本文介绍了Littlefs中的Commit机制,包括Commit、Compact、Split操作的过程,怎样写入Tag和数据,怎样计算CRC,以及相应的异常情况处理等。

想了解更多关于开源的内容,请访问:
51CTO 开源基础软件社区
https://ost.51cto.com
前言
回顾littlefs的存储结构,其中最为核心的是元数据。元数据以tag为单元进行信息的存储,以commit的方式进行信息的更新。当littlefs中进行文件、目录的创建、修改、删除等一系列操作时,实际上都是通过向元数据中进行commit操作的方式实现。本文将对littlefs中commit机制进行介绍。
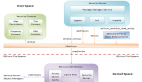
一、commit过程
commit具体的过程如下图所示:
![#littlefs原理分析#[二]commit机制-开源基础软件社区](https://dl-harmonyos.51cto.com/images/202210/d93efcd88cadcb62e8d3585dd92a82d13557b9.png?x-oss-process=image/resize,w_547,h_125 "#littlefs原理分析#[二]commit机制-开源基础软件社区")
每一次commit时都会向元数据对中写入一系列的tag和数据,并计算CRC。因为在commit时总是会进行CRC计算,并且从元数据中读取数据时会做校验,因此一次commit是一次原子操作。
下面以具体的案例对commit过程进行说明:
1、超级块的创建
当littlefs进行格式化操作时,会进行超级块的创建。超级块创建主要是在根目录对应元数据对的块中进行commit:
![#littlefs原理分析#[二]commit机制-开源基础软件社区](https://dl-harmonyos.51cto.com/images/202210/74bfd2649adaaf96a6145858a76a5c6a00434b.png?x-oss-process=image/resize,w_471,h_203 "#littlefs原理分析#[二]commit机制-开源基础软件社区")
如上图,超级块创建时调用lfs_dir_commit函数写入了CREATE、SUPERBLOCK、INLINESTRUCT和CRC类型的tag。lfs_dir_commit函数中进行了commit的实际写入操作,其主要分为以下两个步骤:
- 将tag和对应的数据依次写入元数据对应块中。
- 计算CRC,并接着将其tag和CRC数据写入元数据对应块中。
超级块创建相关函数:
lfs_format(lfs_t *lfs, const struct lfs_config *cfg)
|-> lfs_rawformat(lfs_t *lfs, const struct lfs_config *cfg)
| // 1. 分配根目录,其块号为0,1
|-> lfs_dir_alloc(lfs, &root);
|
| // 2. 通过commit创建超级块
|-> lfs_superblock_t superblock = {
| .version = LFS_DISK_VERSION,
| .block_size = lfs->cfg->block_size,
| .block_count = lfs->cfg->block_count,
| .name_max = lfs->name_max,
| .file_max = lfs->file_max,
| .attr_max = lfs->attr_max,
| };
| lfs_dir_commit(lfs, &root, LFS_MKATTRS(
| {LFS_MKTAG(LFS_TYPE_CREATE, 0, 0), NULL},
| {LFS_MKTAG(LFS_TYPE_SUPERBLOCK, 0, 8), "littlefs"},
| {LFS_MKTAG(LFS_TYPE_INLINESTRUCT, 0, sizeof(superblock)),
| &superblock}));
(1)tag和相应数据的写入
![#littlefs原理分析#[二]commit机制-开源基础软件社区](https://dl-harmonyos.51cto.com/images/202210/74f6bf54737f56615c66123872adc520fea2cc.png?x-oss-process=image/resize,w_631,h_255 "#littlefs原理分析#[二]commit机制-开源基础软件社区")
如上图,在commit过程中,ptag用于进行tag的异或运算,其初始化值为0xffffffff。ptag会依次与将要commit的tag(如上图中的tagA、tagB、tagC)进行异或运算,然后将运算后的结果存储到块中。同时每写一个tag后,将其对应的数据也进行写入。
相关函数分析:
lfs_dir_commitattr(lfs_t *lfs, struct lfs_commit *commit,
| lfs_tag_t tag, const void *buffer)
| // 1. 将ptag和tag进行异或运算
| // 注:这里将tag的有效位置为了0,表示tag有效,并且tag为大端存储
|-> lfs_tag_t ntag = lfs_tobe32((tag & 0x7fffffff) ^ commit->ptag);
|
| // 2. 写入异或后的ntag
|-> lfs_dir_commitprog(lfs, commit, &ntag, sizeof(ntag));
|
| // 3. 写入对应数据
|-> lfs_dir_commitprog(lfs, commit, buffer, dsize-sizeof(tag));
(2)CRC的写入
commit过程中,当写入tag(异或后的tag)或数据时,均会进行逐字节CRC的计算。最后commit完成后,再写入相应的CRC tag和对应的CRC值。同时为了写入对齐,在CRC tag后会设置相应的padding。
CRC计算的范围为从本次commit起始的tag和数据,一直到CRC tag(包括CRC tag)。
写入CRC后块中布局如下图:
![#littlefs原理分析#[二]commit机制-开源基础软件社区](https://dl-harmonyos.51cto.com/images/202210/049215606a18824d0ee422e3535e574e7b458c.png?x-oss-process=image/resize,w_301,h_141 "#littlefs原理分析#[二]commit机制-开源基础软件社区")
相关函数分析:
// 该函数用于写入tag或数据,每当调用该函数时都会做CRC的计算
lfs_dir_commitprog(lfs_t *lfs, struct lfs_commit *commit,
| const void *buffer, lfs_size_t size)
| // 1. 将传入的tag或tag对应数据写入块中
|-> lfs_bd_prog(lfs,
| &lfs->pcache, &lfs->rcache, false,
| commit->block, commit->off ,
| (const uint8_t*)buffer, size)
|
| // 2. 计算CRC和更新偏移
|-> commit->crc = lfs_crc(commit->crc, buffer, size);
| commit->off += size;
// 该函数用于写入CRC tag和padding
lfs_dir_commitcrc(lfs_t *lfs, struct lfs_commit *commit)
| // 1. 创建CRC tag,并异或后存储于footer[0]中
| // 这里tag的size设置为了noff - off,实际上是包含了padding的大小
| // littlefs中没有通过填充数据的方式来设置padding,而是设置其tag的size进行标记
|-> tag = LFS_MKTAG(LFS_TYPE_CRC + reset, 0x3ff, noff - off);
| uint32_t footer[2];
| footer[0] = lfs_tobe32(tag ^ commit->ptag);
|
| // 2. 计算CRC并将CRC值存入footer[1]中
| // 这里是最后一次计算CRC,前面的tag和数据已经在写入时计算,只差CRC tag
|-> commit->crc = lfs_crc(commit->crc, &footer[0], sizeof(footer[0]));
| footer[1] = lfs_tole32(commit->crc);
|
| // 3. 写入CRC tag和CRC值到块中
|-> lfs_bd_prog(lfs,
| &lfs->pcache, &lfs->rcache, false,
| commit->block, commit->off, &footer, sizeof(footer));
(3)crc的计算
littlefs中crc计算核心函数如下:
uint32_t lfs_crc(uint32_t crc, const void *buffer, size_t size) {
static const uint32_t rtable[16] = {
0x00000000, 0x1db71064, 0x3b6e20c8, 0x26d930ac,
0x76dc4190, 0x6b6b51f4, 0x4db26158, 0x5005713c,
0xedb88320, 0xf00f9344, 0xd6d6a3e8, 0xcb61b38c,
0x9b64c2b0, 0x86d3d2d4, 0xa00ae278, 0xbdbdf21c,
};
const uint8_t *data = buffer;
for (size_t i = 0; i < size; i++) {
crc = (crc >> 4) ^ rtable[(crc ^ (data[i] >> 0)) & 0xf];
crc = (crc >> 4) ^ rtable[(crc ^ (data[i] >> 4)) & 0xf];
}
return crc;
}本文中不对crc的原理进行具体介绍,有兴趣的读者可参考以下链接:
littlefs中crc计算算法的特点是采用了32位的crc结果,输入数据以4bit为单位进行计算。其中还用到了lookup table进行加速,因为输入的数据以4bit为单位进行计算,每次有2^4即16种可能的输入,所以该lookup table的长度为16。从lookup table中还可看出该crc算法对应的多项式值为0x1db71064。
2、tag的遍历和写入总结
与遍历并写入tag等数据相关的函数为lfs_dir_traverse,该函数被lfs_dir_commit调用。该函数只用于commit等需要写入tag数据的过程,不用于遍历获取数据。其流程如下:
![#littlefs原理分析#[二]commit机制-开源基础软件社区](https://dl-harmonyos.51cto.com/images/202210/959fb6a168399a47907216093763803fff50e2.png?x-oss-process=image/resize,w_232,h_432 "#littlefs原理分析#[二]commit机制-开源基础软件社区")
代码分析如下:
static int lfs_dir_traverse(lfs_t *lfs,
| const lfs_mdir_t *dir, lfs_off_t off, lfs_tag_t ptag,
| const struct lfs_mattr *attrs, int attrcount,
| lfs_tag_t tmask, lfs_tag_t ttag,
| uint16_t begin, uint16_t end, int16_t diff,
| int (*cb)(void *data, lfs_tag_t tag, const void *buffer), void *data) {
|-> while (true) {
| // 1. 从磁盘或attrs中获取下一个tag和相应数据,如果没有则结束
| // attrs中保存的是将要commit的tag和相应数据
| lfs_tag_t tag;
| const void *buffer;
| struct lfs_diskoff disk;
| // 1.1 如果在磁盘偏移范围内,则从磁盘中获取下一个tag和数据
| // 一般进行commit时会将偏移设置到磁盘末尾,不从磁盘中获取之前的tag
| // 只有如compact等过程中才从磁盘中获取之前的tag来写入
|-> if (off+lfs_tag_dsize(ptag) < dir->off) {
| off += lfs_tag_dsize(ptag);
| ...
|
| tag = (lfs_frombe32(tag) ^ ptag) | 0x80000000;
| disk.block = dir->pair[0];
| disk.off = off+sizeof(lfs_tag_t);
| buffer = &disk;
| ptag = tag;
| } else if (attrcount > 0) {
| // 1.2 从attrs中获取下一个tag和数据
| // attrs中保存的是将要commit的新的tag和数据
|-> tag = attrs[0].tag;
| buffer = attrs[0].buffer;
| attrs += 1;
| attrcount -= 1;
| } else {
| // 1.3 否则结束
|-> return 0;
| }
|
| // 2. 使用tmask和ttag参数过滤掉不想要写入的tag
|-> lfs_tag_t mask = LFS_MKTAG(0x7ff, 0, 0);
| if ((mask & tmask & tag) != (mask & tmask & ttag)) {
| continue;
| }
|
| // 3. 去除冗余tag等
| if (lfs_tag_id(tmask) != 0) {
| int filter = lfs_dir_traverse(lfs,
| dir, off, ptag, attrs, attrcount,
| 0, 0, 0, 0, 0,
| lfs_dir_traverse_filter, &tag);
| if (filter < 0) {
| return filter;
| }
|
| if (filter) {
| continue;
| }
|
| if (!(lfs_tag_id(tag) >= begin && lfs_tag_id(tag) < end)) {
| continue;
| }
| }
|
| // 4. 处理一些特殊情况
| if (lfs_tag_type3(tag) == ...) {
| ...
| } else {
| // 5. 调用cb回调函数进行写入
|-> cb(data, tag + LFS_MKTAG(0, diff, 0), buffer);
| ...
| }
| }
}
二、compact过程
当commit时,如果元数据对应块中的空间不够,则会尝试进行compact操作。如下图:
![#littlefs原理分析#[二]commit机制-开源基础软件社区](https://dl-harmonyos.51cto.com/images/202210/8141a153440fd41b2d08619624c19cb13a580c.png?x-oss-process=image/resize,w_547,h_174 "#littlefs原理分析#[二]commit机制-开源基础软件社区")
上图中左边元数据块中有两个commit,其中tag A’是tag A的更新版本。当commit一个tag B’作为tag B的更新版本后,如右图中右边的元数据块,冗余的tag A和tag B被去除,只剩下一个commit。
如果compact后元数据块中的空间足够的话,在进行完compact操作之后的元数据块中就只会剩下一个CRC tag,即只有一个commit。compact的主要过程其实就是筛除冗余的tag和数据之后,将剩下的tag和数据作为一次commit写入同元数据对中的另一个块中。
1、compact去除内容
下面对compact过程中具体会去除的tag和相应数据进行说明。
compact过程中调用了lfs_dir_traverse进行去除冗余tag并写入:
lfs_dir_compact(lfs_t *lfs,
| lfs_mdir_t *dir, const struct lfs_mattr *attrs, int attrcount,
| lfs_mdir_t *source, uint16_t begin, uint16_t end)
|-> ...
|
| // 去重并写入tag
| // 这里使用了LFS_TYPE_NAME的tag类型进行过滤
|-> lfs_dir_traverse(lfs,
| source, 0, 0xffffffff, attrs, attrcount,
| LFS_MKTAG(0x400, 0x3ff, 0),
| LFS_MKTAG(LFS_TYPE_NAME, 0, 0),
| begin, end, -begin,
| lfs_dir_commit_commit, &(struct lfs_dir_commit_commit){
| lfs, &commit});
|
|-> ...
在lfs_dir_traverse中用下面的逻辑进行筛选tag:
static int lfs_dir_traverse(lfs_t *lfs,
| const lfs_mdir_t *dir, lfs_off_t off, lfs_tag_t ptag,
| const struct lfs_mattr *attrs, int attrcount,
| lfs_tag_t tmask, lfs_tag_t ttag,
| uint16_t begin, uint16_t end, int16_t diff,
| int (*cb)(void *data, lfs_tag_t tag, const void *buffer), void *data) {
|-> ...
|
|-> lfs_tag_t mask = LFS_MKTAG(0x7ff, 0, 0);
| if ((mask & tmask & tag) != (mask & tmask & ttag)) {
| continue;
| }
|-> ...
其中,mask为LFS_MKTAG(0x7ff, 0, 0),tmask为LFS_MKTAG(0x400, 3ff, 0),ttag为LFS_MKTAG(LFS_TYPE_NAME, 0, 0)即LFS_MKTAG(0, 0, 0),则筛选逻辑可简化为:
if ((LFS_MKTAG(400, 0, 0) & tag) != LFS_MKTAG(0, 0, 0)) {
continue;
}总结有以下类型的tag会被去除:
- LFS_TYPE_SPLICE:包括CREATE和DELETE
- LFS_TYPE_TAIL:包括SOFTTAIL和HARDTAIL
- LFS_TYPE_GLOBALS:即MOVESTATE
- LFS_TYPE_CRC
2、compact写入过程
与commit中tag和数据的写入过程类似,compact中的写入过程包括:
- 写入更新后的revision count。
- 写入去除冗余后的tag和数据。
- 如果原来有SOFTTAIL或HARDTAIL,则将原来最后一个TAIL补充写入。因此,compact过程对目录的遍历方式无影响,具体目录的遍历见后面的文章。
- 如果原来有MOVESTATE且进行异或之后不为0,则将异或后的gstate作为MOVESTATE tag补充写入。gstate相关机制见后面的文章。
- 写入CRC。
相关函数分析:
lfs_dir_compact(lfs_t *lfs,
| lfs_mdir_t *dir, const struct lfs_mattr *attrs, int attrcount,
| lfs_mdir_t *source, uint16_t begin, uint16_t end)
| // 1. 检查剩余空间,如果不够则进行split操作
|-> lfs_dir_split(lfs, dir, attrs, attrcount,
| source, begin+split, end)
|
| // 2. revision count + 1,并写入
|-> dir->rev += 1;
| lfs_bd_erase(lfs, dir->pair[1]);
| lfs_dir_commitprog(lfs, &commit,
| &dir->rev, sizeof(dir->rev));
|
| // 3. 去重并写入tag
|-> lfs_dir_traverse(lfs,
| source, 0, 0xffffffff, attrs, attrcount,
| LFS_MKTAG(0x400, 0x3ff, 0),
| LFS_MKTAG(LFS_TYPE_NAME, 0, 0),
| begin, end, -begin,
| lfs_dir_commit_commit, &(struct lfs_dir_commit_commit){
| lfs, &commit});
|
| // 4. 补充写入tail
|-> if (!lfs_pair_isnull(dir->tail)) {
| ...
| lfs_dir_commitattr(lfs, &commit,
| LFS_MKTAG(LFS_TYPE_TAIL + dir->split, 0x3ff, 8),
| dir->tail);
| ...
| }
|
| // 5. 补充写入move state
|-> if (!lfs_gstate_iszero(&delta)) {
| ...
| lfs_dir_commitattr(lfs, &commit,
| LFS_MKTAG(LFS_TYPE_MOVESTATE, 0x3ff,
| sizeof(delta)), &delta);
| ...
| }
|
| // 6. 计算CRC
|-> lfs_dir_commitcrc(lfs, &commit);
三、split过程
当commit时,进行compact操作后仍空间不足,则会进行split操作,将元数据对划分为多个块进行存储:
![#littlefs原理分析#[二]commit机制-开源基础软件社区](https://dl-harmonyos.51cto.com/images/202210/051f7c73637c4c7aab64848f2181661a80902a.png?x-oss-process=image/resize,w_547,h_335 "#littlefs原理分析#[二]commit机制-开源基础软件社区")
如上图,左图中右边的元数据块为最新的元数据块,其中包含一个commit的内容,即tag A’和tag B’。当再次commit tag C和tag D时,一个元数据块装不下,就会进行split操作。split操作在第一个元数据块commit的末尾加入一个HARDTAIL类型的tag,指向一个新的元数据块。新的元数据块中再装入剩下的tag和数据。
split操作中会递归调用compact和split,使得在一次split的容量无法满足commit需求的时候,进行多次split。
相关函数分析:
lfs_dir_split(lfs_t *lfs,
| lfs_mdir_t *dir, const struct lfs_mattr *attrs, int attrcount,
| lfs_mdir_t *source, uint16_t split, uint16_t end)
| // 1. 重新分配新的块,用来存储split后的数据
|-> lfs_dir_alloc(lfs, &tail);
|
| // 2. 将split部分数据再进行compact操作
| // 该调用会递归调用compact和split操作直到commit完成或失败
|-> lfs_dir_compact(lfs, &tail, attrs, attrcount, source, split, end);
|
| // 3. 更新目录信息
|-> dir->tail[0] = tail.pair[0];
| dir->tail[1] = tail.pair[1];
| dir->split = true;
四、异常情况
前文中提到每次commit之后,都会写入计算的CRC tag,用于校验。commit过程因此也是一次原子操作。当commit过程中发生掉电等情况导致commit过程失败时,磁盘中元数据末尾虽然有写入的部分tag和数据,但没有最终的CRC tag,因此当进行tag的遍历等操作时并不会将这次commit视为有效。compact过程和split过程中也类似,只要没有最终写入CRC tag,便不会被视为完成一次commit。如下图:
![#littlefs原理分析#[二]commit机制-开源基础软件社区](https://dl-harmonyos.51cto.com/images/202210/e26ea92089b1c197f686795d7d1d57730408dc.png?x-oss-process=image/resize,w_547,h_151 "#littlefs原理分析#[二]commit机制-开源基础软件社区")
另外,当split为多个块时,由前文中相关分析,compact和split会递归调用,并提前检查块大小是否满足需求和分配相应块,最终写入多个块。split过程时若没有足够的块,则会报错,且并不写入实际内容。split过程时若中途commit失败,则会导致上一个元数据块末尾的HARDTAIL指向的块中没有有效的CRC tag,进行遍历时会直接返回错误,如下图:
![#littlefs原理分析#[二]commit机制-开源基础软件社区](https://dl-harmonyos.51cto.com/images/202210/42f0169918fe78e9d87196ef23689dd43018cc.png?x-oss-process=image/resize,w_547,h_335 "#littlefs原理分析#[二]commit机制-开源基础软件社区")
总结
本文介绍了littlefs中的commit机制,包括commit、compact、split操作的过程,怎样写入tag和数据,怎样计算CRC,以及相应的异常情况处理等。commit是一个写入元数据的过程,后面的文章将会介绍怎样读取元数据,从tag中获取目标信息。
想了解更多关于开源的内容,请访问:
51CTO 开源基础软件社区
https://ost.51cto.com。