












C语言之所以适合写操作系统,就在于它的内存布局简单:
1,所有的全局变量都被常量初始化,
2,不需要运行时的状态,
3,也不需要在main()函数之前运行额外的初始化代码。
操作系统的初始化是很复杂的。
在C语言写成的内核main()函数运行之前,操作系统要运行一段很复杂的汇编代码,以完成内核的内存初始化。
这段汇编代码包含着很多重要的内核全局数据,它是由内核作者精心定制的,没法由编译器自动生成。
对于内核程序员来说,编译器做的事越少越好,但是又不能像汇编器那么少
C语言适合写操作系统,我觉得跟丹尼斯-里奇发明它的目的就是为了写Unix有关:不好用的地方已经被优化过了。
1970年,丹尼斯-里奇怎么一边改unix系统的代码、一边改cc编译器的代码的咱就不回忆了。
这里说说C语言和操作系统的内存布局。
1.C语言的内存布局。
C语言编译连接之后的可执行文件,分为:
1) 代码段(.text),
2) 只读数据段(.rodata),
3) 数据段(.data),
4) 堆 (heap),
5) 栈 (stack),
其中需要存储在文件里的只有前3个,
后2个在进程运行期间是动态变化的临时数据,并不需要存储在文件里。
代码段的权限是只读+可执行,
只读数据段的权限是只读,
数据段、堆、栈的权限都是可读可写的,但不能运行。
如果系统内核发现了进程的内存权限是错误的,那么就是段错误:信号是SIGSEGV。
*("hello") = 1;
这种代码肯定是“段错误”的,因为常量字符串位于只读数据段,它的内容是不可写的。
通过缓冲区溢出来覆盖栈的返回地址的黑客代码,也会被系统内核发现运行地址不在代码段,所以也是段错误。
2.内核的内存布局。
内核的内存布局,包含这几个重要的全局数据:
1)内核页表
它是内核的虚拟内存与物理内存的映射。
在开启分页机制之前,就要设置好内核页表的前几页:
至少要把内核代码所在的内存空间映射到页表里,否则开启分页机制时就直接出错了。
在32位机上,它是由页目录-页表构成的2级数组:
页目录里的每一项记录每个页表的物理地址,页表里的每一项记录每个内存页的物理地址。
在64位机上页表的结构更为复杂,intel手册上有:我没仔细看过,有兴趣的可以看看。
1个内存页是4096字节,所以物理地址的最低12位全是0,用来记录每个页的读写权限。
页目录里每项的最低12位,用于记录它对应的整个页表的读写权限。
1个页表记录1024个页,每个页4096字节,所以1个页表管理4M的物理内存。
2)中断向量表
它存放各种硬件中断、以及int 0x80软件中断的处理函数,也叫中断服务例程(irq)。
int 0x80软件中断,就是Linux系统调用的中断号。
当然,在64位机上,直接使用syscall汇编指令就行。
syscall的软件中断机制,是intel在64位上又新造的一种进入CPU ring0特权级的指令,使用方式跟之前的int指令不大一样。
我怀疑intel的CPU研发也是有KPI的,怪不得Linus大牛也经常吐槽intel的CPU设计。
一个版本加一个新的指令,纯属给系统软件的开发者找难题
中断向量表,也是个256项的数组,每项都是某个中断的函数指针。
在中断被触发之后,CPU就是靠这个数组去查找对应的中断处理函数的。
3)全局描述符表
它描述的是内核的内存布局,每项8个字节,共256项。
但实际上,只需要使用前5项就行:
0x0,不使用,
0x8,内核代码段,
0x10,内核数据段,内核堆栈段,它们2个的权限一样,可以共用一项。
0x20,任务门的描述项,
0x28,局部描述符表的描述项。
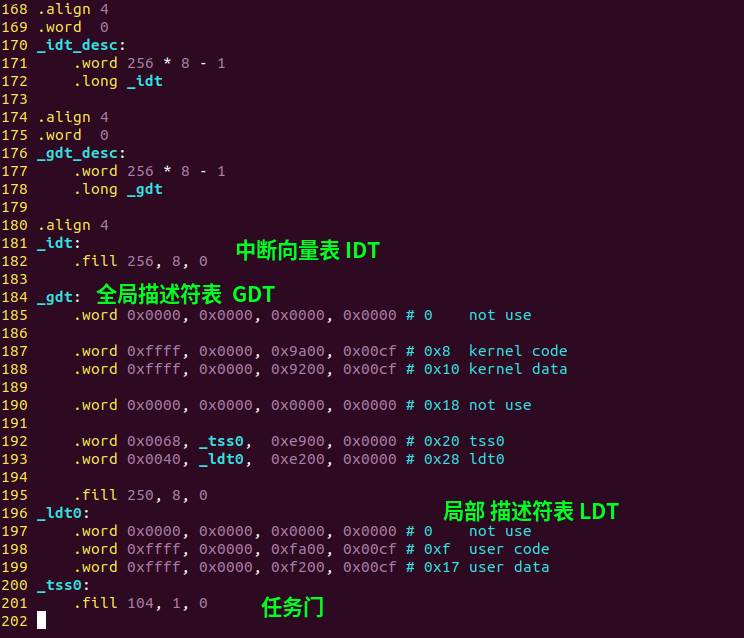
siska内核demo的内存布局
因为每项都是8字节,所以地址都是8的倍数。
4)局部描述符表
它是用于进程的,进程因为跟内核的权限不同,所以进程的段选择符都在局部描述符表里:
内核的段选择符是0x8,进程的是0xf。
段寄存器CS、DS、SS,到了保护模式下都成了段选择符,真正的内存地址在GDT表里。
在16位的实模式下,它们才存储真正的段的内存地址。
5)任务门
CPU把每个进程看做一个任务,所以要切换进程时需要任务门的描述结构。
它是104个字节。
但是,Linux系统的进程切换是软切换:任务门的描述结构只在系统初始化时加载一次,具体的进程切换时只切换页表和内核栈,然后就可以骗过CPU了
重新加载任务门的时间消耗比较大,而软切换的时间消耗比较小。
intel的这个设计,也是不受Linus大牛待见的设计之一
6)系统调用表
它也是一个大数组,它的每一项也是函数指针。
系统调用的入口是int 0x80软件中断(64位机上是syscall指令)。
进入内核之后,每个号码对应一个系统调用。
open()、close()、write()、read(),这些系统调用都有各自的号码,这些号码就是系统调用表的数组索引。
如果open()的系统调用号码是i,那么open()在内核里实际运行的就是这行代码:
syscall_table[i]();
7)物理内存的管理数组
物理内存的管理结构,是一个很大的一维数组。
假设物理内存有4G,1个内存页是4K,那么这个数组的元素个数就是1024x1024,1M。
数组的每一项,记录1个物理内存页的状态。
如果每项是4个字节的话,那么管理效率就是:(4096-4) / 4096。
管理数据所占的字节数越多,对物理内存的浪费越大。
get_free_pages()函数,就是通过查看这个数组来分配物理内存页的。
因为内核是一个高并发环境,这个管理结构里必须要有自旋锁,以控制多个CPU的并发访问。
自旋锁+引用计数就至少8字节,所以这个数组也是非常浪费内存的。
如果多个线程之间要共享内存,那么只要把同一个物理内存页映射到这几个线程的页表里,然后增加物理内存页的引用计数就行:
这就是共享内存在内核里的本质。
8)进程的页表和内核栈
进程的页表和内核栈,不属于内核的全局数据,而是附属于进程的局部数据。
内核在调度某个进程的时候,就把页目录基地址寄存器cr3和栈寄存器rsp切换成这个进程的页表和内核栈。
不同的进程之间,之所以有各自的虚拟内存空间,互相不干扰,就是因为每个进程的页表不一样。
要在进程之间共享内存,也跟线程之间共享内存一样,把同一个物理内存页映射到它们各自的页表就行。

















