目前,Transformers 已经成为序列建模的强大神经网络架构。预训练 transformer 的一个显著特性是它们有能力通过提示 conditioning 或上下文学习来适应下游任务。经过大型离线数据集上的预训练之后,大规模 transformers 已被证明可以高效地泛化到文本补全、语言理解和图像生成方面的下游任务。
最近的工作表明,transformers 还可以通过将离线强化学习(RL)视作顺序预测问题,进而从离线数据中学习策略。Chen et al. (2021)的工作表明,transformers 可以通过模仿学习从离线 RL 数据中学习单任务策略,随后的工作表明 transformers 可以在同领域和跨领域设置中提取多任务策略。这些工作都展示了提取通用多任务策略的范式,即首先收集大规模和多样化的环境交互数据集,然后通过顺序建模从数据中提取策略。这类通过模仿学习从离线 RL 数据中学习策略的方法被称为离线策略蒸馏(Offline Policy Distillation)或策略蒸馏(Policy Distillation, PD)。
PD 具有简单性和可扩展性,但它的一大缺点是生成的策略不会在与环境的额外交互中逐步改进。举例而言,谷歌的通才智能体 Multi-Game Decision Transformers 学习了一个可以玩很多 Atari 游戏的返回条件式(return-conditioned)策略,而 DeepMind 的通才智能体 Gato 通过上下文任务推理来学习一个解决多样化环境中任务的策略。遗憾的是,这两个智能体都不能通过试错来提升上下文中的策略。因此 PD 方法学习的是策略而不是强化学习算法。
在近日 DeepMind 的一篇论文中,研究者假设 PD 没能通过试错得到改进的原因是它训练用的数据无法显示学习进度。当前方法要么从不含学习的数据中学习策略(例如通过蒸馏固定专家策略),要么从包含学习的数据中学习策略(例如 RL 智能体的重放缓冲区),但后者的上下文大小(太小)无法捕获策略改进。

论文地址:https://arxiv.org/pdf/2210.14215.pdf
研究者的主要观察结果是,RL 算法训练中学习的顺序性在原则上可以将强化学习本身建模为一个因果序列预测问题。具体地,如果一个 transformer 的上下文足够长,包含了由学习更新带来的策略改进,那么它不仅应该可以表示一个固定策略,而且能够通过关注之前 episodes 的状态、动作和奖励来表示一个策略改进算子。这样开启了一种可能性,即任何 RL 算法都可以通过模仿学习蒸馏成足够强大的序列模型如 transformer,并将这些模型转换为上下文 RL 算法。
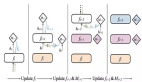
研究者提出了算法蒸馏(Algorithm Distillation, AD),这是一种通过优化 RL 算法学习历史中因果序列预测损失来学习上下文策略改进算子的方法。如下图 1 所示,AD 由两部分组成。首先通过保存 RL 算法在大量单独任务上的训练历史来生成大型多任务数据集,然后 transformer 模型通过将前面的学习历史用作其上下文来对动作进行因果建模。由于策略在源 RL 算法的训练过程中持续改进,因此 AD 不得不学习改进算子以便准确地建模训练历史中任何给定点的动作。至关重要的一点是,transformer 上下文必须足够大(即 across-episodic)才能捕获训练数据的改进。

研究者表示,通过使用足够大上下文的因果 transformer 来模仿基于梯度的 RL 算法,AD 完全可以在上下文中强化新任务学习。研究者在很多需要探索的部分可观察环境中评估了 AD,包括来自 DMLab 的基于像素的 Watermaze,结果表明 AD 能够进行上下文探索、时序信度分配和泛化。此外,AD 学习到的算法比生成 transformer 训练源数据的算法更加高效。
最后值得关注的是,AD 是首个通过对具有模仿损失的离线数据进行顺序建模以展示上下文强化学习的方法。

方法
在生命周期内,强化学习智能体需要在执行复杂的动作方面表现良好。对智能体而言,不管它所处的环境、内部结构和执行情况如何,都可以被视为是在过去经验的基础上完成的。可用如下形式表示:

研究者同时将「长期历史条件, long history-conditioned」策略看作一种算法,得出:

其中∆(A)表示动作空间 A 上的概率分布空间。公式 (3) 表明,该算法可以在环境中展开,以生成观察、奖励和动作序列。为了简单起见,该研究将算法用 P 表示,将环境(即任务)用 的学习历史都是由算法
的学习历史都是由算法 表示,这样对于任何给定任务
表示,这样对于任何给定任务 生成的。可以得到
生成的。可以得到

研究者用大写拉丁字母表示随机变量,例如 O、A、R 及其对应的小写形式 o,α,r。通过将算法视为长期历史条件策略,他们假设任何生成学习历史的算法都可以通过对动作执行行为克隆来转换成神经网络。接下来,该研究提出了一种方法,该方法提供了智能体在生命周期内学习具有行为克隆的序列模型,以将长期历史映射到动作分布。
实际执行
在实践中,该研究将算法蒸馏过程 ( algorithm distillation ,AD)实现为一个两步过程。首先,通过在许多不同的任务上运行单独的基于梯度的 RL 算法来收集学习历史数据集。接下来,训练具有多情节上下文的序列模型来预测历史中的动作。具体算法如下所示:

实验
实验要求所使用的环境都支持许多任务,而这些任务不能从观察中轻易的进行推断,并且情节(episodes)足够短,可以有效地训练跨情节因果 transformers。这项工作的主要目的是调查相对于先前工作,AD 强化在多大程度上是在上下文中学习的。实验将 AD、 ED( Expert Distillation) 、RL^2 等进行了比较。
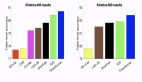
评估 AD、ED、 RL^2 结果如图 3 所示。该研究发现 AD 和 RL^2 都可以在上下文中学习从训练分布中采样的任务,而 ED 则不能,尽管 ED 在分布内评估时确实比随机猜测做得更好。

围绕下图 4,研究者回答了一系列问题。AD 是否表现出上下文强化学习?结果表明 AD 上下文强化学习在所有环境中都能学习,相比之下,ED 在大多数情况下都无法在上下文中探索和学习。
AD 能从基于像素的观察中学习吗?结果表明 AD 通过上下文 RL 最大化了情景回归,而 ED 则不能学习。
AD 是否可以学习一种比生成源数据的算法更有效的 RL 算法?结果表明 AD 的数据效率明显高于源算法(A3C 和 DQN)。

是否可以通过演示来加速 AD?为了回答这个问题,该研究保留测试集数据中沿源算法历史的不同点采样策略,然后,使用此策略数据预先填充 AD 和 ED 的上下文,并在 Dark Room 的环境中运行这两种方法,将结果绘制在图 5 中。虽然 ED 保持了输入策略的性能,AD 在上下文中改进每个策略,直到它接近最优。重要的是,输入策略越优化,AD 改进它的速度就越快,直到达到最优。

更多细节,请参考原论文。