Table Index
前面介绍完了 Hash Table,在数据库系统中,它可以用于一些 sql 执行时的临时数据结构,或者用来存储一些元数据信息,也可以作为表的 Hash 索引,但是对于表索引,在更通用的场景下, B+ 树是更广泛的选择。
表索引(Index)指的是表中数据的一些子集,这些子集能够标识表中数据的一些特征,以便能够快速的去查找 table 中的数据,并且数据库能够保证,表中数据和表索引数据的一致性。
B+ Tree 基本概念
B+ Tree 实际上是一种平衡树结构,它能够保证数据有序存储,可以在平均 O(log n) 复杂度下查询、插入、删除数据。
它实际上类似二叉平衡树,但是每个节点可以拥有不止 2 个子节点,并且能够适配数据库需要读取整块数据的需求,提升数据读写的效率。
B+ 树是一个多叉平衡树,例如 M 个分叉指的是每个 inner node 都有 M 个路径到子节点,具有以下基本特征:
- 完全平衡的树结构,即所有子节点到根节点的距离始终保持一致
- 除根节点外,每个节点的数据量至少大于 M 的一半,即 M/2-1 <= #keys <= M-1
- 每一个具有 k 个 key 的节点内,都有 k+1 个指向子节点的指针
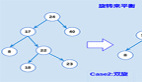
下图所示,是一个 B+ Tree 的例子。

最底层的节点叫做 leaf node 叶子节点,上层的叫做 inner node,最顶层的 inner node 就是根节点(root node)。
inner node 中不会存储实际的数据,而是存储 key 以及指向其子节点的指针。
叶子节点之间有指针串联,方便进行 scan 操作;每个叶子节点中存储了实际的 key/value 数据。
叶子节点的内部结构,一般有两种不同的布局方式,一种是很常见的,存储一个 page id,并且将索引的 key 和 value 都存放到节点中,然后一个 page 指向下一个 page。

这样是将 key/value 保存在了一起,并不利于顺序扫描,如果我们只需要扫描 key 的话,那么会有一些额外的消耗。
另一种方式是将 key 和 value 分开,结构大致如下所示:

其中包含了一些元数据信息,例如当前的层数,空闲空间等,以及一个有序的 key 列表,并且每一个 key 指向了它自己的 value。
而实际 value 所表示的数据,各个系统有不同的实现,大致有两种:一是存储一个记录 id,指向磁盘的 page 中数据的实际位置;二是直接就存储数据本身。
B+ Tree 操作
insert
B+ 树中插入操作大致流程如下:
- 首先从根节点开始,通过 inner node 的指针,层层往下找到对应的叶子节点 L
- 将数据存储到叶子节点中
- 如果节点 L 中还有空闲空间,则操作完成
- 否则,分裂(split)该叶子节点
重新分布该叶子节点上的数据,以最中间的 key 为界,右边的数据分裂到新的节点中
分裂的时候,需要将叶子节点中间的 key 推送到上层父节点
如果上层父节点又需要分裂,则重复执行上述过程
delete
delete 操作大致是和 insert 相反的,插入的时候,如果一个节点上的数据满了,则需要分裂;而删除时,如果一个节点中的数据少于了 M/2-1,则破坏了 B+ Tree 的定义,这时候需要将节点进行合并,称为 merge。
大致过程如下:
- 通过 inner node 节点找到对应的叶子节点 L
- 在 L 中找到对应的数据并删除
- 如果叶子节点中的数据大于等于 M/2-1,则完成
- 否则,需要进行 merge 合并节点
尝试重分布,如果邻近节点有富余,则从邻近的节点中拿一个 key
如果邻近节点也没有多余的数据,则尝试和兄弟节点合并
这里有一个网站,动态展示了 B+ 树的插入、删除、查找过程,能够更好帮你理解 B+ 树。https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html

B+ Tree Design
接下来在简要分析下关于 B+ Tree 的一些设计问题。
Node Size
对于 B+ 树中每个节点的大小,这其实并不确定,或者说依赖于硬件环境和数据库类型,sql 查询类型等因素。
大致来说,存储介质速度越慢,则一个节点的容量就越大,道理也很简单。当在慢速的介质中,例如磁盘,我么肯定希望能够一次性多读取一部分数据到内存中,尽量避免多次随机 IO。在越快速的设备上,则节点的容量越小。
可以参考内存中的 cache line 和操作系统维护的 page size。MySQL 的 B+ 树节点大小一般是 16KB。
Merge Threshold
前面说到了删除数据时可能会触发 B+ 树的 merge 节点操作,但是在实际的实现中,一些数据库系统并不是只要满足条件就会马上执行,而是累积到一段时间之后,再进行 merge。
因为 merge 是一个很“昂贵”的操作,涉及到磁盘上的数据调整分布,一些系统中会有一些后台进程,定期去触发这个操作。
Variable-Length Keys
前面提到的 B+ Tree 中存储的都是固定 size 的 key,但是实际环境中,我们的 key 或者 value 都有可能是不定长的。针对不定长的 key,一般有这几种解决办法:
1.节点中不存储实际的 key,而是存储指向实际 tuple 属性的指针,这样的话虽然能够固定大小,但是指针并没有 key 本身具有的特征,范围扫描低效,实际使用并不多。
2.节点的 size 也不固定,来适配不同长度的 key
- 这种方式需要更加精细化的内存管理,并且在 buffer pool 中也需要适配(buffer pool 的 size 通常是固定的),所以实际使用也不多。
3.对齐,总是将 key 对齐为其类型的大小,而不管 key 的 size 有多大。这种方式缺点也显而易见,就是可能会浪费一定的空间。
4.使用类似 slot page 的组织方式,将 key 存在一个有序的集合中,并且指向其实际的数据。

Non-Unique Index
数据库中的索引,有时候可以存在重复的数据,除了唯一索引外。因此,在 B+ Tree 存储数据的时候,需要对重复的 key 进行处理。
Duplicate Keys
存储重复 key 很好理解,就是我们可以把重复的 key 也当做是一个单独的 key 进行存储即可。
Va

lue List
value list 就是对重复 key 的 value 维护了一个链表,将其串联起来。
B+ Tree Optimizations
最后再来看下关于 B+ 树在设计时的一些优化方案。
Prefix Compression
因为 B+ 树底层叶子节点的数据是有序排列的,因此存储在同一个叶子节点的数据,有很大可能是具有相同的特征的,例如可能是类似的,拥有相同的前缀。
所以,针对那些有相同前缀的数据,可以只存储一份前缀数据,而不用每个 key 都单独存储一份。

Suffix Truncation
前面提到过 B+ 树中 inner node 只存储了 key 和索引信息,并不存储数据,只是做为一个辅助查找的索引节点。因此 inner node 中的 key 并不用是完整的 key,只要能够起到区分查找的作用就可以了。

例如上面的例子,由于这两个 key 所有字符都不一致,因此并不需要存储完整的 key,只需要存储能够帮助查找到下一级节点的信息就可以了。

Bulk Insert
最好的构建 B+ 树的方式,是将一组有序的数据从下到上构建 B+ 树的多级索引,这样不会存在 B+ 树的分裂或者合并,效率是最高的。
因此如果有一部分初始化数据需要插入到 B+ 树中,可以先将其排序,然后直接构建 B+ 树。
Pointer Swizzling
B+ 树遍历 page 的时候,每次都需要从 buffer pool 中获取 page 的位置信息,然后 B+ 树根据这个位置去获取 Buffer Pool 中的 page 数据。

例如上图中,需要获取 page id 为 2 的 page,则会先从 page table 中获取,Buffer Pool 判断这个 page 是否在内存中,如果不在则加载这个 page 到内存,并且返回一个 page 的指针(page 的实际位置)给 B+ 树。
如果 B+ 树确认扫描到的 page 肯定在内存中,那么可以直接存储 page 指针,省去了从 page table 中寻址的开销。

这个优化比较适用于 B+ 树的上层节点,因为 B+ 树上面的几层节点容量相对较小,并且会被频繁的访问到,可以缓存到内存中加速 B+ 树的查询。
Conclusion
这一节讲述了 B+ 树的一些基本概念,相信读者能够对其有一个基本的理解了,在大多数情况下,B+ 树是一个在数据库中应用非常广泛的结构。