一、进程基本概念
进程是计算机里面最重要的概念之一。操作系统的目的就是为了运行进程。那么到底什么是进程,操作系统又是如何实现进程和管理进程的呢?
1.1 进程与程序
进程是程序的执行过程。程序是静态的,是存在于外存之中的,电脑关机后依然存在。进程是动态的,是存在于内存之中的,是程序的执行过程,电脑关机后就不存在进程了。进程的内容来源于程序,进程的启动过程就是把程序从外存加载到内存的过程。程序文件是有格式的,UNIX-Like操作系统的通用程序文件格式是ELF。程序文件是从源码文件编译过来的,源码文件很多是用C或者C++书写的。关于编译系统,请参看《深入理解编译系统》,关于C和C++,请参看《深入理解C与C++》。
1.2 进程与线程
进程是操作系统分配和管理系统资源的基本单位。进程本来也是程序执行的基本单位,但是自从有了线程之后就不是了。现在线程是程序执行的基本单位,代表一个执行流,一个进程可以有多个执行流。最初的时候,一个进程就只有一个执行流,也就是主线程,此时进程就是线程,线程就是进程。当程序需要多个执行流的时候,采取的都是多进程的方式。但是创建一个新进程是一个很耗费资源的事情,而且多个进程之间还要进行进程间通信也很费事。于是人们便想到了开发进程内并发机制,也就是在一个进程内能同时存在多个执行流(线程)。不同的人设计的进程内并发机制并不相同。按照线程的管理是否实现在内核里,进程内并发机制可以分为两大类,分别是内核级线程(内核级线程也被叫做轻量级进程)和用户级线程,注意这两个名词都带个级,它们是进程内并发机制的两个子类,并不是具体的线程。内核级线程下的线程,按照运行主体是在内核空间还是在用户空间可以分为内核线程和用户线程。用户级线程下的线程,按照运行主体是在内核空间还是在用户空间也可以分为内核线程和用户线程,但是由于用户级线程实现在用户空间,所以它的线程不可能存在于内核空间。内核级线程下的用户线程一般被叫做用户线程,简称线程。用户级线程下的用户线程如果再叫用户线程或者线程就会产生混淆,于是就被叫做协程或者纤程。如下图所示:

这两种实现多线程的方法各有优缺点。在用户空间实现的话,优点是简单,不用改内核,只需要实现一个库就行了,创建线程开销小,缺点是线程之间做不到真并发,一个线程阻塞就会阻塞同一进程的所有其它线程。在内核空间实现的话,缺点是麻烦,需要改内核,创建线程开销大,但是优点是能做到真并发,一个进程的多个线程可以同时在多个CPU上运行,能充分利用CPU。当然这两者并不是对立的,它们可以同时实现,一个进程可以有多个内核级线程,一个内核级线程又可以有多个用户级线程,编程者可以灵活选择使用哪种多线程方式。
1.3 进程与内核
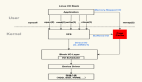
进程与内核在同一个虚拟地址空间中,但是在不同的子空间,进程是在用户空间,内核是在内核空间。整个系统只有一个内核空间,但是却有很多用户空间,不过当前用户空间永远只有一个(对于一个CPU来说)。虽然内核空间和用户空间在同一个空间中,但是它们的权限并不相同。内核空间处于特权模式,用户空间处于非特权模式。内核可以随意访问和操作用户空间,但是用户空间对内核空间却是看得见摸不着。内核空间可以做很多特权操作,用户空间没有权限做,但是有些时候又需要做,所以内核为用户空间开了一个口子,就是系统调用,用户空间可以通过系统调用来请求内核的服务。关于系统调用请参看《深入理解Linux系统调用与API》。
下面我们用一张图来总结内核和进程之间的关系:

这个图是在讲进程调度的时候画的,但是用在这里表示进程和内核的关系也很合适。
1.4 进程与内存
对于内核来说,内存是有虚拟内存和物理内存之分的。但是对于进程来说,这些都是透明的,进程只需要知道自己独占一个用户空间的内存就可以了,它不知道也不需要知道自己是否运行在虚拟内存上。如果非要说进程知道物理内存和虚拟内存,那么进程也只能分配和管理虚拟内存,它没法分配管理物理内存,因为物理内存对它来说是透明的。内核在合适的时候会为进程分配相应的物理内存,保证进程在访问内存的时候一定会有对应的物理内存,但是进程对此毫不知情,也管不了。
进程需要内存的时候可以通过系统调用brk、sbrk、mmap来向内核申请分配虚拟内存。但是直接使用系统调用来分配管理内存显然很麻烦效率也低,为此libc向进程提供了malloc库,malloc提供了malloc、free等几个接口供进程使用。这样进程需要内存的时候就可以直接使用malloc去分配内存,使用完了就用free去释放内存,不用考虑分配效率、内存碎片等问题了。目前比较流行的malloc库有ptmalloc、jemalloc、scudo等。
1.5 进程运行状态
很多操作系统的书籍上都会讲进程的运行状态,有的讲的是三态,有的讲的是五态。其实两者并不矛盾,三态只有进程运行时的状态,五态把进程的新建和死亡状态也算上去了,如下图所示:

进程刚创建之后处于新建态,但是新建态不是持久状态,它会立马转变为就绪状态。然后进程就会一直处于就绪、执行、阻塞三态的循环之中。就绪态会由于进程调度而转为执行态;执行态会由于时间片耗尽而转为就绪态,也会由于等待某个事件而转为阻塞态;阻塞态会由于某个事件的发生而转为就绪态。最后进程可能会由于主动退出或者发生异常而死亡。死亡态也不是一个持久态,进程死亡之后就不存在了。
1.6 进程亲缘关系
所有进程都通过父子关系连接而构成一颗亲缘树,这颗树的树根是init进程(pid1)。Init进程是第一个用户空间进程,所有的用户空间进程都是init进程的子孙进程。Init进程的父进程是零号进程,零号进程是在代码中通过硬编码创建的,其它所有的进程都是通过fork创建的。这里为什么叫做零号进程呢?因为零号进程的职责发生过变化,在系统刚启动的时候,零号进程是BSP(bootstrapprocess),start_kernel函数就是在零号进程中运行的。当系统初始化完成的时候,零号进程退化为了idle进程。当我们只强调零号进程的身份而不关心它的职责的时候,就叫它零号进程。当后面我们强调它的idle职责的时候,就叫它idle进程。
零号进程有两个亲儿子,除了init之外,还有一个是kthreadd(pid2)。Kthreadd是一个内核线程,它是所有其它内核线程的父进程。内核线程比较特殊的点在于它只运行在内核空间,所以所有的内核线程都可以看做是同一个进程下的线程,因为内核空间只有一个。但是每个内核线程在逻辑意义上又是一个独立的进程,它们执行独立的任务,有着独立的进程人格。所以当我们说一个内核线程的时候,心里也要明白它是一个单独的进程,是一个只有主线程的单线程进程。
我们来画一下进程的亲缘关系:

进程除了父子这种血缘关系之外,还存在着家族关系。一个是大家族关系,会话组(session),一个是小家族关系,进程组(process
group)。会话组的产生来源于早期的大型计算机,当时一个公司或者一个科研单位只能买得起一台大型机。然后每个人都通过一个终端连接到这个大型机,用自己的用户名和密码登录上去。每个用户都有自己的用户id,一个用户运行的所有的程序构成了一个会话组。有了会话组的概念,就可以方便我们把一个用户运行的所有进程作为一个整体进行管理。进程组的产生来源于命令行操作的作业管理。什么是作业管理呢?就是把一行命令的执行整体作为一个作业。一行命令的执行不一定只有一个进程,比如命令ps -ef | grepbash,就有两个进程,我们需要有个概念把这两个进程作为一个整体来处理,这个概念就是进程组。有了进程组的概念,作业管理就比较方便了,比如Ctrl+C就是给当前正在执行的命令(进程组)发信号,进程组中的每个进程都会收到信号。
一个进程诞生的时候默认继承父进程的会话组和进程组,但是进程可以通过系统调用(setsid,setpgrp)创建新的会话组或者进程组。会话组的第一个进程叫做这个会话组的组长,进程组的第一个进程叫做这个进程组的组长,会话组的id等于会话组组长的pid,进程组的id等于进程组组长的pid。一个进程只有当它不是某个进程组组长的时候,它才可以调用setpgrp创建新的进程组,同时它也成为了这个新建的进程组的组长。这个也很好理解,只有臣子造反当皇帝,哪有皇帝自己造自己的反重新创建一个朝代的。同理,只有不是会话组组长的进程才能通过setsid创建新的会话组,并成为这个会话组组长。而且在这个新的会话组里也不能没有进程组啊,于是还会创建一个进程组,这个会话组组长还会成为这个新建的进程组的组长,这也要求了这个进程之前不能是进程组组长。所以只有既不是进程组组长又不是会话组组长的进程才能创建新的会话组。
任何一个进程,它必然属于某个进程组,而且只能同时属于一个进程组。任何一个进程,它必然属于某个会话组,而且只能属于一个会话组。任何一个进程组,它的所有进程必须都属于同一个会话组。一个进程所属的会话组只有两种来源,要么是继承而来的,要么是自己创建的,进程是不能转会话组的。不过一个进程是可以转进程组的,但是只能在同一个会话组中的进程组之间转。因此我们可以得出一个结论,一个会话组的所有进程肯定都是其会话组组长的子孙进程,一个进程组的所有进程一般情况下都是其进程组组长的子孙进程。
我们来画一下进程的家族关系:

二、进程的实现
明白了进程的基本概念之后,我们来看一看Linux是怎么实现进程的。按照标准的操作系统理论,进程是资源分配的单位,线程是程序执行的单位,内核里用进程控制块(PCB Process Control Block)来管理进程,用线程控制块(TCB Thread Control Block)来管理线程。那么Linux是按照这个逻辑来实现进程的吗?我们来看一下。
2.1 基本原理
Linux内核并不是按照标准的操作系统理论来实现进程的,在内核里找不到典型的进程控制块和线程控制块。内核里只有一个task_struct结构体,初学内核的人会很疑惑这是代表进程还是代表线程呢。之所以会这样,是由于历史原因造成的。Linux最开始的时候是不支持多线程的,也可以认为此时一个进程只能有一个线程就是主线程,因此线程就是进程,进程就是线程。所以最初的时候,task_struct既代表进程又代表线程,因为进程和线程没有区别。但是后来Linux也要支持多线程了,我们在1.2节中讨论过,多线程的实现方法可以在内核实现,也可以在用户空间实现,也可以同时实现,Linux选择的是在内核实现。为了最大限度地利用已有的代码,尽量不对代码做大的改动,Linux选择的方法是:task_struct既是线程又是进程的代理。注意这句话,task_struct既是线程又是进程的代理(不是进程本身)。Linux并没有设计单独的进程结构体,而是用task_struct作为进程的代理,这是因为进程是资源分配的单位,线程是程序执行的单位,同一个进程的所有线程共享相同的资源,因此我们让同一个进程下的所有线程(task_struct)都指向相同的资源不就可以了嘛。线程在执行的时候会通过task_struct里面的指针访问资源,同一个进程下的线程自然就会访问到相同的资源,而且这么做还有很大的灵活性。
我们下面再来强调一下这句话,以加深对这句话的理解。
task_struct既是线程又是进程的代理(不是进程本身)。
2.2 进程结构体
当我们明白了task_struct既是线程又是进程的代理之后,再来理解task_struct就容易多了。task_struct的字段由两部分组成,一部分是线程相关的,一部分是进程相关的,线程相关的一般是直接内嵌其它数据,进程相关的一般是用指针指向其它数据。线程代表的是执行流,所以task_struct的线程相关部分是和执行有关的,进程代表的是资源分配,所以task_struct的进程相关部分是和资源有关的。我们可以想一下和执行有关的都有哪些,和资源有关的都哪些?可以很轻松地想到,和执行有关的肯定是进程调度相关的数据啊(进程调度虽然叫进程调度,但实际上调度的是线程)。和资源相关的,最重要的首先肯定是虚拟内存啊,其次是文件系统。
下面我们来看一下task_struct的定义: linux-src/include/linux/sched.h
这个结构体定义有700多行,本文把一些暂时用不到的都删除了,现在还有70多行,我们来看一下大概都有哪些内容。先看和进程相关的,首先最重要的是虚拟内存空间信息mm、active_mm,这两个都是指针,对于用户线程来说两个指针的值永远都是相同的,同一个进程的所有线程都指向相同的mm,这个值就表明了同一个进程的线程都在同一个用户空间。其次比较重要的是文件管理相关的两个字段fs和files,也都是指针,fs代表的是文件系统挂载相关的,这个不仅是同进程的所有线程都相同,而且整个系统默认的值都一样,除非使用了mount 命名空间,files代表的是打开的文件资源,这个是同进程的所有线程都相同。然后我们再来看一下信号相关的,信号有的数据是进程全局的,有的是线程私有的,信号的处理是进程全局的,所以signal、sighand两个字段都是指针,同进程的所有线程都指向同一个结构体,信号掩码是线程私有的,所以blocked直接是内嵌数据。进程相关的数据基本就这些,下面我们来看一下线程相关的数据。首先是进程的运行退出状态,有几个字段,__state、on_cpu、cpu、exit_state、exit_code、exit_signal。然后是和线程调度相关的几个字段,有和优先级相关的rt_priority、static_prio、normal_prio、prio,有和调度信息统计相关的两个结构体,se、sched_info。还有两个非常重要的字段我们下一节讲。
2.3 进程标识符
task_struct里面有两个重要的字段pid、tgid。我们在用户空间的时候也有pid、tid,那么用户空间的pid是不是就是内核的pid呢,那tgid又是啥呢。很多初学内核的人会认为用户空间的pid就是内核的pid,刚开始我也是这么认为的,给我的内核学习带来了很大的困扰。实际上用户空间的tid是内核空间pid,用户空间的pid是内核空间的tgid,内核空间的tgid是内核里主线程的pid。为什么会这样呢?主要还是前面讲的问题,task_struct既是线程又是进程的代理,没有单独的进程结构体。当进程创建时,也就是进程的第一个线程创建时,会为task_struct分配一个pid,就是主线程的tid,然后进程的pid也就是字段tgid会被赋值为主线程的tid。此后再创建的线程都会继承父线程的tgid,所以在每个线程中都能直接获取进程的pid。
我们在这里画个图总结一下进程与线程的关系、pid与tgid之间的关系:
Linux里面虽然没有进程结构体,但是所有tgid相同、虚拟内存等资源相同的线程构成一个虚拟的进程结构体。创建进程的第一个线程(task_struct)就是同时在创建进程,其对应的mm_struct、files_struct、signal_struct等资源都会被创建出来。创建进程的第二个线程那就是纯粹地创建线程了。
2.4 进程的状态
进程的状态在Linux中是如何表示的呢?task_struct中有两个字段用来表示进程的状态,__state和exit_state,前者是总体状态,后者是进程在死亡时的两个子状态。
我们来看一下代码中的定义: linux-src/include/linux/sched.h
其中TASK_RUNNING代表的是Runnable和Running状态。在Linux中不是用flag直接区分Runnable和Running状态的,它们都用TASK_RUNNING表示,区分它们的方法是进程是否在运行队列的当前进程字段上。Blocked状态有两种表示,TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE,它们的区别是前者在睡眠时能被信号唤醒,后者不能被信号唤醒。表示死亡的状态是TASK_DEAD,它有两个子状态EXIT_ZOMBIE、EXIT_DEAD,这两个状态在3.6中讲解。
二、进程的实现
明白了进程的基本概念之后,我们来看一看Linux是怎么实现进程的。按照标准的操作系统理论,进程是资源分配的单位,线程是程序执行的单位,内核里用进程控制块(PCB Process Control Block)来管理进程,用线程控制块(TCB Thread Control Block)来管理线程。那么Linux是按照这个逻辑来实现进程的吗?我们来看一下。
2.1 基本原理
Linux内核并不是按照标准的操作系统理论来实现进程的,在内核里找不到典型的进程控制块和线程控制块。内核里只有一个task_struct结构体,初学内核的人会很疑惑这是代表进程还是代表线程呢。之所以会这样,是由于历史原因造成的。Linux最开始的时候是不支持多线程的,也可以认为此时一个进程只能有一个线程就是主线程,因此线程就是进程,进程就是线程。所以最初的时候,task_struct既代表进程又代表线程,因为进程和线程没有区别。但是后来Linux也要支持多线程了,我们在1.2节中讨论过,多线程的实现方法可以在内核实现,也可以在用户空间实现,也可以同时实现,Linux选择的是在内核实现。为了最大限度地利用已有的代码,尽量不对代码做大的改动,Linux选择的方法是:task_struct既是线程又是进程的代理。注意这句话,task_struct既是线程又是进程的代理(不是进程本身)。Linux并没有设计单独的进程结构体,而是用task_struct作为进程的代理,这是因为进程是资源分配的单位,线程是程序执行的单位,同一个进程的所有线程共享相同的资源,因此我们让同一个进程下的所有线程(task_struct)都指向相同的资源不就可以了嘛。线程在执行的时候会通过task_struct里面的指针访问资源,同一个进程下的线程自然就会访问到相同的资源,而且这么做还有很大的灵活性。
我们下面再来强调一下这句话,以加深对这句话的理解。
task_struct既是线程又是进程的代理(不是进程本身)。
2.2 进程结构体
当我们明白了task_struct既是线程又是进程的代理之后,再来理解task_struct就容易多了。task_struct的字段由两部分组成,一部分是线程相关的,一部分是进程相关的,线程相关的一般是直接内嵌其它数据,进程相关的一般是用指针指向其它数据。线程代表的是执行流,所以task_struct的线程相关部分是和执行有关的,进程代表的是资源分配,所以task_struct的进程相关部分是和资源有关的。我们可以想一下和执行有关的都有哪些,和资源有关的都哪些?可以很轻松地想到,和执行有关的肯定是进程调度相关的数据啊(进程调度虽然叫进程调度,但实际上调度的是线程)。和资源相关的,最重要的首先肯定是虚拟内存啊,其次是文件系统。
下面我们来看一下task_struct的定义: linux-src/include/linux/sched.h
这个结构体定义有700多行,本文把一些暂时用不到的都删除了,现在还有70多行,我们来看一下大概都有哪些内容。先看和进程相关的,首先最重要的是虚拟内存空间信息mm、active_mm,这两个都是指针,对于用户线程来说两个指针的值永远都是相同的,同一个进程的所有线程都指向相同的mm,这个值就表明了同一个进程的线程都在同一个用户空间。其次比较重要的是文件管理相关的两个字段fs和files,也都是指针,fs代表的是文件系统挂载相关的,这个不仅是同进程的所有线程都相同,而且整个系统默认的值都一样,除非使用了mount 命名空间,files代表的是打开的文件资源,这个是同进程的所有线程都相同。然后我们再来看一下信号相关的,信号有的数据是进程全局的,有的是线程私有的,信号的处理是进程全局的,所以signal、sighand两个字段都是指针,同进程的所有线程都指向同一个结构体,信号掩码是线程私有的,所以blocked直接是内嵌数据。进程相关的数据基本就这些,下面我们来看一下线程相关的数据。首先是进程的运行退出状态,有几个字段,__state、on_cpu、cpu、exit_state、exit_code、exit_signal。然后是和线程调度相关的几个字段,有和优先级相关的rt_priority、static_prio、normal_prio、prio,有和调度信息统计相关的两个结构体,se、sched_info。还有两个非常重要的字段我们下一节讲。
2.3 进程标识符
task_struct里面有两个重要的字段pid、tgid。我们在用户空间的时候也有pid、tid,那么用户空间的pid是不是就是内核的pid呢,那tgid又是啥呢。很多初学内核的人会认为用户空间的pid就是内核的pid,刚开始我也是这么认为的,给我的内核学习带来了很大的困扰。实际上用户空间的tid是内核空间pid,用户空间的pid是内核空间的tgid,内核空间的tgid是内核里主线程的pid。为什么会这样呢?主要还是前面讲的问题,task_struct既是线程又是进程的代理,没有单独的进程结构体。当进程创建时,也就是进程的第一个线程创建时,会为task_struct分配一个pid,就是主线程的tid,然后进程的pid也就是字段tgid会被赋值为主线程的tid。此后再创建的线程都会继承父线程的tgid,所以在每个线程中都能直接获取进程的pid。
我们在这里画个图总结一下进程与线程的关系、pid与tgid之间的关系:
Linux里面虽然没有进程结构体,但是所有tgid相同、虚拟内存等资源相同的线程构成一个虚拟的进程结构体。创建进程的第一个线程(task_struct)就是同时在创建进程,其对应的mm_struct、files_struct、signal_struct等资源都会被创建出来。创建进程的第二个线程那就是纯粹地创建线程了。
2.4 进程的状态
进程的状态在Linux中是如何表示的呢?task_struct中有两个字段用来表示进程的状态,__state和exit_state,前者是总体状态,后者是进程在死亡时的两个子状态。
我们来看一下代码中的定义: linux-src/include/linux/sched.h
其中TASK_RUNNING代表的是Runnable和Running状态。在Linux中不是用flag直接区分Runnable和Running状态的,它们都用TASK_RUNNING表示,区分它们的方法是进程是否在运行队列的当前进程字段上。Blocked状态有两种表示,TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE,它们的区别是前者在睡眠时能被信号唤醒,后者不能被信号唤醒。表示死亡的状态是TASK_DEAD,它有两个子状态EXIT_ZOMBIE、EXIT_DEAD,这两个状态在3.6中讲解。