一、问题背景
二、分析过程
- 2.1 参数配置
- 2.2 定位过程
- 2.3 JVM分析
- 2.4 问题分析
三、解决方案
一、问题背景
prometheus监控报警生效后,某服务每天的上午 8-12 点间会有fullGC的报警;
排查并解决该问题;
二、分析过程
2.1 参数配置
JVM 参数配置如下:
新生代大小:1G;
新生代垃圾收集器:ParNewGC;
老年代大小:2G;
老年代垃圾收集器:ConcMarkSweepGC;
CMS触发条件:老年代内存占用达到80%及以上;
2.2 定位问题
1.由于报警的时间点都集中在上午的 8-12 点之间,怀疑是由于某个定时任务造成的;
2.定位具体的定时任务,有两个定时任务的时间设置基本满足;
3.确定具体的任务
确认的两个思路:
1.通过日志确认定时任务的执行时长等;
2.将2个定时任务分别指定不同的机器执行观察;
排查任务执行时间:
任务1 : 很快,几乎不处理业务逻辑;
任务2: 执行约35分钟时间;
8:10分开始,8:45分结束;
基本确定为第二个定时任务导致FullGC;
2.3 JVM分析
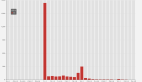
2.3.1 单天监控图
内存趋势
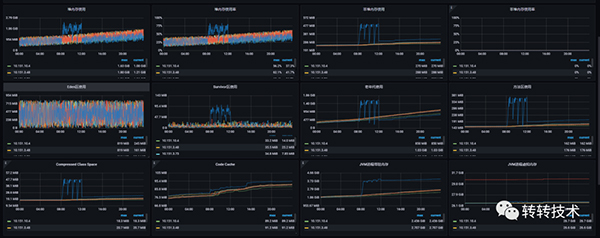
GC趋势
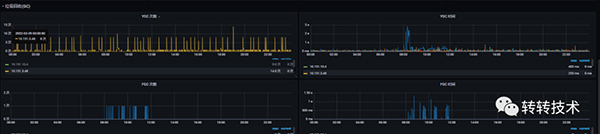
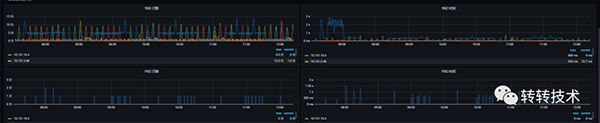
2.3.2 报警时间段监控图
内存趋势
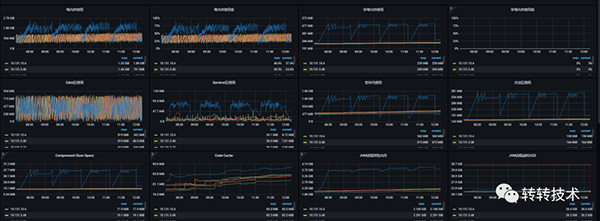
GC趋势
2.3.3 图表分析
2.3.3.1 老年代变化
现象
1.任务执行过程中:老年代有明显增长,并且FullGC后并没有特别明显的下降,只有些许下降;
2.任务执行结束后:下次任务开始执行,进行FullGC后,会降到跟其他机器一样的水平,甚至内存占用更低;
备注
新生代到老年代的几种情况
1:大对象;
2:年龄足够长,cms没有设置,默认是6,通过jinfo确认也是6;
3:suvivor区不足以存放YGC后的存活对象,直接使用担保策略晋升到老年代;
分析
任务执行过程中,YGC平均1分钟执行5次,很多对象都会达到最大晋升年龄6,晋升到老年代;
并且由于任务没有结束,对象还有引用,所以FullGC之后并没有明显下降;
上次任务结束后,老年代并没有像suvivor区一样有一段时间的低内存占用,主要是直到下次任务开始后才会触发新一次的FullGC,触发后,老年代的对象由于任务结束后没有引用了,所以会正常回收;
2.3.3.2 survivor区变化
suvivor区内存总共100M,任务执行过程中,平均占用 80M;高的时候会飙升到90以上,所以这个过程中YGC也变得很频繁,平均1分钟5次;
2.3.3.3 非堆内存/方法区/compressed class cach变化
使用 jstat 分别统计了两台机器的gc统计,两者最大的区别在于 执行过定时任务的机器的MC(方法区大小) 以及 CCSC(压缩类空间大小) 明显比没有执行过定时任务的机器高很多;

任务执行过程中方法区的内存占用会跟老年代的曲线保持一致,这几个区的回收也是靠老年代,这个通过grafana平台的监控图也可以看出来;
2.3.3.4 dump文件分析
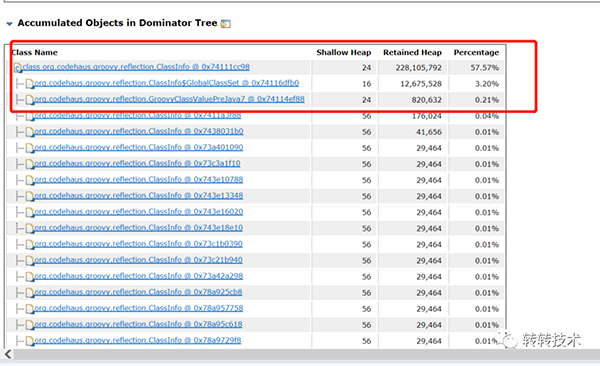
groovy相关的类占比57.57%;
2.4 参数配置
java 与 groovy 版本
代码中使用到groovy的地方:同样是这个定时任务,下发任务时,表达式检验是否满足下发条件,表达式是用groovy进行处理的;
基本上可以定位问题在groovy脚本的加载处,groovy不合理使用会导致,动态生成很多新类,使得metaspace的不断被占用;
class 对象在 1.8 及以后存放在 metaspace 中,也就是堆外内存。
groovy每执行一次,会将传入的文本动态加载成一个脚本类,入参是文本时,生成的文件名中包含了一个自增的数值,也就是每执行一次都会动态生成一个新类,1个用户7个任务规则校验 * 15962个用户 = 111734个
GroovyShell 在内部,它使用groovy.lang.GroovyClassLoader,这是在运行时编译和加载类的核心。
GroovyClassLoader 保留对其创建的所有类的引用,而 class 对象只有在被加载的 classloader 被回收的时候才会被回收,因此很容易造成内存泄漏;
综上分析,groovy 错误的使用方式导致 class 对象常驻堆外内存且随着调用频率增长。
三、解决方案
1、每个脚本共用一个 GroovyShell 对象,不能使用 for 的方式,循环创建使用;
2、每次执行完释放对象 shell.getClassLoader().clearCache();