统指标,如果在60s内,svctm大于100ms的周期数大于30次则认为磁盘有问题,产生该告警)。先是ZOOKEEPER出现故障,后出现集群平衡状态异常。然后同一节点的其他服务也出现故障,最后整个节点所有服务全部故障,随后重启自动恢复。但是在3-10分钟之后该节点就会重复出现此情况。在未发现其他问题的情况下选择重启系统,业务中断时间十几分钟。
二、内存的可靠性技术
内存从外部结构看有PCB板、金手指、内存芯片、内存条固定卡缺口等。从内部结构看,包括存储体、存储单元Cell、存储阵列Bank、Chip(device)、Rank、DIMM、Channel等。
基于内存的结构,内存技术的提升(制程缩小和频率)容易带来更高的故障率。
(一)制程缩小带来的挑战
(1)光刻更容易受到衍射,聚焦等影响质量。
(2)外延生长(EPI)容易出现漏生长和外延生长间的短路等。
(3)蚀刻清洗等工艺的particle造成的影响加重。
(4)单die尺寸变小,单wafer die数量增加。
(5)未来TSV封装多die后段封装难度加大,失效率增加。
(二)频率提升带来的挑战
(1)高速信号时序margin更小,兼容性问题更突出。
(2)信号衰减更严重,DDR5增加DFE电路,设计更复杂。
(3)更高频率带来更高功耗,对PI的要求更高。
内存故障按照“故障能不能纠正”可以分为两类:CE(Correctable Error):可以纠正任意单比特错误、部分单颗粒多比特错误的统称;UE(Uncorrectable Error):不能纠正的错误统称。有一部分UE错误由于操作系统无法处理会导致系统宕机。
内存发生故障的原因有:内存单元能量泄漏 leakage、内存数据传输路径存在高阻抗、内存电压工作异常、内部时序异常、内部操作异常(如自刷新)、bit line/word line线路异常、地址解码线路异常、内存存在弱单元(可正常使用)、宇宙射线或放射性(没有造成永久损伤)导致的软失效(多次检测故障不复现)。
在处理故障时,会进行分层处理,业内有软件主导和和硬件主导两种思想。基于硬件主导的观点,会在器件选型的时候,选择一些质量比较高的硬件,另外,硬件本身具备一些“可靠性”,比如会自动地纠正一些比较简单的错误。
但硬件是没有办法做得非常可靠的,就需要软件去做一些工作。软件定义的方式会把有故障的内存区域隔离出来,让它不再使用,从而不会对业务产生影响。
CE(可以纠正的错误)发生后,如果不去处理它,会有可能变成不可纠正的UE错误。所以要防微杜渐,发生CE(可以纠正的错误)时,要进一步处理,隔离出可疑的故障。
信服云针对内存CE故障隔离方案设计思路
当内存硬件发生CE触发中断,看这些内存能否被隔离(不是被操作系统内核或外设使用),如果可以被隔离就加入白名单,对这些内存进行隔离。当使用内存隔离功能把发生故障的内存页切换到正常的内存页后,就把这个故障内存页隔离出来不再使用。
同时,这些故障发生的位置和次数等详细信息会进行告警,帮助运维人员对故障内存条进行更换。针对没有办法隔离的内存,在系统下次重启时根据重启之前记录的内存错误区域的信息,在系统没有使用这些内存时就把有问题的内存部分隔离出来,这样就保证系统使用的内存是没有问题的部分。
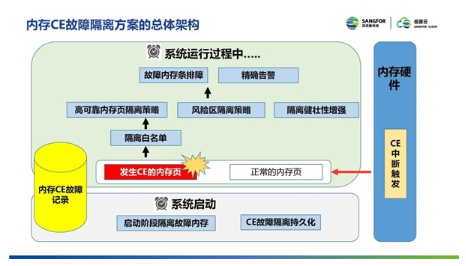
↑ 内存CE故障隔离方案总体架构
信服云实施这个方案之后,通过收集现网运营数据统计,平均隔离成功成功率为96.93%。相较于业界一般的方案的CE屏蔽,不能及时隔离CE以及出错后定位内存条的问题,信服云在方案上具有领先优势,并且在这个领域申请了5项专利。隔离方案在使用过程中针对CPU和内存资源开销小,并且效果明显。
针对内存UE故障,信服云的方案设计思路是解决内存UE的可恢复和提前预警问题,把一部分UE宕机降级为杀死对应应用程序,甚至只需隔离坏页,避免宕机来提升系统稳定性和可靠性。至少提升30%以上内存故障恢复能力,信服云的解决方案能够达到60% 内存UE故障恢复率,效果优于业界公开数据(业界普遍是UE故障恢复能覆盖50%),在实际POC测试场景中,优于业界的一般方案(如一般方案会宕机,无内存故障告警日志,无法定位故障内存所在的插槽位置)。
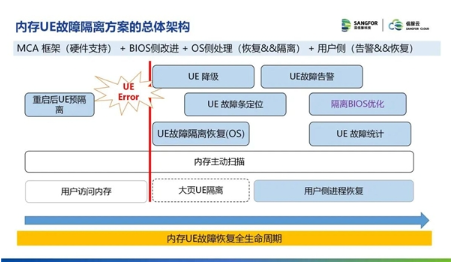
↑ 内存UE故障隔离方案总体架构
三、硬盘的可靠性技术
硬盘主要包括系统盘、缓存盘、数据盘。系统盘一般使用固态硬盘SSD,存放云平台系统软件和主机OS,以及相关的日志和配置。缓存盘一般使用固态硬盘SSD,利用SSD速度快的特性作为缓存盘作为IO读写提速的缓存层,用于存放用户业务经常被访问的数据,称之为热数据。数据盘一般使用机械硬盘HDD,容量高适合做数据盘则作为数据(如虚拟机的虚拟磁盘)最终存放的位置。
(1)硬盘TOP故障模式/分类:
卡死:硬盘IO暂时或者一直不响应;
卡慢:硬盘IO明显变慢或者卡顿;
坏道:硬盘逻辑单元(sector)损坏;
坏块:硬盘物理单元(block)损坏;
寿命不足:机械硬盘物理磨损,或者固态硬盘的闪存颗粒积极达到擦写次数。
当硬盘出现输入输出(Input Output,I/O)响应时间变长,或者卡住不返回的情况,会导致用户业务持续出现卡慢,甚至挂起,一块硬盘卡住甚至会导致系统的全部业务中断。
随着使用年限的增加,硬盘出现坏道、磁头退化或者其他问题的概率也在增加;从历史问题分布、以及业界硬盘可靠性故障曲线,都可以看到硬盘卡盘问题正成为影响系统稳定运行的最严重问题之一。

↑ 信服云卡慢盘解决方案总体架构
(2)信服云针对卡慢盘解决方案的思路:
1.针对磁盘卡慢故障模式复杂的问题,多维度检测确诊。采用了Linux通用的工具和信息,不依赖特定硬件工具,包括内核日志分析、smart信息分析、硬盘io监控数据分析等从多个维度精确定位故障硬盘。
2.针对卡慢盘处置时业务还是数据的抉择,制定了多级隔离算法。①轻度慢盘:不隔离,在页面告警通知用户;②严重慢盘:选择业务:对端异常时不隔离,页面告警通知用户;③卡盘:选择业务:第一次出现对端异常时不隔离,页面告警通知用户;④卡盘(频繁):选择数据:一个小时内出现3次异常,进行永久隔离。
3.在多级隔离算法的基础上进行阈值打磨。用大量真实卡慢盘进行测试以及用户侧采集的数据制定更加精准的卡慢检测阈值;使用故障注入工具进行阈值验证。
开启卡慢盘功能后的效果,可保障1min内触发隔离,虚拟机未出现HA,隔离后业务IO恢复稳定。
以上就是本次直播的主要内容。对云计算感兴趣的IT朋友可以关注“深信服科技”公众号回顾本期直播,了解更多云计算知识。














