












- 1 什么是对比学习
- 1.1 对比学习的定义
- 1.2 对比学习的原理
- 1.3 经典对比学习算法系列
- 2 对比学习的应用
- 3 对比学习在转转的实践
- 3.1 CL在推荐召回的实践
- 3.2 CL在转转的未来规划
1 什么是对比学习
1.1 对比学习的定义
对比学习(Contrastive Learning, CL)是近年来 AI 领域的热门研究方向,吸引了众多研究学者的关注,其所属的自监督学习方式,更是在 ICLR 2020 被 Bengio 和 LeCun 等大佬点名称为 AI 的未来,后陆续登陆 NIPS, ACL, KDD, CIKM 等各大顶会,Google, Facebook, DeepMind,阿里、腾讯、字节等大厂也纷纷对其投入精力,CL 的相关工作也是刷爆了 CV,乃至 NLP 部分问题的 SOTA,在 AI 圈的风头可谓一时无两。
CL 的技术源泉来自度量学习,大概的思想是:定义好样本的正例和负例,以及映射关系(将实体映射到新的空间),优化目标是让正例在空间中与目标样本的距离近一些,而负例要相对远一些。正因为如此,CL 看上去跟向量化召回思路很像,但其实二者有本质的区别,向量化召回属于监督学习的一种,会有明确的标签数据,而且更注重的负样本的选择(素有负样本为王的“学说”);而 CL 是自监督学习(属于无监督学习的一种范式)的一支,不需要人工标注的标签信息,直接利用数据本身作为监督信息,学习样本数据的特征表达,进而引用于下游任务。此外,CL 的核心技术是数据增强(Data Augmentation),更加注重的是如何构造正样本。下图是一个抽象的 CL 整体流程图

对比学习的标签信息来源于数据本身,核心模块是数据增强。图像领域的数据增强技术是比较直观的,比如图像的旋转、遮挡、取部分、着色、模糊等操作,都可以得到一张与原图整体相似但局部相异的新图(即增强出来的新图),下图是部分图像数据增强的手段(出自SimCLR[1])。

1.2 对比学习的原理
谈到CL的原理,不得不提自监督学习,它避开了人工标注的高成本,以及标签低覆盖的稀疏性,更容易学到通用的特征表示。自监督学习可以分成两大类:生成式方法和对比式方法。生成式方法的典型代表是自编码器,而对比式学习的经典代表即ICLR 2020的SimCLR,通过(增强后的)正负样本在特征空间的对比学习特征表示。相比较生成式方法,对比式方法的优势在于无需对样本进行像素级的重构,只需要在特征空间能够学到可区分性即可,这使得相关的优化变得简单。笔者认为,CL的有效性主要体现在学习item表示的可区分性,而可区分性的学习依赖正负样本的构造思路,以及具体的模型结构和优化目标。
结合CL的实现过程,Dr Zhang[2]抽象了三个CL必须要回答的问题,也是其区别于度量学习的典型特征,即(1)如何构造正例和负例,也就是数据增强具体是如何实现的;(2)Encoder映射函数如何构造,不仅要尽可能多地保留原始信息,而且要防止坍塌问题;(3)损失函数如何设计,目前通常使用的NCE loss,如下公式所示。不难看出,这三个基本问题对应建模的三要素:样本,模型,优化算法。
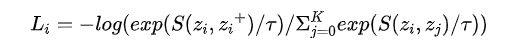
从 loss 公式中可以看出,分子部分强调的是与正例的距离越近越好,S函数衡量的是相似性,距离越近对应的S值越大,分母强调的是与负例的距离越远越好,loss 越低,对应的可区分性越高。
在这三个基本问题中,数据增强是 CL 算法的核心创新点,不同的增强手段是算法有效性的基本保障,也是各大 CL 算法的identity;Encoder函数通常借助神经网络实现;除 NCE loss外,还有其他 loss 的变体,比如Google[3]就提出了监督对比损失。
1.3 经典对比学习算法系列
CL是自监督学习的一种学习算法,提到自监督学习,Bert 恐怕是 NLP 领域无法回避的话题,Bert 预训练 + Fine-tuning 的模式在诸多问题的解决方案中实现了突破,既然自监督可以在 NLP 取得成功,难道计算机视觉就不可以吗?实际上 Bert 在 NLP 领域取得的成功,也直接地刺激了 CL 在图像领域的发生和发展。鉴于数据增强可以在图像领域直观地展开,CL 也是率先在 CV 领域取得进展,比如 CL 的发展契机—— SimCLR 算法,其创新点主要包括(1)探索了多种不同的数据增强技术的组合,选择了最优;(2)在 Encoder 之后增加了非线性映射 Projector,主要是考虑 Encoder 学习的向量表示会把增强的信息包含在内,而 Projector 则旨在去除这部分影响,回归数据的本质。后来Hinton的学生在 SimCLR 的基础上实现了 SimCLR v2,主要改进点在于 Encoder 的网络结构,同时借鉴了 MoCo 使用的 Memory Bank 的思想,进一步提升了 SOTA。
实际上,在 SimCLR 之前,Kaiming He 在2019年底提出了对比学习的另一个经典算法MoCo[4],其主要思想是既然对比是在正负样本之间进行的,那么增加负样本数量,可以提高学习任务的难度,从而增强模型性能,Memory Bank 是解决该问题的经典思路,但却无法避免表示不一致的问题,鉴于此,MoCo 算法提出了使用动量的方式更新 Encoder 参数,从而解决新旧候选样本编码不一致的问题。后来,Kaiming He 又在 MoCo 的基础上提出了 MoCo v2(在 SimCLR 提出之后),模型主要框架没有改动,主要在数据增强的方法、Encoder 结构以及学习率等细节问题上做了优化。
2 对比学习的应用
对比学习不仅是学术界在图像、文本、多模态等多个领域的热门研究方向,同时也在以推荐系统为代表的工业界得到了应用。
Google 将 CL 应用于推荐系统Google SSL[5],目的在于针对冷门、小众的 item 也能学习到高质量的向量表示,从而辅助解决推荐冷启动问题。其数据增强技术主要采用 Random Feature Masking(RFM),Correlated Feature Masking(CFM)的方法(CFM 一定程度上解决了 RFM 可能构造出无效变体的问题),进而 CL 以辅助塔的形式,结合双塔召回的主任务共同训练,整体流程如下图所示

在模型的训练过程中,主任务的 item 主要还是来自曝光日志,因此也是对头部热门 item 比较友好,为了消除马太效应的影响,在辅助任务中的样本构造需要考虑与主任务不同的分布,后续 CL 在转转的实践过程中也是借鉴了这样的思考,从而确保模型学习结果的充分覆盖。
数据增强不局限在 item 侧,Alibaba-Seq2seq[6]将 CL 的思想应用在序列推荐问题上,即输入用户行为序列,预测下一个可能交互的 item。具体地,其数据增强主要应用在用户行为序列特征,将用户历史行为序列按照时序划分成两个子序列,作为数据增强后的用户的表示,喂入双塔模型,最终输出结果越相似越好。与此同时,该文为了显式建模用户的多兴趣,在 Encoder 部分提取出多个向量,而不是压缩成一个用户向量。因为随着子序列的拆分,以及正负例的构造,用户天然具有多个行为序列的向量表示,在正例中,用户前一部分历史行为的向量,与后一部分历史行为的向量,距离相近,而在负例中,不同用户的距离相对较远,而且即使同一用户,在不同类别商品的向量表示也相对较远。
CL 还可以与其他学习范式结合应用,图对比学习[7],整体框架如下图所示

GCL 通常通过随机删除图中的点或者边,实现图数据的增强,而本文的作者倾向于保持重要的结构和属性不变,扰动发生在不重要的边或者节点。
3 对比学习在转转的实践
图像领域取得了成功,文本领域也是可以的,比如美团-ConSERT[8]算法,在句子语义匹配任务的实验中,相比之前的 SOTA(BERT-flow)提升了8%,并且在少量样本下仍能表现出较好的性能提升。该算法将数据增强作用在 Embedding 层,采用隐式生成增强样本的方法,具体地,提出了四种数据增强方法:对抗攻击(Adversarial Attack),打乱词序(Token Shuffling),裁剪(Cutoff)和 Dropout,这四种方法均通过调整 Embedding 矩阵得到,比显式增强方法更高效。
3.1 CL在推荐召回的实践
转转平台致力于促进低碳循环经济的更好发展,能够覆盖全品类商品,近年来尤其在手机3C领域的发展表现突出。CL 在转转推荐系统中的实践也是选择了基于文本的应用思路,考虑到二手交易特有的属性,需要解决的问题包括(1)二手商品的孤品属性,导致 ID 类的向量并不适用;(2)数据增强是怎么实现的;(3)正例和负例如何构造;(4)Encoder 的模型结构是怎样的(包括 loss 的设计问题)。针对这四个问题,结合下面的整体流程图进行详细说明
针对二手商品的孤品属性问题,我们采用基于文本的向量作为商品的表征,具体地,使用商品的文本描述(包括标题与内容)集合,训练 word2vec 模型,并基于词向量通过 pooling 得到商品的向量表示。
自编码器(Auto Encoder)算法是文本对比学习领域常用的数据增强手段之一(除此之外,还有机器翻译、CBERT等不同思路),我们也是采用 AE 算法训练模型,学习商品向量,并利用算法的中间向量作为商品的增强向量表示,也就有了正例。
负例的生产原则是 Batch 内随机选取不相似的商品,相似商品的判断依据是根据用户的后验点击行为计算而来。在以 CF(协同过滤)为代表的推荐系统召回结果中,能够通过共同点击行为召回的商品组合,认为是相似的,否则认为是不相似的。之所以采用行为依据判断是否相似,一方面是为了将用户的行为引入其中,实现文本与行为的有机结合,另一方面也是为了尽可能地贴合业务目标。
具体到 Encoder 部分,我们采用的是类似孪生网络的双塔结构,分别喂入样本(正正 or 正负)的文本向量,训练分类模型,网络结构为三层全连接的神经网络,双塔共享该网络参数,并通过优化交叉熵损失优化模型参数。实际工业界,大部分推荐系统中双塔模型的训练目标均为用户后验行为(点击、收藏、下单等),而我们的训练目标是样本相似与否,之所以采用孪生网络的形式,也是出于这样做可以保证学习结果的覆盖。
根据 CL 的常规思路,提取最终 Encoder 部分的输入向量作为商品的向量化表示,可以进一步在推荐系统的召回、粗排甚至精排等环节应用。目前已经在转转推荐系统的召回模块落地,给线上带来了超过10%的下单提袋率的提升。
3.2 CL在转转的未来规划
通过人工评估以及线上AB实验,充分确认了CL习得向量表示的有效性,在召回模块落地后,可以在推荐系统其他模块,甚至其他算法场景推而广之。以预训练的方式学习商品向量表示(当然,也可以学习用户的向量表示),只是一条应用路径,CL 更多的是提供了一种学习框架或者学习思路,通过数据增强和对比的形式,使算法学习物品的可区分性,这样的思路可以自然地引入推荐系统的排序模块,因为排序问题也可以理解成物品的可区分性问题。
关于作者
李光明,资深算法工程师。参与转转搜索算法、推荐算法、用户画像等系统的算法体系建设,在GNN、小样本学习、对比学习等相关领域有实践应用。
参考资料
[1]SimCLR: A_Simple_Framework_for_Contrastive_Learning_of_Visual_Representations
[2]张俊林: https://mp.weixin.qq.com/s/2Js8-YwUEa1Hr_ZYx3bF_A
[3]Google: Supervised_Contrastive_Learning
[4]MoCo: Momentum_Contrast_for_Unsupervised_Visual_Representation_Learning
[5]SSL: Self-supervised_Learning_for_Large-scale_Item_Recommendations
[6]Ali-Seq2seq: Disentangled_Self-Supervision_in_Sequential_Recommenders
[7]GCL: Graph_contrastive_learning_with_adaptive_augmentation
[8]ConSERT: ConSERT:_A_Contrastive_Framework_for_Self-Supervised_Sentence_Representation_Transfer































