ripgrep 是开源社区正在进行的 RIIR(re-write in Rust)工作的一个优秀成果。它旨在成为经典 grep 命令 的高级替代工具。
它的语法如下:
使用 ripgrep,可以不提供待搜索的文件名。如果没有提供文件名,那么就会搜索所有的文件。如果你不知道搜索的关键词在哪个文件中,那这种情况下是非常有用的。
当然,我们也可以使用 grep 搜索所有的文件,但是 ripgrep 不需要提供额外的参数。
什么是 ripgrep
ripgrep 是一个递归正则表达式模式匹配工具,它考虑了 gitignore。如果你的 gitignore 中有排除的文件或目录,那么 ripgrep 将会忽略它们,从而加快搜索的执行时间。
ripgrep 几个比较突出的特点如下:
在目录中递归搜索;
- 输出中不同颜色高亮显示;
- 支持多种编码格式,比如 UTF-8,SHIFT_JIS等;
- 可以在压缩文件的zip文件中搜索;
- 默认情况下会忽略隐藏文件,另外也会忽略 gitignore文件中的过滤设置。
你可以将其视同为 grep,但 ripgrep 搜索的是文件和文件内容,而不是 grep 所处理的原始字节流。
安装 ripgrep
大多数 Linux 系统中都预装了 grep,但是 ripgrep 并没有这样的特权,所有我们需要手动安装它。
ripgrep 在所有主流 Linux 发行版的存储库中都可用,所以我们可以使用包管理器来安装。
如果你是 Arch Linux 用户,可以使用如下命令安装:
Gentoo 用户使用如下命令安装 ripgrep:
Fedoras 或者 Red Hat 使用如下命令:
openSUSE(15.1及更新版本)用户使用如下命令:
Debian Buster(v10)或更高版本的用户,可使用 apt;Ubuntu Cosmic Cutlefish(18.10)或更高级版本也可以使用发行版的官方存储库:
使用 ripgrep 命令
如果你熟悉 grep 命令,就会发现 ripgrep 与其工作原理类似。它接受一个字符串和文件名作为参数,运行时会搜索文件,并显示输入字符串与文件内容匹配的位置。
基本搜索
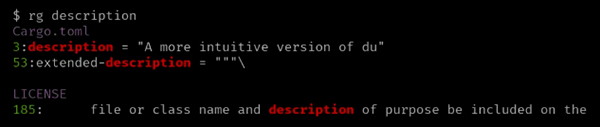
如下例子,我们在 Cargo.html 中搜索单词 description:
ripgrep 将在指定的文件中搜索,结果将显示匹配的文本和行号:

如果搜索的是多个文件(如果不指定任何文件,它将搜索所有文件),那么ripgrep在搜索结果中还会显示文件名:
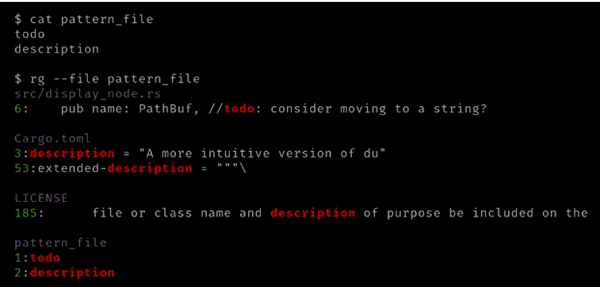
或者,可以使用 --file 选项,其中包含要搜索的关键词(表达式)。当你要搜索一组关键词时,可以将其放在一个文件中,然后使用 --file 选项指定:
前后文搜索
有时候,有匹配的前后文是很好的显示方式,特别是在代码库中搜索时。使用前后文搜索,可以使用 -C 或者 --context 选项,该选项接受一个数值,并显示匹配值的前一行和后一行:
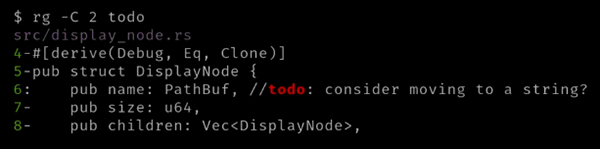
有时,我们只希望看到上面的几行,包括匹配的行;还有时候,我们只需要下面的行,包括匹配的行。使用选项 -A,或者 --after-context,后跟一个数值,将显示每个匹配行后的几行:

至于显示匹配行前面的几行,可以使用 -B 或者 --before-context,再提供一个数值(即行数):

列选项
关于 ripgrep 提供的列,有几个选项。
如果你使用的是 vim,可以使用 --column 选项,这样将在结果中显示匹配文本在哪一列,以"行:列"的方式显示:

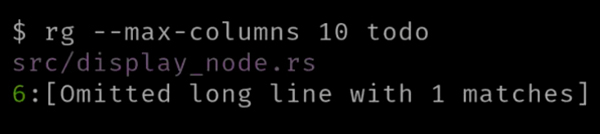
与列相关的另一个选项是 -M 或 --max-columns,它取最大列数的值。如果匹配行的列超过最大值,它会告诉你某一特定行在输出到终端时被忽略:
其他选项
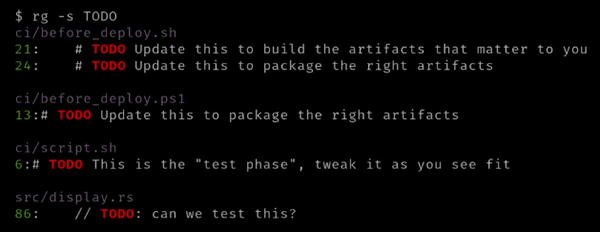
除了上文中提到的,ripgrep 中还有其他几个选项。比如:可以使用 -s 或 --case-sensitive 选项来区分大小写:
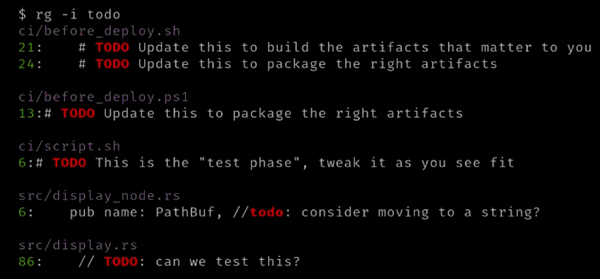
如果不想区分大小写,可以使用 -i 或 --ignore-case :
另外,如果你要搜索的目标文件特别大,可以启用多线程进行搜索。使用 -j 或 --threads 选项,后跟一个数值:
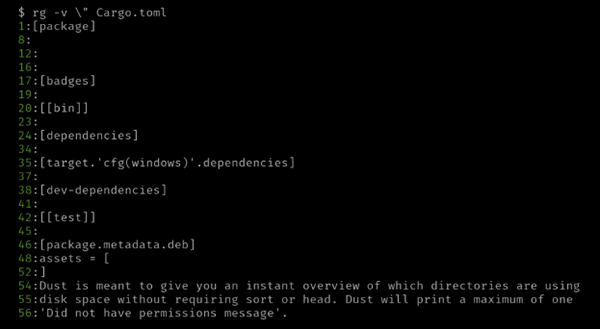
在搜索中要排除某个关键词或表达式,可以使用 -v 或 --invert-match 选项:
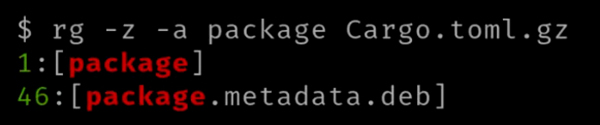
ripgrep 可以实现在压缩文件(如果压缩文件是文本文件)中进行搜索,使用 -z 或 --search-zip 选项。其通常与 -a 选项一起使用,-a 选项会将二进制文件也当作文本文件。
ripgrep 是一个非常好用的工具,虽然它暗指要替代 grep,但实际上并不会取代 grep,因为它们的搜索目标是不同的。我们可以在日常工作中按需求来使用。
以上就是本次分享全部内容,欢迎讨论。