一、简介
TiDB并不陌生,很多团队都在使用,我们为什么要是用它,它有哪些特点呢?
TiDB 是一款开源分布式关系型数据库,可以同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP) 的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性,支持在本地和云上部署。
从中可以看到TiDB有如下特性:
- 同时支持OLTP和OLAP
- 分布式数据库,金融级别高可用
- 完全兼容MySQL,无缝切换
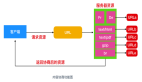
二、TiDB结构介绍
整体架构图(以下用图来自TiDB官方文档&借鉴知乎)

2.1 TiDB Server
SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行鉴权、 SQL 解析和优化,最终生成分布式执行计划。TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。
2.2 PD (Placement Driver) Server
整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。PD 不仅存储元信息,同时还会根据 TiKV 节点实时上报的数据分布状态,下发数据调度命令给具体的 TiKV 节点,可以说是整个集群的“大脑”。此外,PD是无状态的,通过raft一致性协议完成数据同步, 本身也是由至少 3 个节点构成,拥有高可用的能力,建议部署奇数个 PD 节点。
2.3 存储节点(TiKV&TiFLASH)
- TiKV Server
TiDB的存储方式皆为KV(key-value)存储,一切皆KV。
负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolation) 的隔离级别,这也是 TiDB 在 SQL 层面支持分布式事务的核心。TiDB 的 SQL 层做完 SQL 解析后,会将 SQL 的执行计划转换为对 TiKV API 的实际调用。所以,数据都存储在 TiKV 中。另外,TiKV 中的数据都会自动维护多副本(默认为三副本),天然支持高可用和自动故障转移,副本质检也是通过raft协议维持数据一致。
- TiFlash
TiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的是,在 TiFlash 内部数据是以列式的形式进行存储,主要的功能是为分析型即OLAP场景加速。一般TiDB作数据库使用OLTP功能,无需部署该节点。

- TiDB与MySQL差异
截止到TiDB4.0版本,与MySQL有如下差异(图片引自知乎)

三、TiDB存储介绍
作为保存数据的系统,首先要决定的是数据的存储模型,也就是数据以什么样的形式保存下来。TiKV 的选择是 Key-Value 模型,并且提供有序遍历方法。
TiKV 数据存储的两个关键点:
这是一个巨大的 Map,也就是存储的是 Key-Value Pairs(键值对)
这个 Map 中的 Key-Value pair 按照 Key 的二进制顺序有序,也就是可以 Seek 到某一个 Key 的位置,然后不断地调用 Next 方法以递增的顺序获取比这个 Key 大的 Key-Value。
3.1 持久化使用RocksDB
任何持久化的存储引擎,数据终归要保存在磁盘上,TiKV 也不例外。但是 TiKV 没有选择直接向磁盘上写数据,而是把数据保存在 RocksDB 中,具体的数据落地由 RocksDB 负责。这个选择的原因是开发一个单机存储引擎工作量很大,特别是要做一个高性能的单机引擎,需要做各种细致的优化,而 RocksDB 是由 Facebook 开源的一个非常优秀的单机 KV 存储引擎,可以满足 TiKV 对单机引擎的各种要求。这里可以简单的认为 RocksDB 是一个单机的持久化 Key-Value Map。
- Region
为了实现存储的水平扩展,数据将被分散在多台机器上。对于一个 KV 系统,将数据分散在多台机器上有两种比较典型的方案:
Hash:按照 Key 做 Hash,根据 Hash 值选择对应的存储节点。
Range:按照 Key 分 Range,某一段连续的 Key 都保存在一个存储节点上。
TiKV 选择了第二种方式,将整个 Key-Value 空间分成很多段,每一段是一系列连续的 Key,将每一段叫做一个 Region,并且会尽量保持每个 Region 中保存的数据不超过一定的大小,目前在 TiKV 中默认是 96MB。每一个 Region 都可以用 [StartKey,EndKey) 这样一个左闭右开区间来描述。

将数据划分成 Region 后,TiKV 将会做两件重要的事情:
- 以 Region 为单位,将数据分散在集群中所有的节点上,并且尽量保证每个节点上服务的 Region 数量差不多。
- 以 Region 为单位做 Raft 的复制和成员管理。
以 Region 为单位做数据的分散和复制,TiKV 就成为了一个分布式的具备一定容灾能力的 KeyValue 系统,不用再担心数据存不下,或者是磁盘故障丢失数据的问题。

3.2 TiDB索引介绍
- 表数据与key-value的映射
TiDB的存储方式key-value的键值对,为了方便查找在设计上做了如下优化:
为同一张表设计一个表id,用TableID表示,整数且全局唯一
为每一张表的每一行设计一个行id,用RowId表示,整数且同一张表内唯一。这里还有个小优化,如果这张表有主键,则TiDB把主键作为RowId,否则自行分配一个。
映射结构示例:
Key: tablePrefix{TableID}_recordPrefixSep{RowID}
Value: [col1, col2, col3, col4]
其中,tablePrefix、recordPrefixSep都是固定的常量,为了在key空间内区分其他数据。
- 索引与key-value的映射
TiDB索引支持主键索引(MySQL主键索引)和二级索引(MySQL平台非聚簇索引,分唯一索引和非唯一索引),它和表与key-value的映射方式相似,也会分配一个全局唯一整数索引id,使用IndexId表示。
对于主键索引和唯一索引,由于列的数据是唯一的,因此对应的key-value的结构如下:
Key:tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue Value:RowID
其中indexedColumnsValue表示查询列的值,最终是列值对应一个RowId
对于非唯一索引,由于列的数据不唯一,一个键值可能对应多行,需要根据键值范围查询对应的 RowID。因此,按照如下规则编码成 (Key, Value) 键值对:
Key:tablePrefix{TableID}_indexPrefixSep{IndexID}_indexedColumnsValue_{RowID} Value:null
这里需要注意的是,value是null,并不是RowID,而RowID是拼接在key的结尾的。这里为什么不把value设计为RowID呢?猜测是因为key是不能够重复的,要全局唯一,而且要均匀分布在TiKV的各个节点,只能把RowID拼接在key的结尾处,而且查询的时候是根据键值RowID前面的范围来查询。
- 索引示例
上述所有编码规则中的 tablePrefix、recordPrefixSep 和 indexPrefixSep 都是字符串常量,用于在 Key 空间内区分其他数据,定义如下:
另外请注意,上述方案中,无论是表数据还是索引数据的 Key 编码方案,一个表内所有的行都有相同的 Key 前缀,一个索引的所有数据也都有相同的前缀。这样具有相同的前缀的数据,在 TiKV 的 Key 空间内,是排列在一起的。因此只要小心地设计后缀部分的编码方案,保证编码前和编码后的比较关系不变,就可以将表数据或者索引数据有序地保存在 TiKV 中。采用这种编码后,一个表的所有行数据会按照 RowID 顺序地排列在 TiKV 的 Key 空间中,某一个索引的数据也会按照索引数据的具体的值(编码方案中的 indexedColumnsValue)顺序地排列在 Key 空间内。
通过一个简单的例子,来理解 TiDB 的 Key-Value 映射关系。假设 TiDB 中有如下这个表:
假设该表中有4行数据:
首先每行数据都会映射为一个 (Key, Value) 键值对,同时该表有一个 int 类型的主键,所以 RowID 的值即为该主键的值。假设该表的 TableID 为 10,则其存储在 TiKV 上的表数据为:
除了主键外,该表还有一个非唯一的普通二级索引 idxAge,假设这个索引的 IndexID 为 1,则其存储在 TiKV 上的索引数据为:
四、TiDB执行计划查看
4.1 概览
由于TiDB除了协议上与MySQL兼容之外,其余的林林总总都有着自己独特的实现,尤其是最核心的存储实现方式更是天差地别,因此查看执行计划也是完全不一样的,以一个简单SQL为例来解析说明TiDB执行计划的含义。
SQL:

执行计划(SQL1):

执行计划(SQL3):

首先,create_time列上加了普通二级索引。先介绍各个列的含义:
- id 为算子名,或执行 SQL 语句需要执行的子任务。
- estRows 为显示 TiDB 预计会处理的行数。该预估数可能基于字典信息(例如访问方法基于主键或唯一键),或基于 CMSketch 或直方图等统计信息估算而来(说了这么多,其实就是和MySQL执行计划的rows类似)。
- task 显示算子在执行语句时的所在位置。
- access object 显示被访问的表、分区和索引。显示的索引为部分索引。以上示例中 TiDB 使用了 a 列的索引。尤其是在有组合索引的情况下,该字段显示的信息很有参考意义。
- operator info 显示访问表、分区和索引的其他信息。
4.2 详细介绍
4.2.1 算子
算子是为返回查询结果而执行的特定步骤。真正执行扫表(读盘或者读 TiKV Block Cache)操作的算子有如下几类:
- TableFullScan:全表扫描。
- TableRangeScan:带有范围的表数据扫描。
- TableRowIDScan:根据上层传递下来的 RowID 扫描表数据。时常在索引读操作后检索符合条件的行。
- IndexFullScan:另一种“全表扫描”,扫的是索引数据,不是表数据。
- IndexRangeScan:带有范围的索引数据扫描操作。
TiDB 会汇聚 TiKV/TiFlash 上扫描的数据或者计算结果,这种“数据汇聚”算子目前有如下几类:
- TableReader:将 TiKV 上底层扫表算子 TableFullScan 或 TableRangeScan 得到的数据进行汇总。
- IndexReader:将 TiKV 上底层扫表算子 IndexFullScan 或 IndexRangeScan 得到的数据进行汇总。
- IndexLookUp:先汇总 Build 端 TiKV 扫描上来的 RowID,再去 Probe 端上根据这些RowID 精确地读取 TiKV 上的数据。Build 端是IndexFullScan 或IndexRangeScan 类型的算子,Probe 端是TableRowIDScan 类型的算子。
- IndexMerge:和IndexLookupReader 类似,可以看做是它的扩展,可以同时读取多个索引的数据,有多个 Build 端,一个 Probe 端。执行过程也很类似,先汇总所有 Build 端 TiKV 扫描上来的 RowID,再去 Probe 端上根据这些 RowID 精确地读取 TiKV 上的数据。Build 端是IndexFullScan 或IndexRangeScan 类型的算子,Probe 端是TableRowIDScan 类型的算子。
- 算子的执行顺序
算子的结构是树状的,但在查询执行过程中,并不严格要求子节点任务在父节点之前完成。TiDB 支持同一查询内的并行处理,即子节点“流入”父节点。父节点、子节点和同级节点可能并行执行查询的一部分。
在SQL1示例中,│ └─IndexFullScan_15 算子为 idx_create_time(create_time) 索引中扫描并降序排序取出RowID,├─Limit_17(Build)算子拿出前10个RowID,└─TableRowIDScan_16(Probe) 算子随后拿上面返回的RowID从表中检索出数据。
Build 总是先于 Probe 执行,并且 Build 总是出现在 Probe 前面。即如果一个算子有多个子节点,子节点 ID 后面有 Build 关键字的算子总是先于有 Probe 关键字的算子执行。TiDB 在展现执行计划的时候,Build 端总是第一个出现,接着才是 Probe 端。
- 范围查询
在 WHERE/HAVING/ON 条件中,TiDB 优化器会分析主键或索引键的查询返回。如数字、日期类型的比较符,如大于、小于、等于以及大于等于、小于等于,字符类型的 LIKE 符号等。
若要使用索引,条件必须是 "Sargable" (Search ARGument ABLE) 的。例如条件 YEAR(date_column) < 1992 不能使用索引,但 date_column < '1992-01-01 就可以使用索引。
推荐使用同一类型的数据以及同一类型的字符串和排序规则进行比较,以避免引入额外的 cast 操作而导致不能利用索引。
可以在范围查询条件中使用 AND(求交集)和 OR(求并集)进行组合。对于多维组合索引,可以对多个列使用条件。例如对组合索引 (a, b, c):
- 当 a 为等值查询时,可以继续求 b 的查询范围。
- 当 b 也为等值查询时,可以继续求 c 的查询范围。
- 反之,如果 a 为非等值查询,则只能求 a 的范围。
4.2.2 task简介
目前 TiDB 的计算任务分为两种不同的 task:cop task 和 root task。Cop task 是指使用 TiKV 中的 Coprocessor 执行的计算任务,root task 是指在 TiDB 中执行的计算任务。
SQL 优化的目标之一是将计算尽可能地下推到 TiKV 中执行。TiKV 中的 Coprocessor 能支持大部分 SQL 内建函数(包括聚合函数和标量函数)、SQL LIMIT 操作、索引扫描和表扫描。但是,所有的 Join 操作都只能作为 root task 在 TiDB 上执行。
4.2.3 operator info简介
EXPLAIN 返回结果中 operator info 列可显示诸如条件下推等信息。本文以上示例中,operator info 结果各字段解释如下:
- range: [1,1] 表示查询的 WHERE 字句 (a = 1) 被下推到了 TiKV,对应的 task 为 cop[tikv]。
- keep order:false 表示该查询的语义不需要 TiKV 按顺序返回结果。如果查询指定了排序(例如 SELECT * FROM t WHERE a = 1 ORDER BY id),该字段的返回结果为 keep order:true。
- stats:pseudo 表示 estRows 显示的预估数可能不准确。TiDB 定期在后台更新统计信息。也可以通过执行 ANALYZE TABLE t 来手动更新统计信息。
EXPLAIN 执行后,不同算子返回不同的信息。你可以使用 Optimizer Hints 来控制优化器的行为,以此控制物理算子的选择。例如 /*+ HASH_JOIN(t1, t2) */ 表示优化器将使用 Hash Join 算法。
4.2.4 索引总结
SQL1中的执行计划:
- 算子│ └─IndexFullScan_15在TiKV操作扫描索引idx_create_time(create_time)并降序排序(operator info表明)
- 算子├─Limit_17(Build)获取前10条(根据operator info的offset:0, count:10得知)数据的RowID
- 算子└─TableRowIDScan_16(Probe)在TiKV根据上面拿到的RowID去表中查询数据
- 算子IndexLookUp_18在TiDB汇总结果├─Limit_17(Build)上的RowID,之后使用RowID从算子└─TableRowIDScan_16(Probe)精确查找数据
其实IndexLookUp_18这个算子作用就是汇聚作用,汇总从TableRowIDScan或TableRangeScan和 IndexFullScan 或 IndexRangeScan的数据。
SQL3中的执行计划:
- 算子└─IndexFullScan_19在TiKV从索引create_time索引降序排序读取10条RowID
- 算子└─IndexReader_21在TiDB汇总数据直接返回,无需再去读表,因为SELECT的字段就是索引上的
- 算子Limit_10为根算子,把结果返回客户端
写在最后,以上是执行计划,是相对粗略的结果,如果要获取详细的结果(带有性能、执行时间等),需要查看性能分析结果,方法为SQL语句前加上EXPLAIN ANALYZE,以下为SQL1的性能分析示例:

分析结果:


由于execution_info信息比较长,分开两次截取。性能分析计划相比执行计划多出了actRows和execution_info两个比较重要需要常去关注的信息。actRows为实际扫描行数,execution_info表明了各种执行的细节。
五、总结
TiDB目前的使用还是很广泛的,在很多家知名企业都有着非常成功的实践。本文介绍了TiDB的架构、使用的场景、与MySQL的兼容性、数据以及索引的存储原理、执行计划的查看,基本涵盖了TiDB使用的所有基础性东西。当然TiDB的复杂度远远高于文中所介绍的,其内部的设计以及各种实现是相当复杂的,非常值得细究。
通过本篇文章的介绍,希望读者对TiDB有一个大致的了解,可以扩充知识点。总结一句话,MySQL可以无缝切换到TiDB,但仅限于查询使用,事务支持上两者其实还有着细微的差别,并不建议从业务上直接完全替换。
参考文献:
TiDB 简介 | PingCAP Docs https://docs.pingcap.com/zh/tidb/stable/overview
TiDB介绍 - 知乎https://zhuanlan.zhihu.com/p/494715695