













译者 | 朱先忠
审校 | 孙淑娟
工作区安全可能是公司中一种费力又费时的资金流失渠道,特别是对于处理敏感信息或拥有数千名员工的多个办公室的公司而言。电子钥匙是安全系统自动化的标准选择之一,但实际上,仍然存在诸如丢失、遗忘或伪造钥匙等不少缺点。
生物识别技术是传统安全措施的可靠替代品,因为它们代表了“你是什么”身份验证的概念。这意味着,用户可以使用他们独特的特征,如指纹、虹膜、声音或面部,来证明他们能够进入某个空间。使用生物特征作为身份验证方法可以确保密钥不会丢失、遗忘或伪造。因此,在本文中,我们将谈谈我们在边缘生物特征方面的开发经验,这是边缘设备、人工智能和生物特征的组合,以实现一个基于人工智能技术的安全监控系统。
什么是边缘生物特征?
首先,让我们来理清:什么是边缘AI?在传统的人工智能体系结构中,常见的做法是在云中部署模型和数据,与操作设备或硬件传感器分离。这迫使我们将云服务器保持在适当的状态,保持稳定的互联网连接,并为云服务付费。如果在互联网连接中断的情况下无法访问远程存储,那么,整个AI应用程序将变得毫无用处。
“相比之下,边缘AI的理念是在设备上部署人工智能应用程序,离用户更近。边缘设备可能有自己的GPU,允许我们在设备上就地处理输入。
这提供了许多优点,例如由于所有操作都是在本地设备上执行的,所以延迟减少,总体成本和功耗也变得更低。此外,由于设备可以轻松地从一个位置移动到另一个位置,因此整个系统更具便携性。
鉴于我们不需要大型生态系统,与依赖稳定互联网连接的传统安全系统相比,带宽需求也较低。边缘设备甚至可以在连接关闭的情况下运行,因为数据可以存储在设备的内部存储器中。这使得整个系统设计更加可靠和稳健。”
——丹尼尔·利亚多夫(MobiDev的Python工程师)
唯一值得注意的缺陷是,所有处理都必须在短时间内在设备上完成,硬件组件必须足够强大,并且必须是最新的,才能实现此功能。
对于人脸或语音识别等生物特征认证任务,安全系统的快速响应和可靠性至关重要。因为我们希望确保无缝的用户体验和适当的安全性,所以依靠边缘设备可以带来这些好处。
生物特征信息,如员工的脸和声音,似乎足够安全,因为它们代表了神经网络可以识别的独特模式。此外,这种类型的数据更容易收集,因为大多数企业在其CRM或ERP中已经有员工的照片。这样,你还可以通过收集你的员工的指纹样本来避免任何隐私问题。
结合边缘技术,我们可以为工作区入口创建灵活的AI安全摄像头系统。下面,我们将根据我们自己公司的开发经验,并借助边缘生物特征,来讨论如何实现这样的一个系统。
人工智能监控系统设计
该项目的主要目的是在办公室入口处对员工进行身份验证,只需看一眼摄像机即可。计算机视觉模型能够识别一个人的脸,将其与之前获得的照片进行比较,然后控制门的自动打开。作为一项额外措施,还将添加语音验证支持,以避免以任何方式欺骗系统。整个流水线由4个模型组成,它们分别负责执行从人脸检测到语音识别的各项不同任务。
所有这些措施都是通过一个用作视频/音频输入传感器的单一器件以及一个用于发送锁止/解锁命令的控制器来完成的。作为边缘设备,我们选择使用NVIDIA公司的Jetson Xavier。之所以作出这一选择,主要是因为此设备使用了GPU内存(这对于加速深入学习项目的推理至关重要),而且NVIDIA公司提供的Jetpack–SDK也高度可用——支持在基于Python3环境的设备上进行编码。因此,没有严格的必要将DS模型转换为另一种格式,几乎所有的代码库都可以由DS工程师根据设备进行调整;而且,也不需要从一种编程语言重写为另一种语言形式。
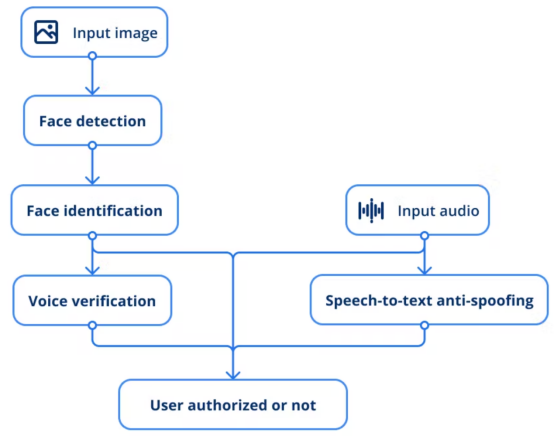
AI安全系统工作流程
根据上面的描述,整个过程遵循如下流程:
1. 将输入图像提供给人脸检测模型以查找用户。
2. 人脸识别模型通过提取向量并将其与现有员工照片进行比较来进行推断,以确定是否是同一个人。
3. 另一个模型是通过语音样本来验证特定人的语音。
4. 此外,采用语音到文本反欺骗方案以防止任何类型欺骗技术。
接下来,让我们讨论每一个实现环节,并详细说明训练和数据收集过程。
数据采集
在深入研究系统模块之前,一定要注意所使用的数据库。我们的系统依赖于为用户提供所谓的参考或基本事实数据。该数据目前包括每个用户的预计算人脸和语音矢量,看起来像一个数字数组。系统还存储成功登录的数据,以备日后重新训练使用。鉴于此,我们选择了最轻量级的解决方案SQLite DB。有了这个数据库,所有数据都存储在一个易于浏览和备份的文件中,而且数据科学工程师的学习时间更短。
因为面部识别需要所有可能进入办公室的员工的照片,所以我们使用存储在公司数据库中的面部照片。当人们使用面部验证来开门时,放置在办公室门口的Jetson设备也收集了面部数据样本。
最初语音数据不可用,所以我们组织采集数据,要求人们录制20秒的片段。然后,我们使用语音验证模型来获取每个人的矢量,并将其存储在数据库中。你可以使用任何音频输入设备采集语音样本。在我们的项目中,我们使用便携手机和内置麦克风的网络摄像头来录制声音。
面部检测
人脸检测可以确定给定场景中是否存在人脸的问题。如果有,模型应该给出每个面部的坐标,以便您知道每个脸在图像上的位置,包括面部标志。此信息很重要,因为我们需要在边界框中接收一个面部,以便在下一步中运行人脸识别。
对于人脸检测,我们使用了RetinaFace模型和InsightFace项目中的MobileNet关键组件。该模型输出图像上每个检测到的人脸的四个坐标以及5个人脸标记。事实上,以不同角度或使用不同光学元件拍摄的图像可能会因变形而改变面部的比例。这可能会导致模型难以识别此人。
为了满足这一需求,面部标志被用来进行变形,这是一种减少同一个人的这些图像之间可能存在的差异的技术。因此,获得的裁剪面和扭曲面看起来更相似,提取的脸向量也更准确。
面部识别
下一步是人脸识别。在这个阶段,模型必须从给定的图像(即获得的图像)中识别出人。识别是在参考(地面真实数据)的帮助下完成的。因此,在这里,模型将通过测量两个向量之间差异的距离分数来比较两个向量,以判断站在相机前的是不是同一个人。该评估算法将与我们所拥有的一名员工的初始照片进行比较。
人脸识别是使用SE-ResNet-50架构的模型完成的。为了使模型结果更加稳健,在获得人脸矢量输入之前,图像将被翻转一下来进行平均化处理。此时,用户标识流程如下:
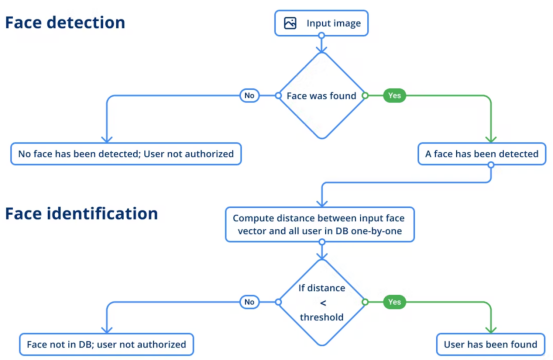
人脸和语音验证流程
语音验证
接下来,我们转到语音验证环节。此步骤应该完成验证两个音频是否包含同一个人的声音。你可能会问,为什么不考虑语音识别呢?答案是,现在面部识别的效果比语音好得多,图像比语音能提供更多的信息来识别用户。为了避免出现通过面部识别用户A而通过语音识别用户B,系统只采用了面部识别方案。
基本逻辑与人脸识别阶段几乎相同,因为我们通过向量之间的距离来比较两个向量,除非我们找到相似的向量。唯一的区别是,我们已经有了一个关于谁是试图从前面的人脸识别模块中通过的人的假设。
在语音验证模块的积极开发过程中,出现了许多问题。
之前采用Jasper架构的型号无法验证同一个人从不同话筒上录制的录音。因此,我们通过使用ECAPA-TDNN架构解决了这个问题,该架构在SpeechBrain框架的VoxCeleb2数据集上进行了训练,它在验证员工方面做得更好。
然而,音频片段仍然需要一些预处理。目的是通过保留声音和减少当前背景噪音来提高音频录制质量。然而,所有测试技术都严重影响了语音验证模型的质量。很可能,即使是最轻微的降噪也会改变录音中的语音音频特性,因此模型将无法正确验证此人。
此外,我们还调查了音频录制的长度以及用户应该发音多少个单词。作为这次调查的结果,我们提出了一些建议。结论是:这种录音的持续时间应至少为3秒,需要朗读大约8个单词。
语音到文本反欺骗
最后一个安全方面的措施是,系统应用了Nemo框架中基于QuartzNet构建的语音到文本反欺骗。该模型提供了良好的用户体验,适用于实时场景。要衡量一个人所说的与系统期望的接近程度,需要计算他们之间的Levenshtein距离。
获取员工的照片以欺骗面部验证模块是一项可以实现的任务,同时还可以录制语音样本。语音到文本反欺骗不包括入侵者试图使用授权人员的照片和音频进入办公室的场景。这个想法很简单:当每个人验证自己时,他们会说出系统给出的短语。短语由一组随机选择的单词组成。虽然短语中的单词数量并不多,但实际可能的组合数量是相当巨大的。应用随机生成的短语,我们消除了欺骗系统的可能性,因为它需要授权用户说出大量录制的短语。拥有一张用户的照片不足以欺骗具有此保护的AI安全系统。
边缘生物特征识别系统的优点
此时,我们的边缘生物识别系统让用户遵循一个简单的操作流程,这需要他们说出一个随机生成的短语来解锁门。此外,通过人脸检测,我们为办公室入口提供人工智能监控服务。
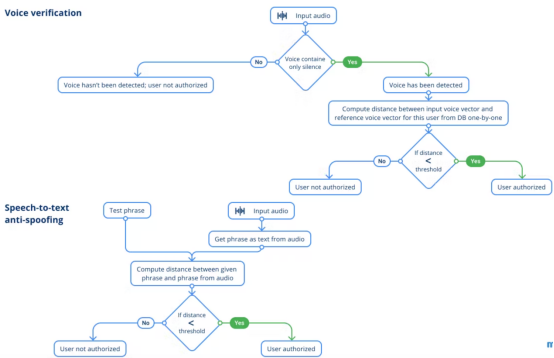
语音验证和语音到文本反欺骗模块
“通过添加多个边缘设备,系统经轻松修改即可扩展应用到不同的场景中。与普通计算机相比,我们可以通过网络直接配置Jetson,通过GPIO接口与低级设备建立连接,并很容易用新硬件进行升级。我们还可以与任何具有web API的数字安全系统集成。
但此方案的主要好处在于,我们可以直接从设备收集数据来改进系统,因为在入口处收集数据似乎非常方便,不存在任何特定的中断。”
——丹尼尔·利亚多夫(MobiDev的Python工程师)
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Developing AI Security Systems With Edge Biometrics,作者:Dmitriy Kisil




















